训练神经网络(下)
Contents
训练神经网络(下)
更好的优化
上一章中讨论了一些激活函数和它们不同的属性,由于sigmoid函数和tanh函数在两端都存在梯度消失的问题,所以在实际中一般建议使用ReLU函数和它的其他形式;同时也讨论了权重初始化,在深度网络变得越来越深的时候,权重的初始化会变得非常重要;在数据的预处理的方面讨论了中心化和归一化的问题,这一章中将继续讨论更多有关训练神经网络的细节问题,最重要的是与之前相比更有效的优化方法、正则化策略以及迁移学习。 训练神经网络的核心策略是一个优化问题,已经使用到的一个优化的方法是随机梯度下降法。
但是不幸的是这个相对简单的优化算法在实际中会产生很多问题。
- 这类目标函数梯度的方向并不是与最小值成一条线,当计算梯度并沿着前进时,可能会一遍遍的跨过这些等高线之字形的前进或后退,所以在水平维度上的前进速度非常慢,在这个方向上的敏感度较低,却在垂直维度上非常敏感,这并不是所期望的结果;而且这样的问题在高维空间变得更加普遍。
- 随机梯度法的另一个问题是局部最小值或鞍点,在局部最小值这种情况下,随机梯度法会卡在中间,因为这里是局部极小值,梯度为0,不会做任何移动;关于鞍点,往一个方向是向上,往另一个方向是向下,在当前的位置,梯度也是0,此时会卡在鞍点处。
- 如果N是整个训练集,每次计算损失都会耗费很大的计算量,事实上经常通过小批量的对损失和梯度进行估计,这意味着并不会每一步去计算真实的梯度,而是在当前点对梯度进行噪声估计, 所以这种曲折的线路实际上会花费很长时间才能得到极小值。
对于这些出现的问题,经常会有一个优化的算法来解决,在随机梯度下降中加入一个动量项,如下所示:


左侧是经典的随机梯度下降法,通常只是在梯度的方向上前进;而在右侧有一个非常小的方差称为带动量的随机梯度下降法,它的思想是保持一个不随时间变化的速度,并且将梯度估计添加到这个速度上,然后在这个速度上前进而不是在梯度的方向上前进,其中有一个超参数是摩擦系数ρ,这个简单的策略解决了刚才讨论的所有问题。
问题:带动量的随机梯度下降如何处理条件很差的坐标? 答:回顾一下速度估计以及速度计算,会发现在每一步都增加了梯度,这一定程度上取决于摩擦系数ρ的设置;如果梯度较小,这种情况下ρ表现很好,那么速度可以单调递增到一个速度会比实际梯度更大的点,然后可能会更快速地处理条件差的维度。
当在使用带动量的随机梯度下降时,可以想象如下图中的图像:
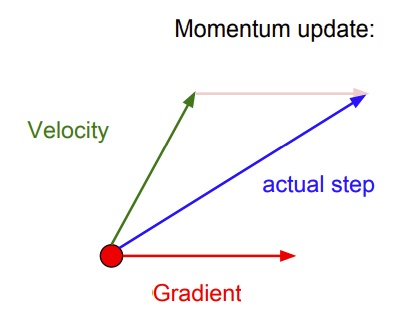

这个红色的点是当前位置,有一些红色向量表示梯度,绿色向量表示速度向量的方向,当做动量更新时,实际上是在这两者的平均权重进行前进,这有助于克服梯度估计中的一些噪声;
有时会看到向量有一个轻微的变化,叫Nesterov加速梯度,如下所示:
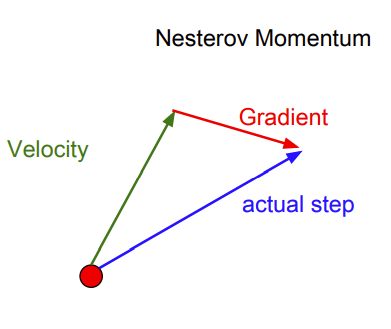

