Feature Selection
Contents
网络空间图像标注中半监督稀疏特征选择算法研究
Research on Semi-supervised Sparse Feature Selection for Image Annotation in Web Space
摘要
面对这些不断增加的网络空间图像数据,如何有效地对其进行浏览、检索和管理,成为当前多媒体内容理解和计算机视觉领域面临的一项亟待解决的研究问题。自动图像标注技术(Automatice Image Annotation),将关键词或者相关文档描述与图像联系起来,成为对大规模网络空间图像进行有效索引、检索、组织和管理的一个重要途径。然而,面对呈几何级数增长的网络空间图像数据,现有的自动图像标注技术面临着两个关键问题:一个是面对大规模网络空间图像,如何有效提高标注效率,另一个是如何利用大量的无标签图像来提升网络空间图像标注的准确度。
作为一种重要的手段,特征选择在网络空间图像标注中发挥着重要作用。近年,半监督稀疏特征选择成为特征选择技术中一个研究热点,它能够更好的提高网络空间图像标注的性能。本论文对现有半监督稀疏特征选择方法进行了深入研究,从稀疏表示理论、半监督学习方法以及多视图学习三个方面出发,提出了几种新的半监督稀疏特征选择算法,主要的研究成果及贡献包括:
-
提出了一种基于 l₂,½ 矩阵范数半监督稀疏特征选择算法
对新近提出的
稀疏性惩罚 l₂,p (0<p<=1)矩阵范数进行了深入研究,基于具有最好性能的稀疏性惩罚 l₂,½ 矩阵范数提出了一种新的半监督稀疏特征选择算法FSLG。l₂,½ 矩阵范数不仅考虑了不同特征之间的关联,同时具有更好的稀疏性,使提取的特征更具判别性、更加稀疏,从而可以降低计算的复杂度,提高效率。本文给出了基于矩阵范数的半监督稀疏特征选择算法框架PSLG以及详细的求解方法。将所提半监督稀疏特征选择算法FSLG应用到了网络空间图像标注任务中,提高了网络空间图像标注的性能和效率。 -
提出了一种基于Hessian正则化半监督稀疏特征选择算法
现有的半监督学习方法中最具代表性的工作是基于拉普拉斯半监督学习方法,然而图拉普拉斯正则化不具有很好的推断能力,无标签数据的几何结构信息没能被很好的利用。相对于拉普拉斯正则化,正则化可以使函数值随着测地距离线性变化更好的保持局部流形结构具有很好的推断能力,因此,
基于Hessian正则化的半监督学习具有更好的学习性能。本文将Hessian正则化引入到半监督稀疏特征选择算法中,提出了基于Hessian正则化半监督稀疏特征选择算法HFSL,给出了算法的迭代求解方法,并将其应用到了网络空间图像标注任务,结果表明所提算法能够很好的提高网络空间图像标注的性能。 -
提出了两种基于多视图学习的半监督稀疏特征选择算法
目前大多数特征选择方法都是针对单一视图(Single-view)数据的,当其面对多视图(Multi-view)数据时,一般是将多视图数据简单地串接为一个长的特征向量进行处理。然而,这种直接串接的方法不能充分利用多视图之间的互补和一致性信息,同时忽略了不同视图的物理解释。近年,多视图学习(Multi-view Learning)得到了广泛关注及研究,多视图学习可以很好的利用不同视图之间的互补属性和一致性。基于不同视图之间的互补属性,论文提出了多视图Hessian半监督稀疏特征选择算法MHSFS,基于一致性提出了基于 l₂,½ 矩阵范数和共享子空间的半监督稀疏特征选择算法SFSLS,并分别给出了两种算法的详细求解过程。将所提基于多视图学习的半监督稀疏特征选择算法应用到了网络空间图像标注任务,结果表明所提算法优于现有的半监督稀疏特征选择算法,能够提高网络空间图像标注的性能。
