动手学深度学习-李沐
Contents
安装
|
|
softmax-09
卷积神经网络
线性神经网络:
线性回归模型时一个单层神经网络
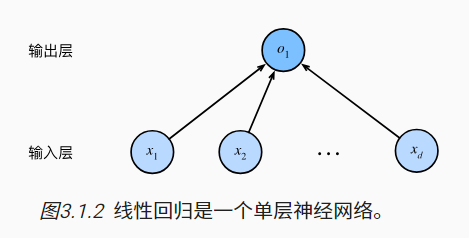
- 输入:我们定义一个
data_iter函数, 该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。 每个小批量包含一组特征和标签。通常,我们利用GPU并行运算的优势,处理合理大小的“小批量”。 每个样本都可以并行地进行模型计算,且每个样本损失函数的梯度也可以被并行计算。 GPU可以在处理几百个样本时,所花费的时间不比处理一个样本时多太多。我们直观感受一下小批量运算:读取第一个小批量数据样本并打印。 每个批量的特征维度显示批量大小和输入特征数。 同样的,批量的标签形状与batch_size相等。当我们运行迭代时,我们会连续地获得不同的小批量,直至遍历完整个数据集。 上面实现的迭代对教学来说很好,但它的执行效率很低,可能会在实际问题上陷入麻烦。 例如,它要求我们将所有数据加载到内存中,并执行大量的随机内存访问。 在深度学习框架中实现的内置迭代器效率要高得多, 它可以处理存储在文件中的数据和数据流提供的数据。 - 初始化模型参数:通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重, 并将偏置初始化为0。
- 在初始化参数之后,我们的任务是
更新这些参数,直到这些参数足够拟合我们的数据。 每次更新都需要计算损失函数关于模型参数的梯度。 有了这个梯度,我们就可以向减小损失的方向更新每个参数。 - 定义模型:将模型的输入和参数同模型的输出关联起来
- 损失函数:需要计算损失函数的梯度
- 优化算法: 小批量随机梯度下降。使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度。 接下来,朝着减少损失的方向更新我们的参数。sgd
- 训练: 在每次迭代中,我们读取一小批量训练样本,并通过我们的模型来获得一组预测。 计算完损失后,我们开始反向传播,存储每个参数的梯度。 最后,我们调用优化算法
sgd来更新模型参数。 - 在机器学习中,我们通常不太关心恢复真正的参数,而更关心如何
高度准确预测参数。 幸运的是,即使是在复杂的优化问题上,随机梯度下降通常也能找到非常好的解。 其中一个原因是,在深度网络中存在许多参数组合能够实现高度精确的预测。
|
|
回归和分类:
- 分类:表示分类数据的简单方法:独热编码(one-hot encoding)。 独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。
- 为了估计所有可能类别的条件概率,我们需要一个有多个输出的模型,每个类别对应一个输出。
softmax回归
与线性回归一样,softmax回归也是一个单层神经网络。
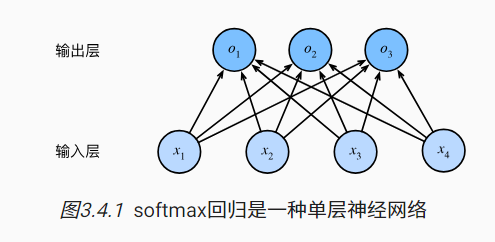
-
为了得到预测结果,我们将设置一个阈值,如选择具有最大概率的标签。然而我们能否将未规范化的预测o直接视作我们感兴趣的输出呢? 答案是否定的。 因为将线性层的输出直接视为概率时存在一些问题: 一方面,我们没有限制这些输出数字的总和为1。
-
要将输出视为概率,我们必须保证在任何数据上的输出都是非负的且总和为1,我们需要一个训练的目标函数,来激励模型精准地估计概率。
-
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持 可导的性质
-
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。 因此,softmax回归是一个线性模型(linear model)。
-
唯一的区别是,我们现在用一个概率向量表示,如(0.1,0.2,0.7), 而不是仅包含二元项的向量(0,0,1)。 我们使用 (3.4.8)来定义损失l, 它是所有标签分布的预期损失值。 此损失称为交叉熵损失(cross-entropy loss)
-
在训练softmax回归模型后,给出任何样本特征,我们可以预测每个输出类别的概率。 通常我们使用预测概率最高的类别作为输出类别。
-
softmax不仅仅把 多个输出构造成概率分布,而且起到了归一化的作用,适用于很多需要进行归一化处理的分类问题。
-
softmax的使用地方:得到预测值
-
softmax和交叉熵损失之间的关系:
当使用Softmax函数作为输出层的激活函数时,交叉熵损失函数能够自然地处理概率值,并且能够提供关于如何调整网络权重以减少预测概率分布与真实概率分布之间差异的有用信息。由于交叉熵损失函数对概率分布的误差非常敏感,特别是当某些类别的概率接近1时,它鼓励神经网络产生高置信度的准确预测。因此,Softmax和交叉熵损失函数的组合在多分类问题中被广泛使用,以实现有效的模型训练和性能优化。
