循环神经网络
Contents
循环神经网络
RNN,LSTM,GRU
在之前的学习中,提到了一种称为vanilla的前馈网络,所有网络架构都有这种基础架构,会接收一些输入,输入是固定尺寸的对象,比如一幅图片或一片向量,它在通过一些隐藏层后给出单一的输出结果,比如一个分类;但是在机器学习中,有时候希望有更加灵活的机器能够处理的数据类型,所以这时候RNN就有了很大的发挥空间,用RNN来处理各种类型的输入和输出数据,一旦使用RNN,就可以实现1对多模型、多对1,模型以及多对多模型。
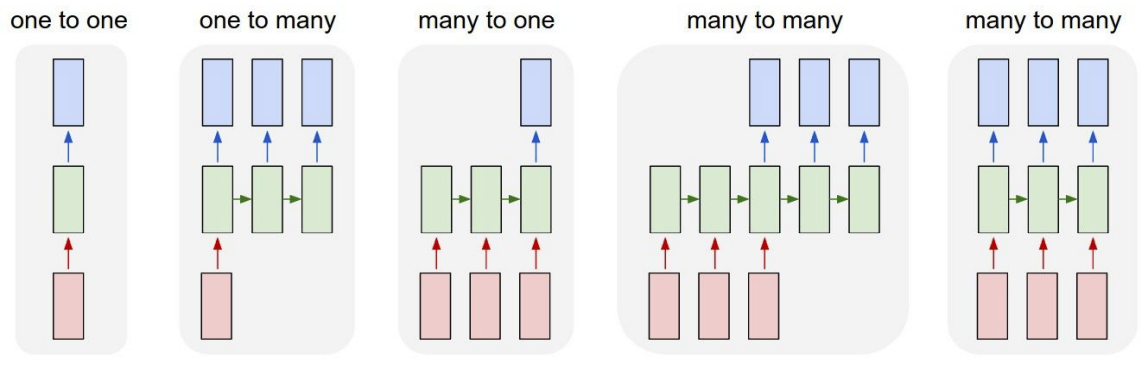

因此,RNN非常重要,即使对有固定输入大小和固定输出大小的问题,RNN也同样很有用,例如想要对输入进行序列化处理,收到了一个固定大小的输入,如一幅图像,要做出分类决策,即图像中的数字是多少,这里将不是做单一的前向传播,而是看看图片,观察图片的各种不同部分,然后在完成一组观察后作出最终决策。 总体而言,每个RNN网络都有一个小小的循环核心单元,它把x作为输入,将其传入RNN,RNN有一个内部隐藏态,这一隐藏态会在RNN每次读取新的输入时更新,然后当模型下一次读取输入时,这一内部隐藏态会将结果反馈至模型。
语言模型
在语言模型的问题中,我们想要读取一些语句从而让神经网络在一定程度上学会生成自然语言,这在字符水平上是可行的,让模型逐个生成字符,同样可以在单词层面上让模型逐个生成单词。
想象一个字符级的语言模型,网络会读取一串字符序列,然后需要去预测这个文本流的下一个字符是什么,在这里有很小的字符表helo以及训练序列样例 “hello”,在这个语言模型的训练阶段,将这个字符序列作为输入项,考虑每个输入实例是一个字母,所以要想办法在神经网络中表示这些字母,找出在神经网络中整个单词的表示方式,这个例子中的表示方式如下:
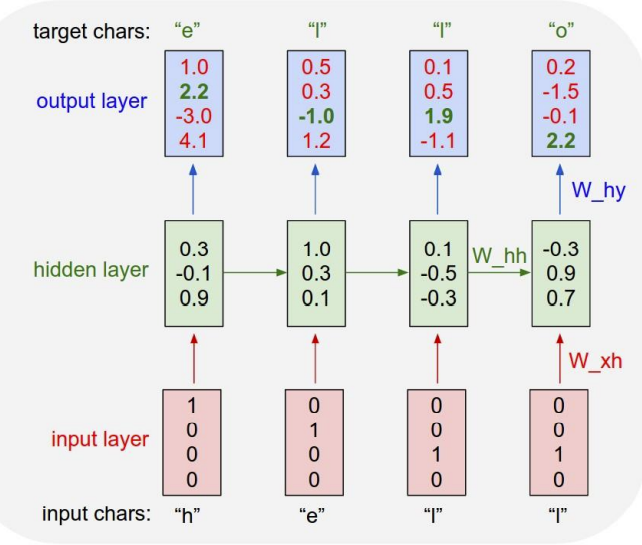

