联邦学习(Federated Learning)
Contents
简要分析
数据是属于用户的,我们既不能不作申请的使用它们,还要保护数据的私密性,有没有什么颁发安全高效的实现数据合作呢?2016年,为解决Android的更新问题,Google提出让用户在自己的设备中训练模型,以上传模型参数取代直接上传数据,一定程度上保证了个人数据的私密,这就是联邦学习的雏形。
如果联邦学习的业务参与者们业务相似,数据的特征重叠多,样本重叠少,比如不同地区的两家银行就可以通过上传参数,在服务器中聚合更新模型,再将最新的参数下放完成模型效果的提升,这被称为横向联邦学习或特征对齐的联邦学习。如果参与者的数据中样本重叠多,特征重叠少,例如同一地区的银行和电商,就需要先将样本对齐,由于不能直接比对,我们需要加密算法的帮助,让参与者不暴露不重叠的样本的情况下,找出相同的样本后联合他们的特征进行学习,这是纵向联邦学习,也被称为样本对齐的联邦学习。如果样本和特征重合都不多,希望利用数据提升模型能力,就需要将参与者的模型和数据迁移到同一空间中运算,这杯称为联邦迁移学习。联邦学习的存在目标是解决数据的协助和隐私问题。
FL举例
fl:google的keyboard suggestion打字的时候,手机会猜你想打的内容,会给你一个建议。传统的ML,需要用户把自己的数据上传到一个central server,然后这个central server有所有用户的数据之后,再来train一个prediction model 然后根据这个prediction model来predict每个用户的行为。但是,因为现在data privacy ,用户不希望上传自己的数据,希望保护自己的数据隐私,那么通过FL的一些算法,就可以使得用户不用上传自己的data,存在自己的local machine上,只通过上传一些summary statistics 最大程度上能够保证用户的隐私,与此同时通过这些summary statistics就可以train一个比较好的model,然后来做predict,可以比较准确的predict这个用户接下来的行为,然后做一些精准的推送。
train一个model,一般就是minimize一个loss function。最简单的方法就是用gradient descent(梯度下降),比如有10000个data,他们存在10个不同的local sites,那gradient descent的做法就是,先有一个initial value(初值),然后算10000个data在这个initial value上的gradient,然后再进行descent。那这10000个data的gradient就等于这10个local sites的gradient的和,所以只需要在迭代的每一步,告诉每个local site,算自己的gradient,就不需要他们的data,只需要他们的gradient,aggregated information(聚合信息)。这个central server接到10个sites的gradient之后,把它们合成起来,就可以算出global gradient,然后再update parameter(更新参数),然后再把这个parameter传给local sites,然后local sites再算gradient,这样一直循环直到这个算法converge(聚集)。不需要知道每个size的具体的data,每一步的迭代只需要一个summary statistics(总结数据)
但是是不是就保证了data privacy呢?只能说一定程度上保证了data privacy,因为从这些summary statistics里面,还是可以反推出原来的data,这就涉及到差分隐私differential privacy,对什么是数据隐私有一个严格的数学定义。比如(ε,δ)differential privacy。fl只提供了一种data privacy方法,多大程度的话还需具体推导。
