损失函数和最优化
Contents
损失函数
损失函数:预测结果和真实结果的差距–即判断训练模型的好坏
最优化:求损失函数最优化的过程–优化训练模型的过程
回到一个猫的示例图像及其在“ cat”、“ dog”和“ ship”类别中的得分,我们看到该示例中的特定权重组合一点都不好: 我们输入了描述猫的像素,但与其他类别相比,猫的得分非常低(- 96.8)(狗得分437.9,船得分61.95)。我们将用损失函数(有时也称为成本函数或目标)来衡量我们对结果的不满。直观地说,如果我们对培训数据分类不当,损失会很大,如果我们做得好,损失会很小。
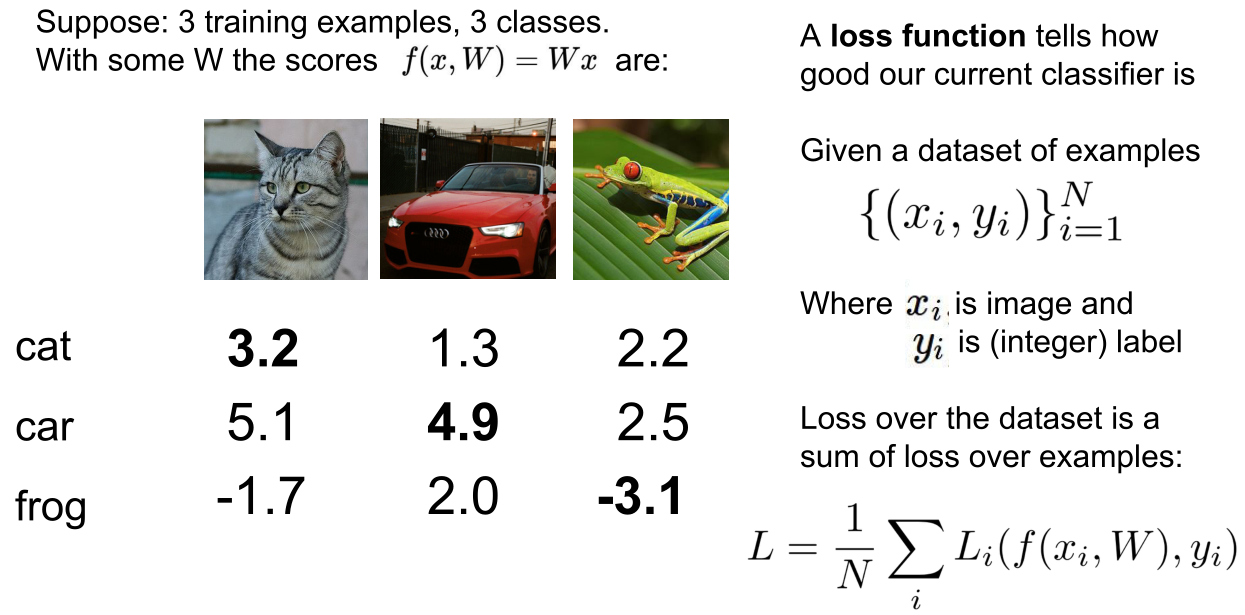

- 3个训练样本,三个类,预测函数f(x,W)=Wx,W的分数如图
- 损失函数告诉我们当前的分类器有多好
- 训练数据集x,y。有N个样本,x是算法的输入,即为图片每个像素点所构成的数据集。y是希望算法预测出来的东西,标签或目标(即真值),y是尝试将图片分类到十个中的一个,即为一个1-10的整数,或0-9。这个整数表明,对于图片x哪个分类是正确的。
- 有了这个关于x的预测函数f(通过样本x和权重矩阵W给出y的预测)之后,即可定义损失函数Li,即通过预测函数f给出的预测的分数,和真实的目标或者说是标签y可以定量的描述训练样本预测的好不好
- 损失函数L在整个数据集中N个样本的损失函数的总和的平均。
- 想要用某个损失函数定量的描述参数W是否令人满意,然后在所有的W中,找到训练集上损失函数极小化的W
Multiclass SVM loss
Multiclass Support Vector Machine (SVM) loss:多类支持向量机的损失
单个例子的损失函数Li
- 除了真实的分类Yi以外,对所有分类Y都做加和,也就是说我们在所有错误的分类上做和,然后比较正确分类的分数和错误分类的分数,如果正确分类的分数比错误分类的分数高,且高出某个安全的边距,这里把边际设为1。
- 如果真实的分数很高,或者真实分类的分数比其他错误分类的分数都要高很多,那么损失为0
- 把图片对每个错误分类的损失加起来,就可以得到数据集中这个样本的最终损失。
- 然后对整个训练集取平均
Hinge loss
合页损失函数


