3D人体重建
Contents
图像重建
图像重建:通过物体外部测量的数据,经数字处理获得三维物体的形状信息的技术。
SMPL模型
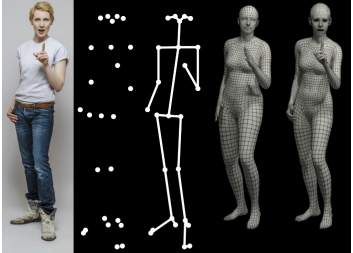
它是通过输入一张RGB 的人体图像和由openpose(openpose可以获取人体各个骨骼关键点位置)检测出的人体关键点来重建人体的三维模型。
使用openpose检测一张RGB图像上得人体骨骼关键点;使用smpl模型去拟合第1步检测出的关键点数据。
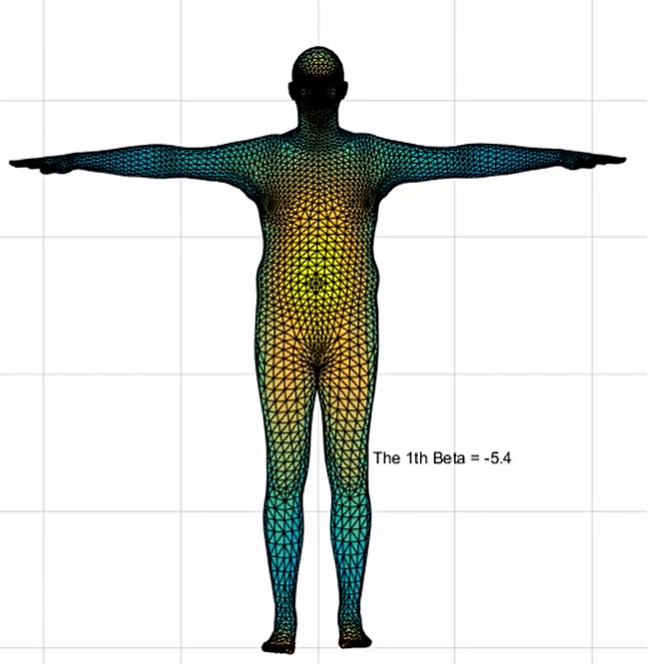
SMPL模型使用85维的向量来表示。其中包含人体关键点信息72维,体型信息10维,摄像机位置参数3维。输出是3Dmesh(三维身体网络),包括6980个顶点,13776个面元。(由点连接成的三角形平面)
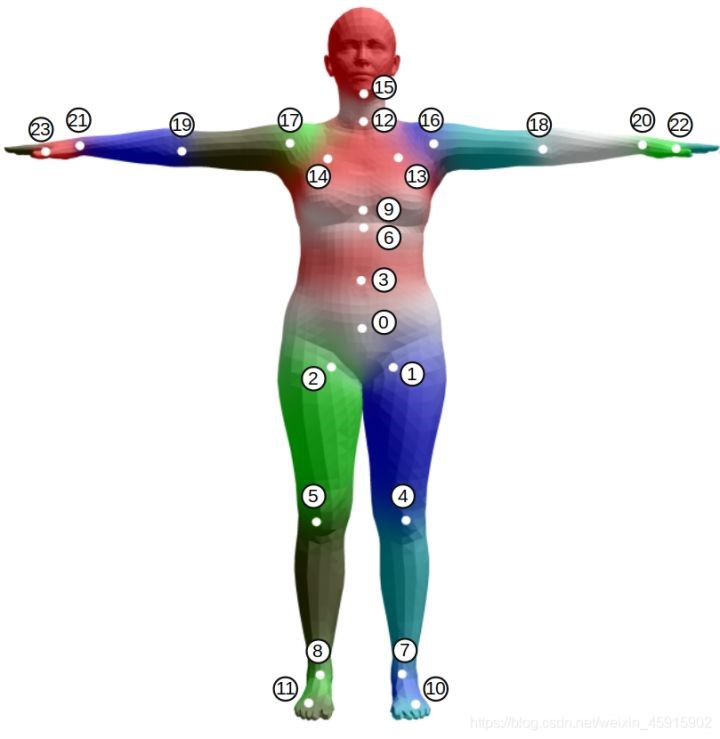
人体关键点:24个,每个关键点信息由三个数字(yaw,roll,pitch)组成,共72维,用θ表示。其中三个每个点的三个数字表示的是肢体旋转的三个角度(yaw,roll,pitch),而不是坐标。
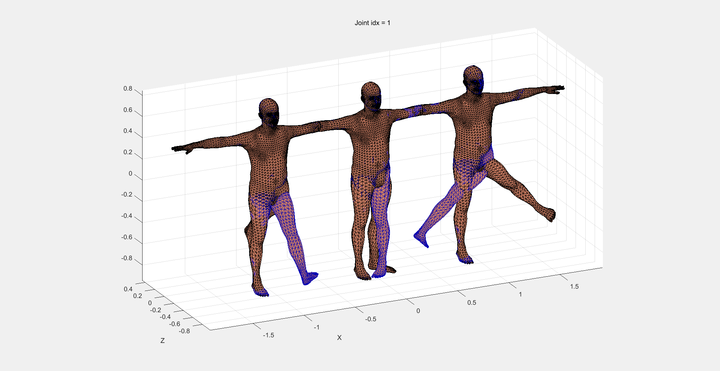
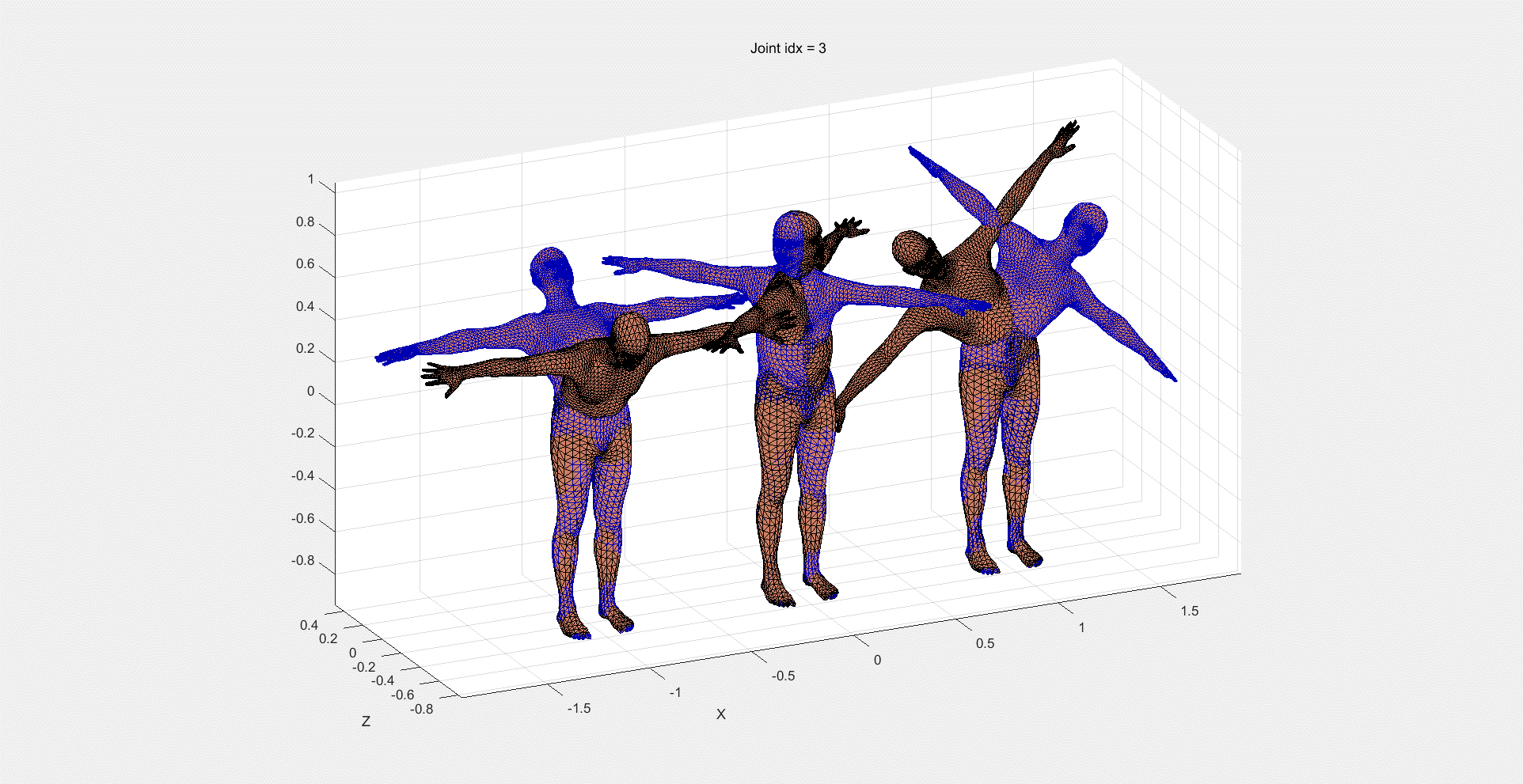
体型信息:SMPL预设了很多种体型,并通过10个数字的组合去选择不同的体型来拟合图像的的任务,用β表示。
SMPL-X模型
Smpl-x的输入参数共119个,其中75个人体关键点信息((24+1)*3),24个手部动作信息(经过PCA降维,原本应该是90个),10个体型信息,10个表情信息。
整个重建的流程可以由一个数学公式来表达,就可以表示为:
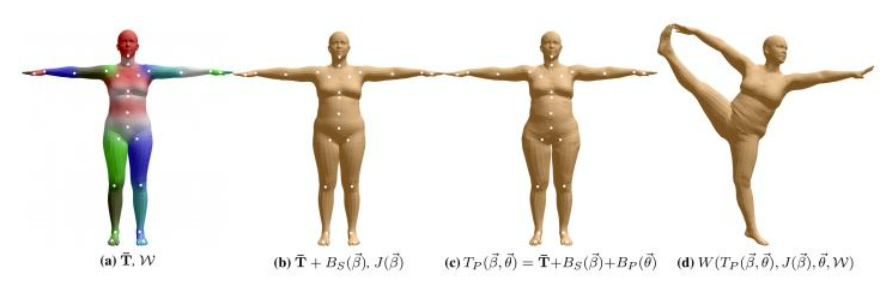
M(β,θ,ψ)=W(T_p (β,θ,ψ),J(β),θ,ω)