Softmax函数将这些输出转化为概率分布,即每个类别的预测概率。
交叉熵损失函数衡量的是两个概率分布之间的差异。在多分类问题中,我们通常将Softmax函数的输出(即预测的概率分布)与真实标签对应的概率分布进行比较。真实标签对应的概率分布是一个“一热编码”向量(one-hot encoding vector),其中只有与真实类别的元素为1,其余元素为0。
|
|
数据集:
-
Fashion-MNIST由10个类别的图像组成, 每个类别由训练数据集(train dataset)中的6000张图像 和测试数据集(test dataset)中的1000张图像组成。 因此,训练集和测试集分别包含60000和10000张图像。 测试数据集不会用于训练,只用于评估模型性能。
-
每个输入图像的高度和宽度均为28像素。 数据集由灰度图像组成,其通道数为1。
-
Fashion-MNIST中包含的10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。
-
可视化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47import torch import torchvision from torch.utils import data from torchvision import transforms from d2l import torch as d2l from PIL import Image from matplotlib import pyplot as plt # 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式, # 并除以255使得所有像素的数值均在0~1之间 trans = transforms.ToTensor() mnist_train = torchvision.datasets.FashionMNIST( root="../data", train=True, transform=trans, download=True) mnist_test = torchvision.datasets.FashionMNIST( root="../data", train=False, transform=trans, download=True) print(len(mnist_train), len(mnist_test)) print(mnist_train[0][0].shape) def get_fashion_mnist_labels(labels): #@save """返回Fashion-MNIST数据集的文本标签""" text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot'] return [text_labels[int(i)] for i in labels] def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save """绘制图像列表""" figsize = (num_cols * scale, num_rows * scale) _, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize) axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if torch.is_tensor(img): # 图片张量 ax.imshow(img.numpy()) else: # PIL图片 ax.imshow(img) ax.axes.get_xaxis().set_visible(False) ax.axes.get_yaxis().set_visible(False) if titles: ax.set_title(titles[i]) return axes X, y = next(iter(data.DataLoader(mnist_train, batch_size=18))) print(y) show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y)); plt.show()
多层感知机
最简单的深度网络称为多层感知机。多层感知机由多层神经元组成, 每一层与它的上一层相连,从中接收输入; 同时每一层也与它的下一层相连,影响当前层的神经元。 当我们训练容量较大的模型时,我们面临着过拟合的风险。
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。
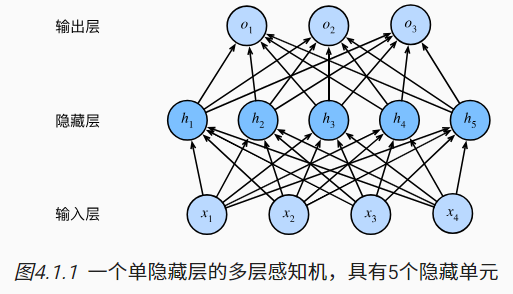
-