fl还面临其他的一些挑战,比如数据的差异性heterogeneity。因为不同的local site data distribution(分布)不一定是一样的。如果train一个university model来predict每个data的话,在有一些local sites上面prediction performation会好,但是在另一些site上面的performance可能会差一些,有没有方法来handle这种heterogeneous data呢也是研究较多的话题。对于数据的heterogeneity情况,还是希望对于不同的data来fit不同的model,这样它的prediction performation会更好。
还有一个挑战就是关于communication efficiency(通信效率),一般这种learning method都是一种迭代的算法,在每一次的迭代过程中,都要向central server传一个summary statistics,那么怎样传才能使得这个communication更efficiency高效。
FL简而言之
传统的机器学习,需要将客户端的数据,上传至服务器进行模型训练,用户数据的隐私成为了一个大问题。在联邦学习中,服务器将训练程序下发到客户端,客户的数据就在计算梯度下降和损失,或者模型的参数并上传至服务器,服务器将来着各个客户端的数据整合,更新模型的参数,这样就完成了训练的一次迭代,经过若干次迭代后模型训练成功。
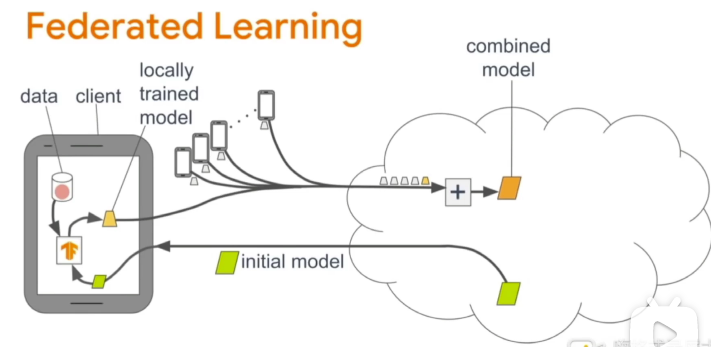
server将训练程序和模型初始化参数分发到client,client利用本地的数据进行训练,并将本地训练好的参数上传至server,server用来自不同client的模型参数的平均值,更新模型,这样就完成了一轮的训练,server会再次将更新的模型分发至client,进行新一轮的联邦学习。
联邦学习
联邦学习是一种带有隐私保护、安全加密技术的分布式机器学习框架,旨在让分散的各参与方在满足不向其他参与者披露隐私数据的前提下,协作进行机器学习的模型训练。
经典联邦学习框架的训练过程:
- 协调方建立基本模型,并将模型的基本结构和参数告知各参与方
- 各参与方利用本地数据进行模型训练,并将结果返回给协调方
- 协调方汇总个参与方的模型,构建更准确的全局模型,以提升模型训练性能和结果
联邦学习框架包含多方面的技术,比如传统机器学习的模型训练技术、协调方参数整合的算法技术、协调方参与方高效传输的通信技术、隐私保护的加密技术等。此外,在联邦学习中还存在激励机制,数据持有方可参与,收益具有普遍性。
联邦学习的架构思想
联邦学习的架构分为两种,一种是中心化联邦(客户端/服务器端),一种是去中心化联邦(对等计算)架构。
针对联合多方的联邦学习场景,一般采用的是客户端/服务器端架构,企业作为服务器,起着协调全局模型的作用。
针对联合多家面临数据孤岛困境的企业进行模拟训练的场景,一般可以采用对等架构,因为难以从多家企业中选出进行协调的服务器方。
在客户端服务器端架构中,各参与方与中央服务器合作进行联合训练。在正式开始训练之前,中央服务器先将初始模型分发给各参与方,然后各参与方根据本地数据集分别对所得训练模型进行训练。接着,各参与方将本地训练得到的模型参数加密上传至中央服务器。中央服务器对所有模型梯度进行聚合,再将聚合后的全局模型参数加密传回至各参与方。
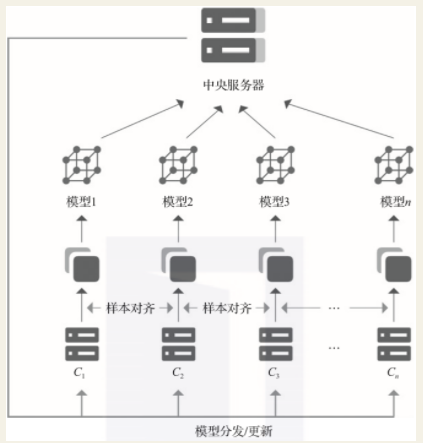