M中:θ表示动作参数,每个参数表示相对于父节点的旋转关系(yaw,roll,pitch), K+1是因为除了smpl的K个关键点,还有一个用于控制整个身体的旋转。其中θ可以分为三类:θf是脸部的关键点,θh是手指的关键点手指的关节点,θb是肢体上的关键点。另外,β参数用来表示人的体型,ψ参数用来表示面部表情。整个操作的意义就是输入以上三种参数,最终输出人体3d模型表面上每一个顶点的坐标。
T_p (β,θ,ψ)=T ̅+B_s (β;s)+B_E (ψ;ε)+B_P (θ;p)
T_P:在平均模型的基础上分别经过体型动作和表情参数修正之后的人体模型
B_s,B_E,B_P分别代表了体型,表情和动作参数计算出的在平均模型上的修正数据。
T ̅是预设好的人体模型
T ̅+B_s(β;s)+B_E (ψ;ε)表示依据体型和表情参数去修改人体模型,将模型的外观依照参数去形变成需要的样子,再加上B_P (θ;p)并不是在此时就给模型加上参数所示的动作,而是在预设的动作上依据将要做出的动作再次改变形体。
例如一个比较胖的人,腹部有赘肉,那么在下腰这个动作时腹部的赘肉就会层叠起来,T ̅+B_s (β;S)+B_E (ψ;ε)就是将模型的体型修正为偏胖,B_P (θ;p)来进行修正下腰的时候腹部的赘肉的层叠,以上操作都是在改变模型的体型,均没有改变模型的动作。
J表示从模型的表面顶点获取每个关键点的坐标。
最终,就是将修正好的形体在关键点处进行旋转再辅以形变权重ω,这样带带有动作的人体模型就出来了。
全身先验
人的膝盖和肘部弯曲只能像同一个方向,所以应该进行一个简单先验。在数据θ中只能向负方向弯曲,若θ为正,就会让整个公式变大,由此给予惩罚。
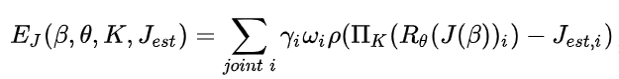
表示一个重投影损失。π_K表示按照摄影机的位置将每个关键点的三维坐标投影到二维,再减去openpose预测出的每个关键点的二维坐标 J_est。ρ表示一个鲁棒Geman-MuClure误差方程,常用于图像匹配。这里用来比对openpose和预测关键位置的偏差,来检验这个模型。