绪论
研究背景和意义
面对这些不断增加的网络空间图像数据,如何有效的对其进行浏览、检索和管理成为了当前多媒体内容理解和计算机视觉领域面临的一项亟待解决的热点研究问题。
自动图像标注将关键词或者相关文档描述与图像联系起来,成为了对大规模网络空间图像进行有效索引、检索、组织和管理的一个重要途径,在网络空间图像检索、家庭影集的组织和管理、媒体数据分析等方面都有广泛的应用。图像标注最初也是最直接的研究动力是为了更加方便
的进行图像检索。面对爆炸性增长的网络空间图像,图像标注在网络空间图像检索中发挥了越来越大的作用。随着互联网及数码设备的普及以及广泛应用,人们随时拍照并将图片上传到网络空间与人分享,形成了庞大的家庭影集,这对有效地组织和管理网络空间的家庭影集提出了重要的挑战。目前己经有工作尝试通过对家庭影集中的图像进行标注,以方便用户查找图像和对图像进行整理归类。另外,随着互联网社区共享网站的迅猛发展,社会媒体数据急剧增长,虽然有的用
户在上传图像数据时提供了一定的描述词,但是这些描述词比较片面或者不完整,使网络空间的媒体数据分析面临着巨大的挑战。目前己有工作利用用户提供的描述词和图像本身的特征,通过图像标注技术来更好的进行网络空间的媒体数据分析。当然,图像标注技术在其他领域也有着广泛的应用,如商标检索、医学图像检索、行为分析等。
然而,面对呈几何级数增长的网络空间图像数据,现有的自动图像标注技术面临着两个关键问题:一个是面对大规模的网络空间图像,如何提高标注效率,另一个是如何利用大量的无标签网络空间图像来提升标注的准确度。
作为一种重要的桥梁和手段,特征选择技术在网络空间图像标注中发挥着重要作用。面对大规模网络空间图像,如何有效去除冗余特征,获得更加稀疏、更具判别性的特征子集,将直接影响网络空间图像标注的准确度和效率。特征选择是指从原始特征集中选择最具判别性的特征子集,降低原始数据中的噪声干扰。选择好的特征不仅可以减小图像标注的复杂度,提升图像标注的效率,还可以提高图像标注的准确度。网络空间图像数量呈爆炸性增长,特别是其中包含大量的无标签图像。另外,随着应用领域的不断扩大,网络空间图像数据一般釆用多视图数据形式来更全面的表达图像内容。由于半监督稀疏特征选择算法能够同时利用少量有标签图像以及大量无标签图像提取更具判别性、更加稀疏的特征,从而更好的提升网络空间图像标注的性能,因此,半监
督稀疏特征选择算法成为了当前特征选择技术中研究热点。
针对不断增长的网络空间图像数据,网络空间图像标注中半监督稀疏特征选择技术能够更好的推动图像处理、多媒体内容理解、计算机视觉、模式识别以及机器学习等领域的发展,因此具有重要的理论研究价值;另外,半监督稀疏特征选择技术不仅仅是进行网络空间图像标注的一项关键技术,同时可以被广泛应用到不同的领域,如图像分类、图像检索、视频标注、行为识别等,因此,网络空间图像标注中半监督稀疏特征选择技术具有广泛的应用前景。
国内外研究概况
-
图像标注
自动图像标注将关键词或者相关文档描述与图像联系起来,成为了对大规模网络空间图像进行有效索引、检索、组织和管理的一个重要途径。自动图像标注方法可以分为三大类:基于概率模型的方法、基于图像检索的方法和基于分类的方法。
-
特征选择
根据不同的分类依据,特征选择方法可以分为传统与稀疏特征选择方法,监督、非监督和半监督 特征选择方法,以及单一视图和多视图特征选择方法。
论文主要研究工作
论文主要针对半监督稀疏特征选择算法进行了深入研究,分别从稀疏表示理论、半监督学习以及多视图学习三个方面提出了多种更加有效的半监督稀疏特征选择方法。另外,将所提半监督稀疏特征选择方法应用到网络空间图像标注任务,从而提升网络空间图像标注的性能。
