深度学习软件
Contents
深度学习软件
CPU vs GPU
深度学习中一般使用到的是GPU,GPU被称作显卡或者图形处理单元,最初适用于渲染计算机图形,在深度学习中一般选用的是NVIDIA。
可以在GPU上直接写出运行代码,在NVIDIA中有一个叫做CUDA的抽象代码,可以写类C代码并且可以在GPU上直接运行;同时NVIDIA有很多开源库可以来实现高度优化,比如cuBLAS、cuFFT、cuDNN等。
框架
- 这些框架可以使你非常轻松地构建和使用一个庞大地计算图,而且不用自己去管那些细节的东西;
- 无论什么时候使用深度学习总是需要计算梯度和损失,计算损失在权重方向的梯度,这些框架能够帮助自动的计算这些;
- 希望所有这些可以在GPU上高效运行,这样就不用太关注一些低级别的硬件(如cuBLAS、cuDNN等)以及数据在CPU和GPU内存之间的移动。
下面给出在nump和两个框架TensorFlow和pytorch下的计算图的实现:
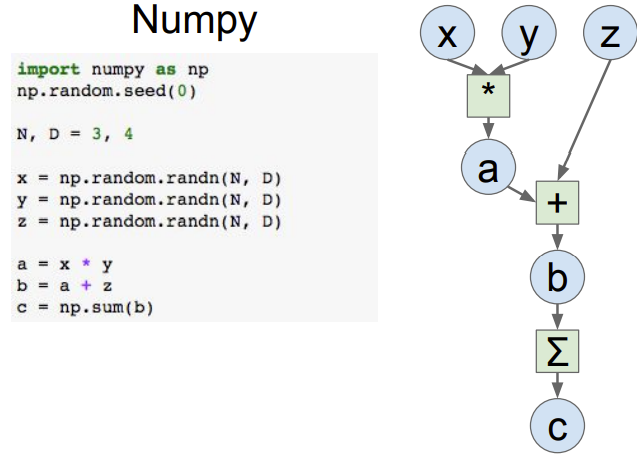





可以看到TensorFlow和pytorch的代码在前向传播和Numpy看起来几乎完全一样,但是在TensorFlow和pytorch中可以自动计算梯度且可以自动运行在GPU上。
TensorFlow
TensorFlow是有预训练模型的,这里有TF-Slim和Keras的一些例子,所以在训练自己的任务时,在这些预训练模型的基础上精调是非常重要的。
TF-Slim: (https://github.com/tensorflow/models/tree/master/slim/nets)
Keras: (https://github.com/fchollet/deep-learning-models)
PyTorch
Facebook的PyTorch不同于TensorFlow,它的内部明确定义了3层抽象:
(1)PyTorch的张量对象就像numpy数组只是一种最基本的数组,与深度学习无关,但可以在GPU上运行; (2)PyTorch有变量对象,就是计算图中的节点,这些节点构成了计算图从而可以计算梯度等等; (3)PyTorch有模对象,它是一个神经网络层,可以将这些模组合起来建立一个大的网络。
在PyTorch里还有一个比较好的东西叫dataloader,可以让你建立分批处理,也可以执行多线程,dataloader可以打包数据提供一些抽象。
接下来讨论一下关于静态和动态的图,这是TensorFlow和PyTorch最大的不同。在TensorFlow中有两个操作阶段,这里第一步建立了计算图然后运行一遍又一遍,运用同一个图,把这个叫做静态计算图;在PyTorc
h中建立一个新的计算图时,它会在每一次前向传播时都更新,把这个叫做动态计算图。 关于静态图,只会构建一次,然后不断地复用它,整个框架有机会在图上做优化,结合一些操作、排列一些操作,找到更有效率的操作方法,所以图可以更有效率,
Caffe
它是一个不同于其他框架的深度学习框架,很多时候不需要写任何代码就可以训练网络。
首先将数据格式转换成HDF5格式或者LMDB格式或者可以将图像文件或文本文件转换成可以进入Caffe的脚本,然后定义计算图的结构只需要修改一个叫prototxt的文件来设置计算图结构。
Caffe具有很好的前向传播模型,很适合产品化,它的python的接口是非常有用的并且能够不需要写任何代码就可以训练模型。
Author kong
LastMod 2022-03-27