- x轴表示Syi,是训练样本真实分类的分数。Sj是通过分类器预测出来类的分数。y轴是损失
- 随着真实分类的分数提升,损失会线性下降,一直到分数超过了一个阈值,损失函数就会是0。因为我们已经为这个样本成功的分类。
- L(cat)=max(0,5.1-3.2+1)+max(0,-1.7-3.2+1)=max(0,2.9)+max(0,-3.9)=2.9
- 这也一定程度上表明2.9是分类器对于这一训练样例,训练得多好的一个量化衡量指标。
- L(car)=max(0,1.3-4.9+1)+max(0,2.0-4.9+1)=0
- 完整数据集放入损失为平均值。
|
|
正则化
假设我们找到了一个W,使得L=0。但是W并不唯一。如何进行选择W。
我们仅仅告诉分类器,他需要找到可以拟合训练集的W,但实际上我们并不关心拟合训练数据。机器学习的重点是,我们使用训练数据来找到一些分类器,然后将这个东西应用于测试数据。所以我们并不关心训练集的表现,只关心这个分类器的测试数据的表现。
所以如果仅仅告诉分类器,只需要拟合训练集的话,就有可能陷入尴尬的境地。分类器可能会行为反常。
假设我们有这样的数据集,就是图中的蓝点,并且我们将会为训练数据拟合一些曲线。如果我们告诉分类器做的唯一的事情就是尝试和适合训练数据,他可能会成为非常曲折的曲线,尝试完美分类所有的训练数据点,这很糟糕,因为我们实际并不关心(过拟合)。我们关心测试数据的性能,新的数据进来后,蓝色分类就错误了,实际上更希望分类器可能是预测的绿色的直线。而不是非常复杂的完全适合所有的训练数据的蓝线。
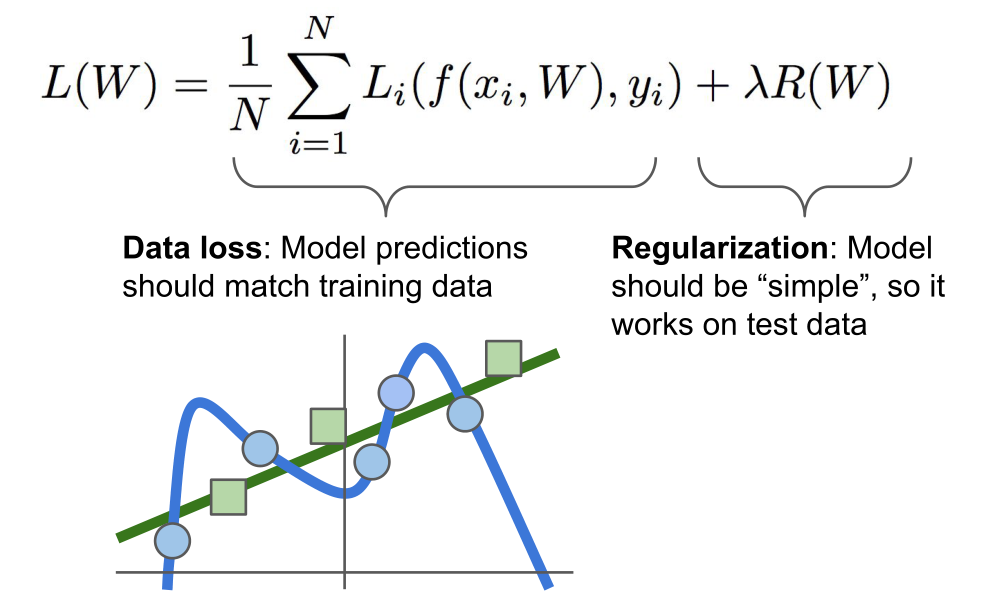

解决方法:正则化。所以要为损失函数添加一个附加的项,除了数据丢失外(告诉分类器需要拟合数据集外),通常会添加一个项到损失函数中,这个项称为正则项,鼓励模型以某种方式选择更简单的W,这里所谓的简约,取决于任务的规模和模型的种类。体现了Occam’s Razor的理念,要让理论的应用更广泛,也就是说,如果你有很多个可以解释你观察结果的假设,一般来说,你应该选择最简约的。因为这样可以在未来将其用于解释新的观察结果。直接假设正则化惩罚项,R。超参数λ来平衡这两个项。
Softmax Classifier
多项式逻辑回归


