FedMVT
Contents
Semi-supervised Vertical Federated Learning with MultiView Training
FedMVT:带多视图训练的半监督纵向联邦学习
Abstract
纵向联邦学习(VFL)使各方能够基于相同样本的分布特征构建健壮的共享机器学习模型。然而,VFL要求各方共享足够数量的重叠样本(同地区的银行和商场)。 实际上,重叠样本集可能很小,导致大多数非重叠数据未使用。 在本文中,我们提出了联邦多视图训练(FedMVT),这是一种半监督学习方法,可以在有限的重叠样本下提高VFL的性能。 FedMVT估计缺失特征的表示,预测无标记样本的伪标签,以扩展训练集,并根据输入的不同视图联合训练三个分类器,以提高模型的表示学习。
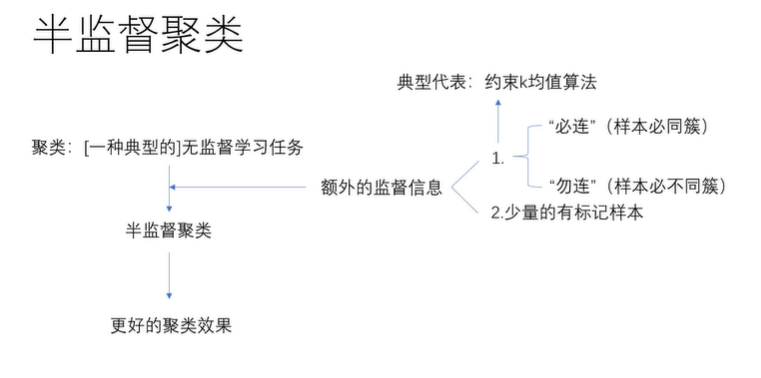
semi-supervised Learning:半监督学习,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。让学习器不依赖外界交互、自动利用未标记样本来提升学习性能的学习方法。
- 场景:传统的学习方式是大量的贴标签数据进行分类学习。但由于资源有限,只有少量的有标签的数据和大量的无标签数据时,就要用到半监督学习。