然后随着网络的前向传播,该输入进入一个RNN单元内,之后输出,即网路对组成单词的每个字母的预测,也就是认为接下来最可能出现的字母。
考虑模型在之后的测试阶段会发生什么,我们可能会用该模型测试一下样本,并使用这个训练好的神经网络模型去生成新的文本;采用的方法是通过输入一些文本的前缀来测试这个模型,在这个实例中,这些前缀只是一个字母h,在递归神经网络的第一步输入字母h,它会产生一个基于词库中所有的字母得分的分布,在训练阶段,使用这些得分去输出一个结果,所以使用一个softmax函数,把这些得分转换为一个概率分布,然后从这些概率分布中得到样本输出去生成序列中的第二个字母。
在实际的反向传播过程中,通常采用一种近似方法,称之为沿时间截断反向传播方法,这个方法的思想是即使输入序列很长,甚至趋近于无限,采用的方法是在训练模型时前向计算若干步,也就是会计算机若干子序列的损失值,然后沿着这个子序列反向传播误差,并计算梯度更新参数,重复此过程;
图像标注
在之前的学习内容中多次提到了图像标注模型,想训练一个模型用来输入一个图像,然后输出自然语言的图像语义信息。
这里的输出语义信息可能是可变长度的字符序列,可能不同的标签有不同的字母数量,所以这很适用于RNN模型,因为模型看上去有一部分卷积网络用来处理输入的图像信息,还有很多这个位置工作的卷积神经网络,它们将产生图像的特征向量,然后输入到接下来的循环神经网络语言模型的第一个时序。
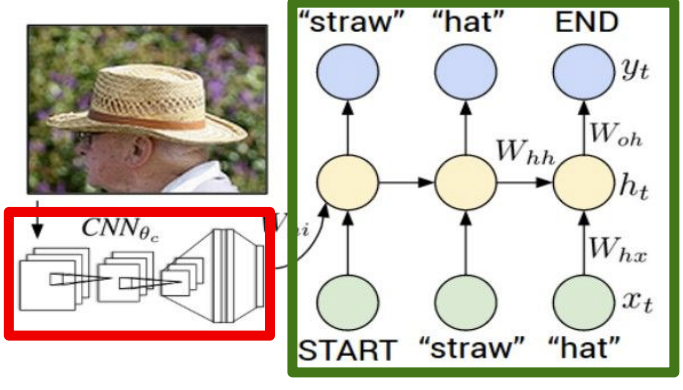

这是之前看到过的字符级语言模型,把图像输入通过卷积神经网络,用末尾的4096维的向量作为第一个初始化输入,得到词汇表中的所有分数的分布,从分布中采样并在下一次时间步时当作输入传回,最后就能生成完整的句子。经过这些训练之后,可以得到很好的结果。
通常的方式是相比于产生一个单独的向量来整合整个图像,卷及网络倾向于产生由向量构成的网络,即可能从每个图片中特殊的地方都用一个向量表示,当把这个模型向前运行时,除了在每一步中采样,也会产生一个分布,即在图像中它想要看的位置,图像位置的分布可以看成是一种模型在训练过程中应该关注哪里的张量;第一个隐藏状态计算在图片位置上的分布,它将会回到向量集合,给出一个概要矢量,这可能会把注意力集中在图像的一部分上;现在这个概要向量得到了反馈作为神经网络下一时间步的额外输入,将会产生两个输出:一个是词汇表上的分布;一个是图像位置的分布;整个过程重复继续下去:
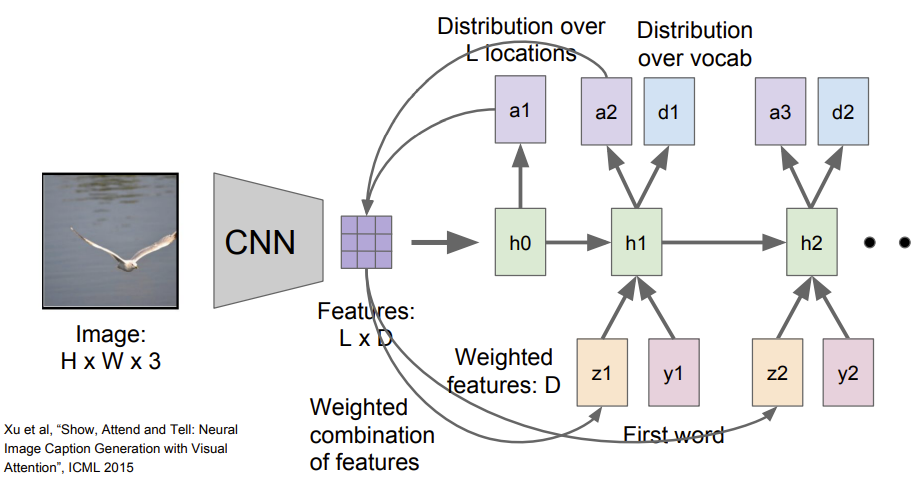

当训练完模型后,可以看到它会在图像中转移注意力,在生成每个图片标题的单词时,可以看到它生成标题:A bird flying over a body of water.但是可以看到它的注意力在图片中的不同地方变换。


Author kong
LastMod 2022-04-07