这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。 输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。 因此,这个多层感知机中的层数为2。 注意,这两个层都是全连接的。 每个输入都会影响隐藏层中的每个神经元, 而隐藏层中的每个神经元又会影响输出层中的每个神经元。
-
仿射变换之后对每个隐藏单元应用非线性的激活函数(activation function)。 一般来说,有了激活函数,就不可能再将我们的多层感知机退化成线性模型
-
但是本节应用于隐藏层的激活函数通常不仅按行操作,也按元素操作。 这意味着在计算每一层的线性部分之后,我们可以计算每个活性值, 而不需要查看其他隐藏单元所取的值。
-
激活函数:
-
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的。
-
ReLU:使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题
-
sigmod
-
激活层通常以非线性映射来保证深层对高级语义 信息的抽象能力,同时也缓解了训练过程中可能出现的梯度消失或爆炸问题,并加 速网络收敛。
-
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
-
具体来说,激活函数的作用包括:
- 增加网络的非线性:通过激活函数,网络可以捕捉到数据中的非线性关系,这对于解决现实世界中的复杂问题至关重要。
- 特征提取:激活函数可以帮助网络突出输入数据中的重要特征,同时抑制不重要的信息,从而使网络能够更有效地学习数据的内在结构和模式。
- 决策边界:在网络的输出层,激活函数通常用于将神经网络的输出转换为特定形式的预测,如二分类问题中的概率值。
- 梯度传播:在训练过程中,激活函数的导数(梯度)影响着反向传播算法中梯度的计算和权重的更新。一个良好设计的激活函数能够促进更有效的梯度流动,有助于网络更快地收敛。
因此,卷积层后通常会跟着一个激活函数的操作,以增强神经网络的学习能力和表达能力,从而更好地完成各种任务。
-
-
我们的目标是发现某些模式, 这些模式捕捉到了我们训练集潜在总体的规律。 如果成功做到了这点,即使是对以前从未遇到过的个体, 模型也可以成功地评估风险。 如何发现可以泛化的模式是机器学习的根本问题。
-
将模型在训练数据上拟合的比在潜在分布中更接近的现象称为过拟合(overfitting), 用于对抗过拟合的技术称为正则化(regularization)。
-
训练误差(training error)是指, 模型在训练数据集上计算得到的误差。 泛化误差(generalization error)是指, 模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望。 在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差。当我们有更复杂的模型和更少的样本时,我们预计训练误差会下降,但泛化误差会增大。通常对于神经网络,我们认为需要更多训练迭代的模型比较复杂, 而需要早停(early stopping)的模型(即较少训练迭代周期)就不那么复杂。训练多层感知机模型时,我们可能希望比较具有 不同数量的隐藏层、不同数量的隐藏单元以及不同的激活函数组合的模型。 为了确定候选模型中的最佳模型,我们通常会使用验证集。
-
原则上,在我们确定所有的超参数之前,我们不希望用到测试集。 如果我们在模型选择过程中使用测试数据,可能会有过拟合测试数据的风险,那就麻烦大了。因此,我们决不能依靠测试数据进行模型选择。 然而,我们也不能仅仅依靠训练数据来选择模型,因为我们无法估计训练数据的泛化误差。解决此问题的常见做法是将我们的数据分成三份, 除了训练和测试数据集之外,还增加一个验证数据集(validation dataset), 也叫验证集(validation set)。
-
k折验证:
- 当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。 这个问题的一个流行的解决方案是采用k折交叉验证。 这里,原始训练数据被分成k个不重叠的子集。 然后执行k次模型训练和验证,每次在k−1个子集上进行训练, 并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。 最后,通过对k次实验的结果取平均来估计训练和验证误差。
-
欠拟合:如果模型不能降低训练误差,这可能意味着模型过于简单(即表达能力不足), 无法捕获试图学习的模式。 此外,由于我们的训练和验证误差之间的泛化误差很小, 我们有理由相信可以用一个更复杂的模型降低训练误差。 这种现象被称为欠拟合(underfitting)。
-