指数化–归一化–损失函数-logp
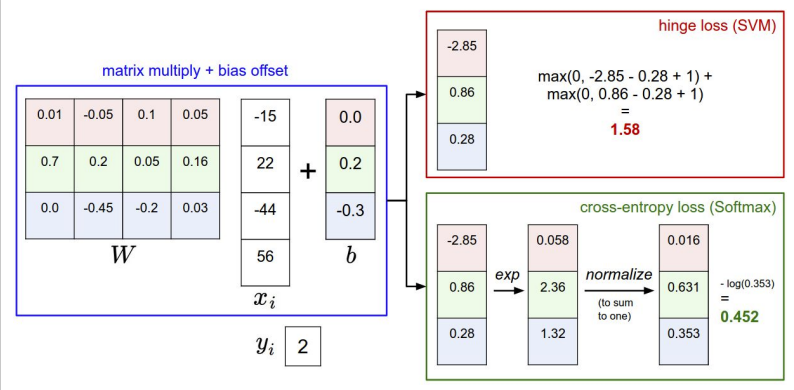

svm损失函数:只关心的是正确的分值要比不正确的分值高出一个边际。
softmax:目标是将概率质量函数(离散分布值)等于1。
在这两种情况下,我们都计算出相同的分数向量 f (例如,在这一节中,我们用矩阵乘法表示)。不同之处在于对 f 中分数的解释: SVM 将这些分数解释为类分数,其损失函数鼓励正确的类(2类,蓝色)获得比其他类分数更高的分数。而 Softmax 分类器将分数解释为每个类的(非标准化)对数概率,然后鼓励正确类的(标准化)对数概率为高(相当于负值为低)。这个例子的最终损失是1.58的支持向量机和1.04(注意这是1.04使用自然对数分类器,而不是基2或基10)的 Softmax 分类器,但请注意,这些数字是不可比较的; 他们只是有意义的损失计算在相同的分类器和相同的数据。
softmax分类器允许我们计算“概率”的所有标签。例如,给定一幅图像,SVM 分类器可能会给出“ cat”、“ dog”和“ ship”类的分数[12.5,0.6,-23.0]。Softmax 分类器可以代替计算三个标签的概率为[0.9,0.09,0.01] ,这允许您解释它在每个类中的置信度。然而,我们之所以在引号中加上概率这个词,是因为这些概率有多大直接取决于正则化强度 λ-你负责的系统的输入。
Optimization
最优化
(1)在实践中,倾向于从某个解决方案开始,使用多种不同的迭代方法,然后逐步对它进行改进,一种方法就是随机搜索:需要有很多的权重值随机采样,然后将它们输入损失函数,看看效果如何,但这不是一个好的方法。
(2)另一种方法是梯度下降:梯度是偏导数的向量,它指向函数增加最快的方向,相应的负梯度方向就指向了函数下降最快的方向;梯度给出了函数当前点的一阶线性逼近,很多深度学习应用都是在计算函数的梯度,然后利用这些梯度迭代更新参数向量。
总结:
(1)使用数值梯度的方法:近似值、速度慢、容易写;
(2)使用分析梯度的方法:精确值、速度快、容易出错。
图像特征
计算图片的各种特征代表,比如计算与图片形象有关的数值,然后将不同的特征向量合到一起,得到图像的特征表述。关于图像的特征表述会作为输入源传入线性分类器,而不是将原始像素传入分类器。


使用图像特征的原因:如上图,有一个训练数据集如左侧所示,红点分布在中间,蓝点分布在周围,对于这种类型的数据集,不能用一个线性决策边界,来将红点从蓝点中分开。但是可以采用一个灵活的特征转换,极坐标转换。就可以把复杂的数据集变成线性可分的,然后由线性分类器正确分类。
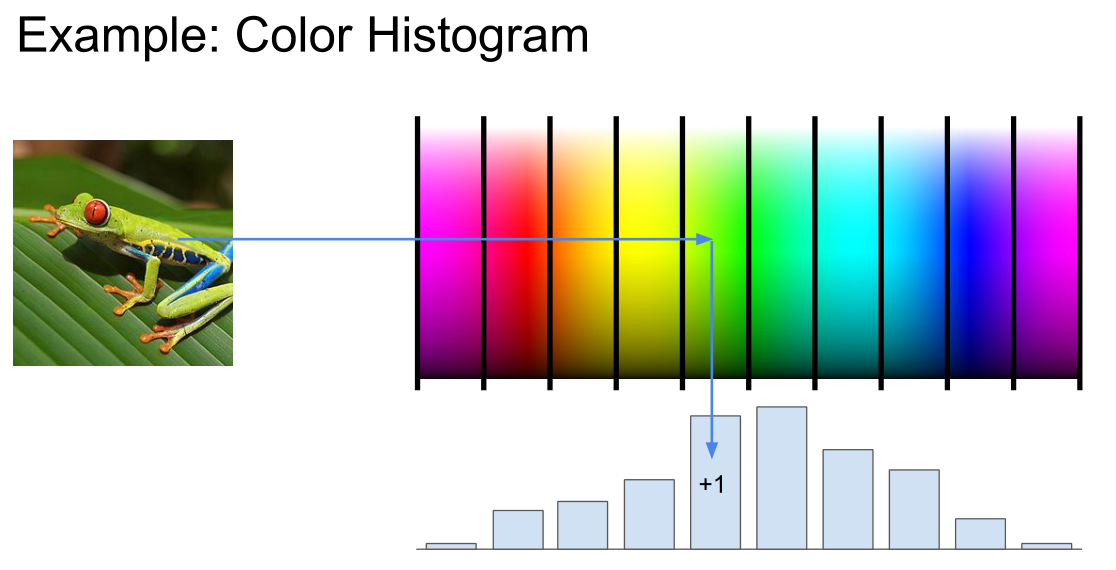
- 颜色直方图
获取每个像素值对应的光谱,把它分到柱状里,将每一个像素,都映射到这些柱状里,然后计算出每一个不同柱状中像素点出现的频次,这个从全局上告诉我们图像中有哪些颜色,