在对等计算架构中,不存在中央服务器,所有交互都是参与方之间直接进行的。当参与方对原始模型训练后,需要将本地模型参数加密传输给其余参与联合训练的数据持有方。因此,假设本次联合训练有n个参与方,则每个参与方至少需要传输2(n-1)次加密模型参数。在对等架构中,所有模型参数的交互都是加密的。目前,可采用安全多方计算、同态加密等技术实现。全局模型参数的更新可运用联邦平均等聚合算法,当需要对参与方数据进行对齐时,可采用样本对齐等方案。
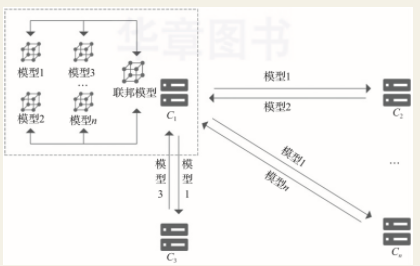
联邦学习的应用场景
根据各方数据集的贡献方式不同,可以将联邦学习具体分为横向联邦学习、纵向联邦学习和联邦迁移学习。
横向联邦学习:适用于各数据持有方的业务类型相似、所获得的用户特征多而用户空间只有较少重叠或基本无重叠的场景。各地区不同的商场拥有的客户的购物信息大多类似,但是用户人群不同。横向联邦学习以数据的特征维度为导向,取参与方特征相同而用户不完全相同的部分进行联合训练。在此工程中,通过各参与方之间的样本联合,扩大了训练的样本空间 ,从而提升了模型的准确度的泛化能力。
纵向联邦学习:纵向联邦学习适用于各参与方之间空间重叠较多,而特征空间重叠较少或没有重叠的场景。例如,某地区的银行和商场,由于地理位置类似,用户空间交叉较多,但因为业务类型不同,用户的特征相差较大。纵向联邦学习是以共同用户为数据的对齐导向,取参与方用户相同而特征不完全相同的部分进行联合训练。因此,联合训练时,需要先对各参与方数据进行样本对齐,获得用户重叠的数据,然后各自在被选出的训练集上进行训练。此外,为了保证非交叉部分数据的安全性,在系统级进行样本对齐操作,每个参与方只有基于本地数据训练的模型。
联邦迁移学习:联邦迁移学习是对横向和纵向的补充,适用于各参与方用户空间和特征空间都重叠较少的场景。例如,不同地区的银行和商场之间,用户空间交叉较少,并且特征空间基本无重叠。在该场景下,采用横向可能会产生比单独训练更差的模型,采用纵向可能会产生负迁移的情况。联邦迁移学习基于各参与方数据或模型之间的相似性,将在源域中学习的模型迁移到目标域中。大多采用源域中的标签来预测目标域中的标签准确性。
联邦学习的优势和前景
分布式机器学习框架通过集中收集数据,再将数据进行分布式存储,将任务分散到多个CPU/GPU机器上进行处理,从而提高计算效率。与之不同的是,联邦学习强调将数据一开始就保存在参与方本地,并且在训练过程中加入隐私保护技术,拥有更好的隐私保护特性。
各参与方的数据一直保存在本地,在建模过程中,各方的数据库依然独立存在,而联合训练时进行的参数交互也是经过加密的,各方通信时采用严格的加密算法,难以泄露原始数据的相关信息,因而联邦学习保证了数据的安全与隐私。
此外,联邦学习技术可使分布式训练获得的模型效果与传统中心式训练效果相差无几,训练出的全局模型几乎是无损的,各参与方能够共同获益。
在大数据与人工智能快速发展的当下,联邦学习解决了人工智能模型训练中各方数据不可用、隐私泄露等问题,因而应用前景十分广阔。联邦学习可用于在海量数据集下的模型训练,实现部门、企业及组织之间的联动。例如:
- 在智慧金融领域中,可以根据多方数据建立更准确的业务模型,从而实现合理定价、定向业务推广、企业风控评定等;
- 在智慧城市中,实现各政府机构之间、企业与政府之间的联合,实现更准确的实时交通预测,更简化的机关办事步骤,更高效的信息内容查询,更全面的安全防控检测等;
- 在智慧医疗中,联邦学习可以综合各医院之间的数据,提高医疗影像诊断的准确性,预警病人的身体情况等。
联邦学习王树森

联邦学习是分布式学习的一种
由于2.3,设计联邦学习算法的时候,最重要的是减少通信的次数。
研究方向:
-