过拟合:当我们的训练误差明显低于验证误差时要小心, 这表明严重的过拟合(overfitting)。 注意,过拟合并不总是一件坏事。 特别是在深度学习领域,众所周知, 最好的预测模型在训练数据上的表现往往比在保留(验证)数据上好得多。 最终,我们通常更关心验证误差,而不是训练误差和验证误差之间的差距。
-
正则化:
- 权重衰减(weight decay)是最广泛使用的正则化的技术之一, 它通常也被称为L2正则化。 这项技术通过函数与零的距离来衡量函数的复杂度, 惩罚权重的L2范数来正则化统计模型的经典方法
- 暂退法在前向传播过程中,计算每一内部层的同时注入噪声,这已经成为训练神经网络的常用技术。 这种方法之所以被称为暂退法,因为我们从表面上看是在训练过程中丢弃(drop out)一些神经元。 在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
-
前向传播计算图
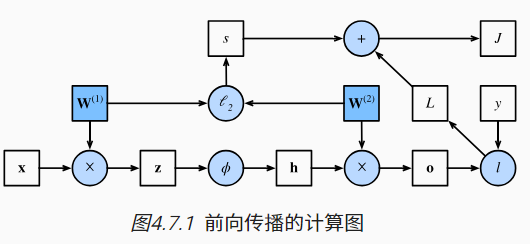
-
反向传播–链式求导。指的是计算神经网络参数梯度的方法。 简言之,该方法根据微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络。
-
模型初始化:初始化方案的选择在神经网络学习中起着举足轻重的作用, 它对保持数值稳定性至关重要。 此外,这些初始化方案的选择可以与非线性激活函数的选择有趣的结合在一起。 我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。 糟糕选择可能会导致我们在训练时遇到梯度爆炸或梯度消失。
-
要么是梯度爆炸(gradient exploding)问题: 参数更新过大,破坏了模型的稳定收敛; 要么是梯度消失(gradient vanishing)问题: 参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
- 当sigmoid函数的输入很大或是很小时,它的梯度都会消失。 此外,当反向传播通过许多层时,除非我们在刚刚好的地方, 这些地方sigmoid函数的输入接近于零,否则整个乘积的梯度可能会消失。 当我们的网络有很多层时,除非我们很小心,否则在某一层可能会切断梯度。 事实上,这个问题曾经困扰着深度网络的训练。 因此,更稳定的ReLU系列函数已经成为从业者的默认选择(虽然在神经科学的角度看起来不太合理)。
- 解决(或至少减轻)上述问题的一种方法是进行参数初始化, 优化期间的注意和适当的正则化也可以进一步提高稳定性。
卷积神经网络
(convolutional neural networks,CNN)是机器学习利用自然图像中一些已知结构的创造性方法。
多层感知机十分适合处理表格数据,其中行对应样本,列对应特征。 对于表格数据,我们寻找的模式可能涉及特征之间的交互,但是我们不能预先假设任何与特征交互相关的先验结构。 此时,多层感知机可能是最好的选择,然而对于高维感知数据,这种缺少结构的网络可能会变得不实用。
- 平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
- 局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
通道:我们忽略了图像一般包含三个通道/三种原色(红色、绿色和蓝色)。 实际上,图像不是二维张量,而是一个由高度、宽度和颜色组成的三维张量,我们可以把隐藏表示想象为一系列具有二维张量的通道(channel)。 这些通道有时也被称为特征映射(feature maps),因为每个通道都向后续层提供一组空间化的学习特征。 直观上可以想象在靠近输入的底层,一些通道专门识别边缘,而一些通道专门识别纹理。
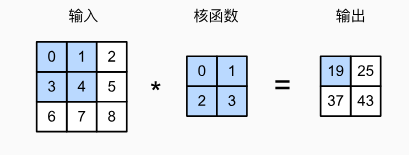
卷积:互相关运算conv
-
我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示。在 图6.2.1中,输入是高度为3、宽度为3的二维张量(即形状为3×3)。卷积核的高度和宽度都是2,而卷积核窗口(或卷积窗口)的形状由内核的高度和宽度决定(即2×2)。
-
注意,输出大小略小于输入大小。这是因为卷积核的宽度和高度大于1, 而卷积核只与图像中每个大小完全适合的位置进行互相关运算。 所以,输出大小等于输入大小nℎ×nw减去卷积核大小kℎ×kw,即:(nh-kh+1)×(nw-kw+1)
-
这是因为我们需要足够的空间在图像上“移动”卷积核。稍后,我们将看到如何通过在图像边界周围填充零来保证有足够的空间移动卷积核,从而保持输出大小不变。
-
卷积层:卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。 所以,卷积层中的两个被训练的参数是卷积核权重和标量偏置。 就像我们之前随机初始化全连接层一样,在训练基于卷积层的模型时,我们也随机初始化卷积核权重。