- 梯度方向直方图
Histogram of Oriented Gradients
获取图像,然后将图像按八个像素区分为八份,然后在八个像素区的每一个部分,计算每个像素值的主要边缘方向,把这些边缘方向量化到几个组,然后在每一个区域内,计算不同的边缘方向从而得到一个直方图。现在,全特征向量就是这些不同的组的边缘方向直方图,


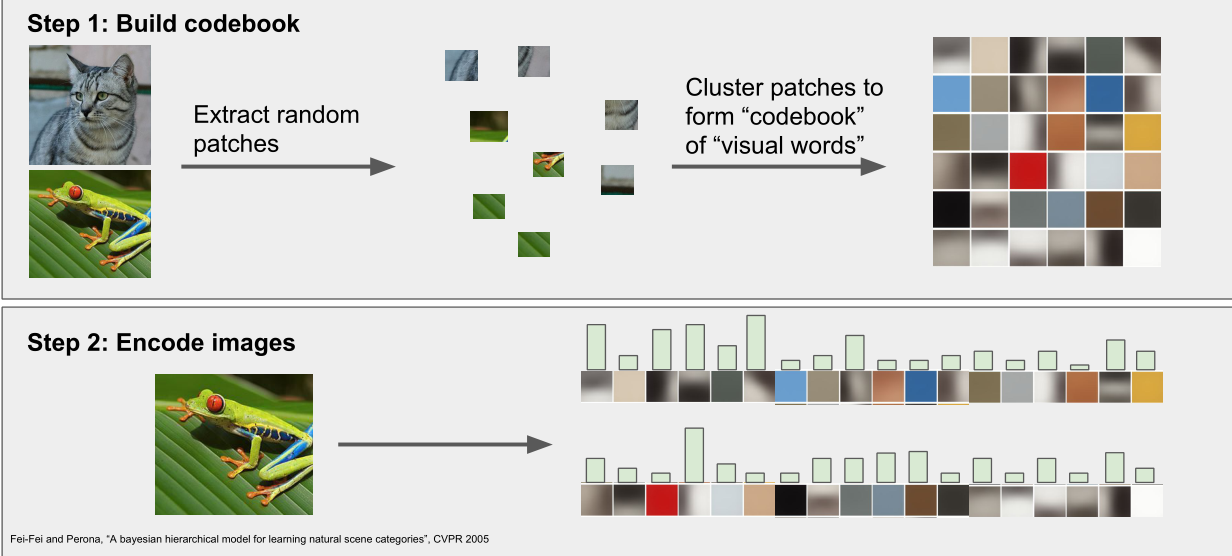
- Bag of Words:词
这是从自然语言处理中获得的灵感,用一个特征向量表示一段话的方式是计算不同词在这段胡中出现的次数;将这种方式应用于图像,将图像转换为一段话并不容易,所以要定义一个视觉单词字典。首先获得一堆图像,从这些图像中进行小的随机块的采样,然后采用k均值等方法将它们聚合成簇,从而得到不同的簇中心,这些簇中心可能代表了图像中视觉单词的不同类型。

卷积神经网络:直接从数据中学习特征,而不需要提前记录,将获取的像素值输入卷积神经网络,经过多层计算,最终得到一些数据驱动的特征表示的类型,然后在整个网络中训练所有的权重,而不是最上层线性分类器的权重。
Author kong
LastMod 2022-03-06