SMPL-X使用了变分自编码器VAE训练了一个全身的先验Vposer。Vposer学习了一个潜码来表示人体动作并将其正则化为正态分布。用来进行一个全身的先验,来惩罚那些人体根本做不出来的动作。
互穿惩罚
使用BVH检测一系列碰撞三角形C,然后由三角形C及其法线n计算局部圆锥3d距离场,接着由距离场的位置计算入侵深度,并对入侵进行惩罚。
性别分类器
为了拟合更加准确,需要先知道图片上人的性别才能更好的选择预设模型。SMPL-X训练了一个性别分类器,将全身的图像和openpose关键点输入,使用Resnet18进行训练,最终输出性别概率,若最终输出的性别概率均低于阈值,则直接使用中性模型。
灰色显示了性别特征。蓝色表示性别分类器不确定。

模型优化
在优化中采用多级优化。首先估计相机的平移和身体的方位,然后固定相机参数,优化体型参数和动作参数。然后使用退火算法来处理局部最有解,先提高肢体动作部分,再提升手部和胳膊,最后提升双手和脸部的模型。
SMPL-X比SPML的提升:
增加了手部的动作和人脸的表情
使用变分自编码器(VAE)学习了一个新的先验,表现更好的动作先验。
定义了一个新的互穿惩罚项,比smpl中的近似方法更准确有效
训练了一个性别检测器,判断使用哪套模型(男,女,中)
实现了训练直接回归smpl-x参数,比之前的smpl快8倍
Watching Humans in the Mirror
出发点:解决单目(一张图片)的深度歧义性
所谓深度歧义性:三维场景到二维图像的成像过程中,存在严格的几何映射关系。当没有任何先验信息时,场景深度和相机焦距存在固有的歧义性。

之前:
在训练的过程中增加额外的监督信号—约束各个关节在深度方向的前后次序一致
采用场景或者地面约束—假如有预先重建好的场景几何,就能进一步的约束人的位置和姿态。

本文:利用镜子的约束来解决深度歧义性
利用镜子的约束可以拟合出更加准确的三维人体姿态。
镜子提供了一个额外的虚拟视角,其次可以观察到人在相机角度观察不到的部分
在优化的过程中主要是采用重投影优化和镜面对称优化。


STAR
发布SMPL模型的研究人员在2020提出了一个最新的研究成果。STAR。
STAR改进SMPL主要在5个方面。
-
模型内部参数:减少至SMPL的20%
-
pose参数变化带来的人体模型变化是稀疏且局部的,即左手腕的运动不会影响右腿的形状。
-
模型的微分是稀疏的,因为参数是稀疏且局部的。
-
人体模型的训练数量从原来的4000增加到14000。
-
pose参数变化带来的人体模型变化应该是和体型相关的,即胖的人的抬腿和瘦的人抬腿,在腿部的形状变化应该是不同的。
Loper M, Mahmood N, Romero J, et al. SMPL: A skinned multi-person linear model[J]. ACM transactions on graphics (TOG), 2015, 34(6): 1-16.
Pavlakos G, Choutas V, Ghorbani N, et al. Expressive body capture: 3d hands, face, and body from a single image[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 10975-10985.
Osman A A A, Bolkart T, Black M J. Star: Sparse trained articulated human body regressor[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16. Springer International Publishing, 2020: 598-613.
Fang Q, Shuai Q, Dong J, et al. Reconstructing 3D Human Pose by Watching Humans in the Mirror[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 12814-12823.

Author kong
LastMod 2021-12-15