-
边缘检测:如果我们只需寻找黑白边缘,那么卷积核K
[1, -1]的边缘检测器足以,垂直边缘 -
看看是否可以通过仅查看“输入-输出”对来学习由
X生成Y的卷积核。 我们先构造一个卷积层,并将其卷积核初始化为随机张量。 -
由于卷积核是从数据中学习到的,因此无论这些层执行严格的卷积运算还是互相关运算,卷积层的输出都不会受到影响。
-
输出的卷积层有时被称为特征映射(feature map),因为它可以被视为一个输入映射到下一层的空间维度的转换器。 在卷积神经网络中,对于某一层的任意元素x,其感受野(receptive field)是指在前向传播期间可能影响x计算的所有元素(来自所有先前层)。推到最前面一层的的大小。 因此,当一个特征图中的任意元素需要检测更广区域的输入特征时,我们可以构建一个更深的网络。
-
卷积的输出形状取决于输入形状和卷积核的形状。还有什么因素会影响输出的大小呢?本节我们将介绍填充(padding)和步幅(stride)。
-
有时,在应用了连续的卷积之后,我们最终得到的输出远小于输入大小。这是由于卷积核的宽度和高度通常大于1所导致的。比如,一个240×240像素的图像,经过10层5×5的卷积后,将减少到200×200像素。如此一来,原始图像的边界丢失了许多有用信息。而填充是解决此问题最有效的方法; 有时,我们可能希望大幅降低图像的宽度和高度。例如,如果我们发现原始的输入分辨率十分冗余。步幅则可以在这类情况下提供帮助。
-
填充:在应用多层卷积时,我们常常丢失边缘像素。 由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。 但随着我们应用许多连续卷积层,累积丢失的像素数就多了。 解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是0)。
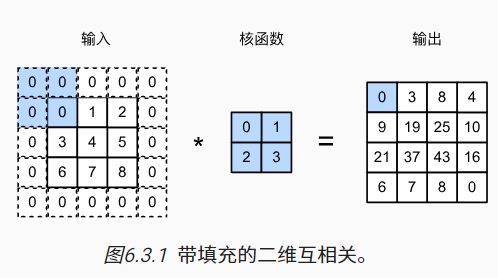
如果我们添加pℎ行填充(大约一半在顶部,一半在底部)和pw列填充(左侧大约一半,右侧一半),则输出形状将为(nℎ−kℎ+pℎ+1)×(nw−kw+pw+1)。这意味着输出的高度和宽度将分别增加pℎ和pw。
在许多情况下,我们需要设置pℎ=kℎ−1和pw=kw−1,使输入和输出具有相同的高度和宽度。 这样可以在构建网络时更容易地预测每个图层的输出形状
卷积神经网络中卷积核的高度和宽度通常为奇数,例如1、3、5或7。 选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。
此外,使用奇数的核大小和填充大小也提供了书写上的便利。对于任何二维张量
X,当满足: 1. 卷积核的大小是奇数; 2. 所有边的填充行数和列数相同; 3. 输出与输入具有相同高度和宽度 则可以得出:输出Y[i, j]是通过以输入X[i, j]为中心,与卷积核进行互相关计算得到的。 -
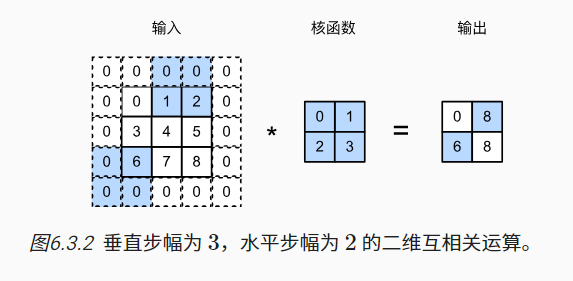
步幅:在计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动。 在前面的例子中,我们默认每次滑动一个元素。 但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。我们将每次滑动元素的数量称为步幅(stride)
垂直步幅为3,水平步幅为2的二维互相关运算。
-
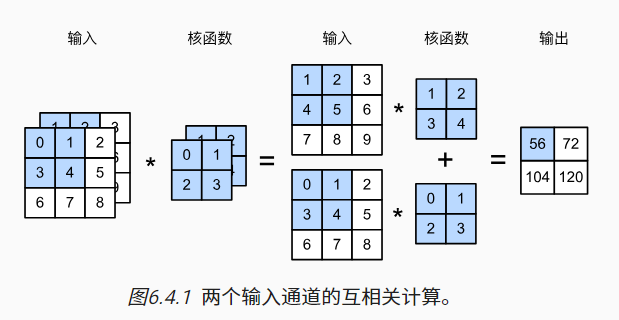
输入通道:每个RGB输入图像具有3×ℎ×w的形状。我们将这个大小为3的轴称为通道(channel)维度。
- 当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算
- 由于输入和卷积核都有ci个通道,我们可以对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和(将ci的结果相加)得到二维张量。这是多通道输入和多输入通道卷积核之间进行二维互相关运算的结果。
-
输出通道:随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。
- 用ci和co分别表示输入和输出通道的数目,并让kℎ和kw为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为ci×kℎ×kw的卷积核张量,这样卷积核的形状是co×ci×kℎ×kw。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
- ci 卷积核的通道数和输入通道数一致。co卷积核的个数与输出通道数一致。
池化:pooling,它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