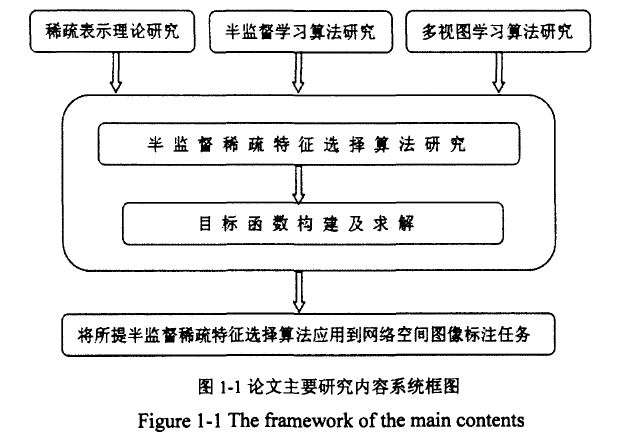
首先,针对网络空间图像数据量大、维度高的特点,对稀疏表示理论进行深入研究,将具有最好性能的稀疏性惩罚应用到半监督稀疏特征选择算法之中,使选择的特征子集更具判别性,更加稀疏,从而提升半监督稀疏特征选择算法性能。
其次,针对网络空间图像中无标签数据易于获取的特点,对现有的半监督学习算法进行深入研究,探索能够充分利用大量无标签数据的几何结构信息来提升半监督学习性能的半监督学习方法,并将其应用到半监督稀疏特征选择算法之中,从而进一步提升半监督稀疏特征选择的性能。
最后,针对网络空间图像的多视图表示形式,在特征选择算法中采用多视图学习方法进行特征选择,充分利用不同视图间的一致和互补属性来提升半监督稀疏特征选择的性能。
半监督稀疏特征选择算法研究的相关知识
图像视觉特征
图像底层视觉特征是进行图像标注和图像检索的基础和前提,底层视觉特征能够客观的表达图像内容,在一定程度上可以描述图像所表达旳意义。常用的底层图像特征包括颜色、纹理、形状等全局特征以及近年引起广泛关注的基于关键点的特征。
-
颜色特征
-
纹理特征
纹理(特征是一种统计特征,描述了图像和图像区域所对应物体的表面性质,有旋转不变性和较强的抗噪能力,常应用在检索具有粗细、疏密等有较大差别的纹理图像。提取纹理特征的方法大致分为三类:结构方法、统计方法及频谱方法。
-
形状特征
-
基于关键点的特征
基于关键点的特征通过提取图像的显著区域或关键点来灵活地描述图像的局部信息和细节内容,从而对图像缩放、旋转以及视角、光照变化有很强的鲁棒性。
稀疏表示理论
信号的稀疏表示被证明是一个用于采集、压缩和表达髙维信号有效的工具。近几年,稀疏表示理论被广泛地应用于图像处理的多个方面,如图像压缩、图像去噪、图像检索和图像识别等,成为当前国际上的一个研究热点。通过稀疏表示,图像可以釆用字典中少数原子的线性组合进行表示。稀疏表示系数和相应的原子能够很好地揭示图像的内在本质,同时,这也符合人类的视觉特性。
-
生理学基础
-
稀疏表示理论

https://blog.csdn.net/zouxy09/article/details/24971995/

-
稀疏表示求解…
不难看出,式(2-2)和(2-4)是一个组合优化问题,但是由于其非凸且高度不可微,从而导致它们的求解是一个典型的NP-hard(Nondeterministic Polynomial- time Hard)问题。正是因为这种限制的存在,研究者们提出了稀疏表示逼近算法来求解。稀疏表示逼近求解算法主要可以分为两类:贪麥算法和松弛算法。
-
字典构造…
字典构造是稀疏表示理论中另一个核心问题。字典不仅关系到图像稀疏表示的有效性,同时也影响各种稀疏表示求解算法的性能。
前最常用的是基于样本学习来构造字典,字典学习的主要任务就是从训练样本集 X={xi} 中学习出字典A,使得字典A对每个训练样本都能进行有效的稀疏表示。从数学角度上说,字典学习是寻找字典A和稀疏系数矩阵G使得它们的乘积能有效地逼近训练样本X,即 X=AG 。下面介绍几种经典的用于超完备稀疏表示的学习式字典。
- MOD字典学习
- K-SVD字典学习
- 在线字典学习算法
半监督学习
人们提出了能够同时利用少量的可靠的有标记样本和大量无标记样本的半监督学习,希望通过挖掘无标记样本所揭示的内在本质结构来提升学习的性能。
-
监督、非监督与半监督学习概述

- 监督学习
- 非监督学习
- 半监督学习
Author kong
LastMod 2022-01-26