通信效率:用新的算法算出更好的下降方向,需要更少的迭代次数并行梯度下降:server把模型参数分发给每个worker结点。worker接收到参数w,然后用w和本地数据计算梯度gi,然后发送给server。server接收到所有的worker发来的梯度后,把所有的梯度求和得到梯度g,然后server作梯度下降更新参数w<-w-αg。α指步长或者学习率。然后进行下一轮迭代。直到算法收敛。
Federated Averaging Algorithm:server把参数发给worker结点。worker结点接收到w之后,重复(w和local data计算g,在本地作梯度下降w<-w-αg)1-5个epoch,把wi~=w发送给server。server接收到全部的wi~之后,做一个平均或者是加权平均。
相同次数的通信,fedavg收敛的更快。相同次数的epochs,fedavg的损失函数大于梯度下降的,即意味着worker结点做相同数量的计算fedavg收敛的更慢。即说明减少了通信量,但是增加了worker结点的计算量。

(1)第一个提出FL,只有算法和实验,没有理论分析。
(2)证明的fedavg确实可以收敛,而且通信量要比随机梯度下降要小,但是假设数据是独立同分布的IID。但FL基本假设数据不是IID,non-IID。
(3)证明fedavg收敛而且不需要独立同分布的假设。
(4)类似3
-
隐私保护:用户的数据被间接的泄露出去。随机梯度是用户本地一个batch的数据计算出来的,算梯度的时候实际就是用一个函数将本地的数据做一个函数变换。将数据映射到了梯度。
以最小二乘回归为例。损失函数l,数据xi和模型参数w的内积减去标签yi求平方。随机梯度gi是l对w的偏导。实际上随机梯度相当于对数据xi进行了一个放缩。梯度几乎携带了所有的数据信息,从梯度是可以反推出数据信息的。
保护隐私:首先想到differential privacy(差分隐私),加噪声。通常是往梯度里加噪声,可是实验证明加噪声不够,还是能反推出用户数据。噪声太强了,学习的过程就进行不下去了,损失函数不再往下降。。。但如今确实很多文章利用差分隐私去实现fl隐私保护。

(1)(3)用模型参数或者梯度来反推出用户的隐私数据。
(1):得到梯度就可以推出用户数据的一些属性,比如性别,种族,年龄。。把一个用户的梯度作为输入的特征向量,然后用一个分类器来判断用户的属性。
-
鲁棒性robust:让FL可以抵御拜占庭错误,和恶意的攻击。拜占庭将军问题:针对的是分布式系统中出现异常结点的情况。我们一起去攻城,但是有一个叛徒忽悠我们,让我们去执行错误的战术,导致被团灭。FL中有一个结点故意使坏,把自己的数据和标签做修改,那么给server的梯度就是有害的,可能会让学到的模型犯错误。

多个用户参与联邦学习,可能其中会出现叛徒,这些叛徒可以对FL进行多种多样的攻击,可以让学习变慢,也可以让学习变差,可以让学习到的模型有个后门。FL存在一些潜在的风险。
联邦学习有这几个方向可以研究,做得好了肯定可以在顶会上发论文:
- 降低算法通信次数,用少量的通信达到收敛。数据是IID的,已经被研究比较透彻了。联邦学习的困难在于数据不是IID的。
- 研究联邦学习中的隐私问题。联邦学习其实不会保护隐私,很容易从梯度、模型参数中反推出用户数据。提出攻击和防御的方法都可以发表出论文。
- 研究联邦学习的鲁棒性。比如有节点恶意发送错误的梯度给服务器,让训练的模型变差。设计新的攻击方法和防御方法都可以发表出来论文。
相关文献:
https://baijiahao.baidu.com/s?id=1688157460145615660&wfr=spider&for=pc
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/118390389
Author kong
LastMod 2021-12-20