- 通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大。
- 池化层通常用于降低特征图的空间分辨率,从而减少参数数量、计算量和过拟合的风险。因为池化操作通过聚合局部区域的信息来减少特征图的尺寸。降低对空间降采样表示的敏感性可以理解为使网络在进行空间降采样的同时,仍然能够保持对重要空间信息的捕捉能力。
- 池化层也称为下采样层,用于降低特征图的空间维度,减少参数数量和计算量,同时保持特征的不变性。
- 池化层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为池化窗口)遍历的每个位置计算一个输出。
- 我们通常计算池化窗口中所有元素的最大值或平均值。这些操作分别称为最大池化层(maximum pooling)和平均池化层(average pooling)
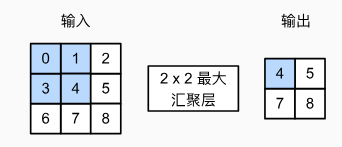
- 与卷积层一样,池化层也可以改变输出形状。和以前一样,我们可以通过填充和步幅以获得所需的输出形状。
- 默认情况下,深度学习框架中的步幅与池化窗口的大小相同。
- 在处理多通道输入数据时,池化层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总。 这意味着池化层的输出通道数与输入通道数相同。
LeNet
卷积:提取特征
卷积层的超参数:卷积核的大小,填充和步幅,通道数。。。。
填充在输入周围添加额外的行/列,来控制输出形状的减少量 步幅是每次滑动核窗口时的行/列的步长,可以成倍的减少输出形状
多输入通道:每个通道都有一个卷积核,结果是所有通道卷积结果的和
多输出通道:我们可以有多个三维卷积核,每个核生成一个输出通道
每个输出通道可以识别特定模式,输入通道核识别并组合输入中的模式。数字中的勾/横/竖(局部特征)
1×1卷积核:它不识别空间模式,只是融合通道。
使用1×1卷积核与3个输入通道和2个输出通道的互相关计算。 这里输入和输出具有相同的高度和宽度,输出中的每个元素都是从输入图像中同一位置的元素的线性组合。 我们可以将1×1卷积层看作在每个像素位置应用的全连接层,以𝑐𝑖个输入值转换为𝑐𝑜个输出值。 因为这仍然是一个卷积层,所以跨像素的权重是一致的。
池化:它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。池化层返回窗口中最大或平均值,缓解卷积层会位置的敏感性,同样有窗口大小、填充、和步幅作为超参数
Flatten:在卷积神经网络(CNN)中,经过一系列卷积层和池化层后,得到的特征图通常具有一定的高度和宽度。这些特征图包含了经过多层处理后的空间信息和特征表示。然而,全连接层无法直接处理这些具有空间结构的多维数据。Flatten操作通过重新排列特征图中的元素,将它们展平成一个长序列,从而消除特征图的空间维度,使得每个元素都按照一定的顺序排列成一个向量。
LENET-23 http://localhost:8888/notebooks/chapter_convolutional-neural-networks/lenet.ipynb
|
|
导入数据:1,2,3fashion-mnist
6个通道:用了6个5*5的卷积核。每个通道卷积核的个数决定了下一层的输入通道数
拉成一维就是摊平操作 flatten
先用卷积层来学习图片的空间信息,通过池化层来降低图片的敏感度,然后使用全连接层来转换到类别空间
torch.Size([1, 1, 28, 28]): 1-批量大小,2-通道数,3,4-高和宽
卷积:图变小通道变多。每个通道信息就相当于空间的模式。不断将空间信息压缩变小,通道数变多。把抽出来压缩的信息放在不同的通道里,最后mlp把这些模式拿出来通过多层感知机模型训练到最后的输出
课程网站有个练习是将sigmoid替换为relu,四个sigmoid全替换后模型基本不收敛,有什么原因吗?一般用relu应该比sigmoid更容易收敛?
–不收敛,lr太高了
神经网络是一种语言,来构造结构化的模型来拟合数据,抽取语义信息
|
|
Alexnet
Alexnet-深度卷积神经网络24 http://localhost:8888/notebooks/chapter_convolutional-modern/alexnet.ipynb
深度学习之前:机器学习-特征提取,选择核函数计算相关性,凸优化问题,漂亮的定理
本质上是更深更大的lenet,主要改进:丢弃法,Relu,Maxpooling
丢弃法将一些输出项随机置0来控制模型复杂度
使用更大的核窗口和步长,因为图片更大了 3×224×224
激活函数从sigmoid变到了ReLu(减缓梯度消失),隐藏全连接层后加入了丢弃层,数据增强
Author kong
LastMod 2023-03-22