在普通的随机梯度中,估算当前位置的梯度,然后取速度和梯度的混合;而在Nesterov加速梯度中,从红点开始,在取得速度的方向上进行前进,之后评估这个位置的梯度,随后回到原始位置将这两者混合起来。
。。。
正则化
如何能提高单一模型的效果,使用集成学习时,测试的时候还是要在10个模型基础上学习,这并不是很好;正则化正是能提高单一模型的效果的方法。
一个在神经网络中常用的正则化方法是dropout:每次在网络中正向传递时,在每一层随机将一部分神经元置0(激活函数置位0),每次正向传递时,随机被置0的神经元都不是完全相同的。
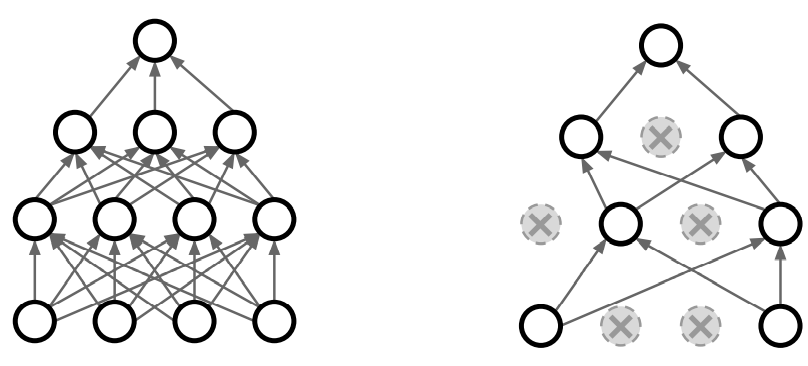

如果把左边这个全连接网络和右边经过dropout的版本进行对比,会发现dropout后的网络像是同样的网络变小了一号,只用到了其中一部分神经元,并且每次遍历和正向传递都是不同的部分。
对于dropout的解释: 这是在单一模型中进行集成学习,每一种可能的dropout方式都可以产生一个不同的子网络,所以dropout像是同时对一群共享参数的网络进行集成学习;因此dropout的可能性随神经元个数呈指数倍增长,不可能穷举每种情况,可以看作一个巨大的网络集在同时被训练。
更通用的正则化策略就是:
在训练期间,给网络加一些随机性以防止过拟合训练数据;在测试期间,要抵消掉所有的随机性希望能够提高泛化能力。
另一种符合这种范数的策略是数据增强的想法,在训练的时候有一个最初的版本,有自己的数据和自己的标签,每次迭代时使用它去更新卷积神经网络;但在训练过程中能以某种方式随机地转换图像使得标签可以保留不变,使用这些随机转换的图像进行训练。
所以可以从这样的图像中抽取不同尺度大小的裁剪图像,然后在测试过程中通过评估一些固定的裁剪图像来抵消这种随机性。
有时候在数据增强中会使用色彩抖动的方法,可能会在训练时随机改变图像的对比度和亮度,可以通过色彩抖动得到更复杂的结果。 还有一些其他的正则化策略包括:批量归一化(通常使用这个)、DropConnect、部分最大池化、随机深度。
迁移学习
在使用正则化的时候通过加入不同的正则策略可以帮助减小训练误差和测试误差的间隙,这种情况下往往需要更大的数据集,而迁移学习的思想不再需要大数据集也能训练卷积神经网络。
首先找到一些卷积神经网络,这里有足够的数据去训练整个网络;然后尝试把从这个数据集中训练出的提取特征的能力用到新的小数据集上;接着一般做法是从最后一层的特征到最后的分类输出之间的全连接层,需要重新随机初始化这部分矩阵;现在如果要训练一个线性分类器只需训练最后这层让它在数据上收敛;若有更多的数据,可以尝试更新网络的更大一部分。 通用的策略是更新网络时将学习率调低,因为最初的网络参数可能在大数据集上是收敛的,泛化能力已经很强,这时只希望让它们做一个微小的调整来适应新的数据集。
迁移学习的思想是非常普遍的,目前无论是计算机视觉的哪方面应用,大多数人都不会从头训练这些东西,大多数情况下卷及神经网络在ImageNet上预训练,然后根据任务在进行精调。
(1)不管遇到什么样的模型,对于要处理的问题没有大数据集,应该做的是下载一些相关的预训练模型; (2)然后要么重新初始化部分模型,要么在数据上进行精调。
这里给出了一些预训练模型的下载地址:
Caffe: https://github.com/BVLC/caffe/wiki/Model-Zoo TensorFlow: https://github.com/tensorflow/models PyTorch: https://github.com/pytorch/vision
Author kong
LastMod 2022-03-27