- 前提:做一些未标记样本所揭示的数据分布信息与类别标记相联系的假设。基本假设:相似的样本有相似的输出,聚类假设,流形假设。
- 分类:纯(pure)半监督学习,假设训练数据中的未标记样本并非预测的数据,学得模型适用于训练过程未观察到的数据。直推学习(transductive learning),假定学习过程中的未标记样本恰是带预测数据,只预测学习过程观察到的未标记数据。

Pseudo-Labelling:伪标签。粗略来讲,伪标签技术就是利用在已标注数据所训练的模型在未标注的数据上进行预测,根据预测结果对样本进行筛选,再次输入模型中进行训练的一个过程。
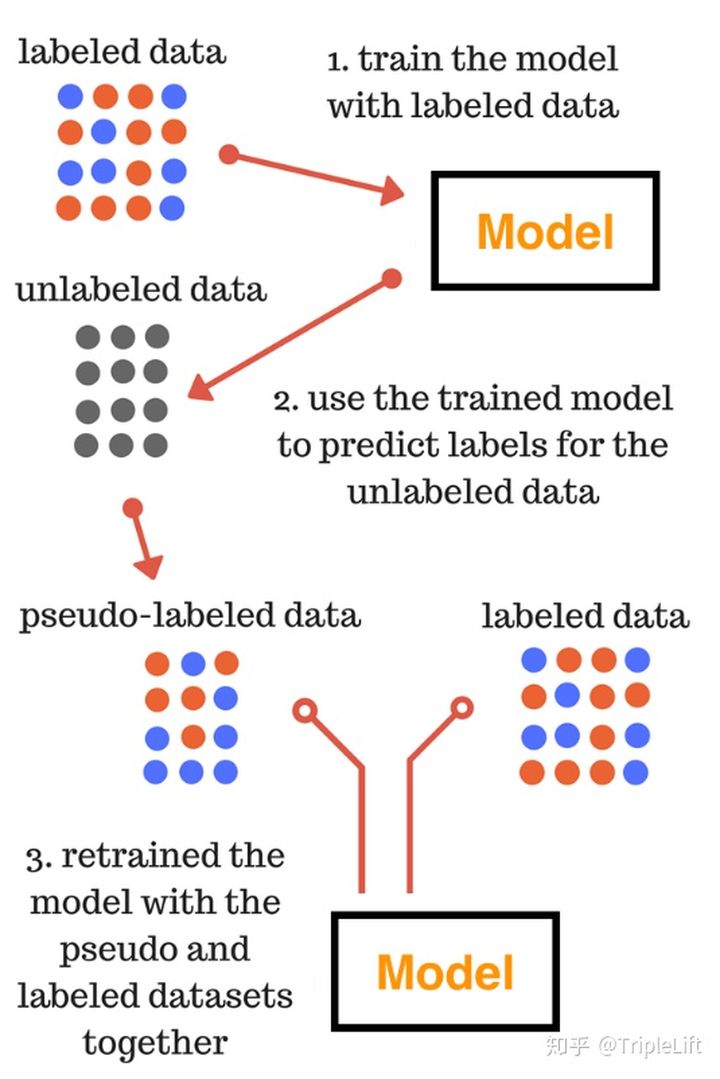
具体用法:
-
1. 使用标记数据训练有监督模型M
2. 使用有监督模型M对无标签数据进行预测,得出预测概率P
3. 通过预测概率P筛选高置信度样本
4. 使用有标记数据以及伪标签数据训练新模型M’
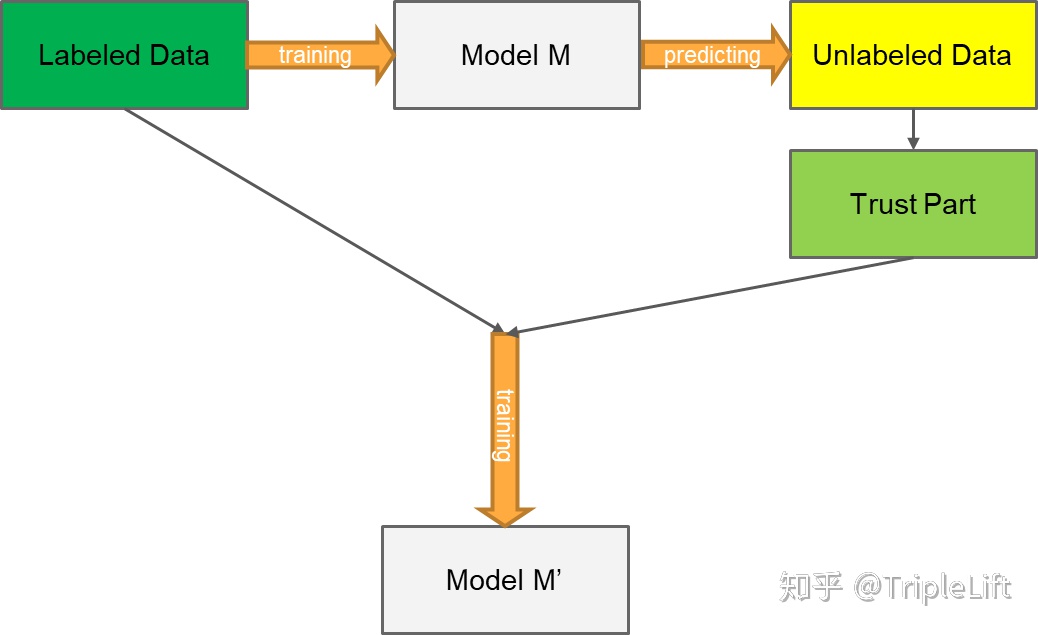
-
1. 使用标记数据训练有监督模型M
2. 使用有监督模型M对无标签数据进行预测,得出预测概率P
3. 通过预测概率P筛选高置信度样本
4. 使用有标记数据以及伪标签数据训练新模型M’
5. 将M替换为M’,重复以上步骤直至模型效果不出现提升
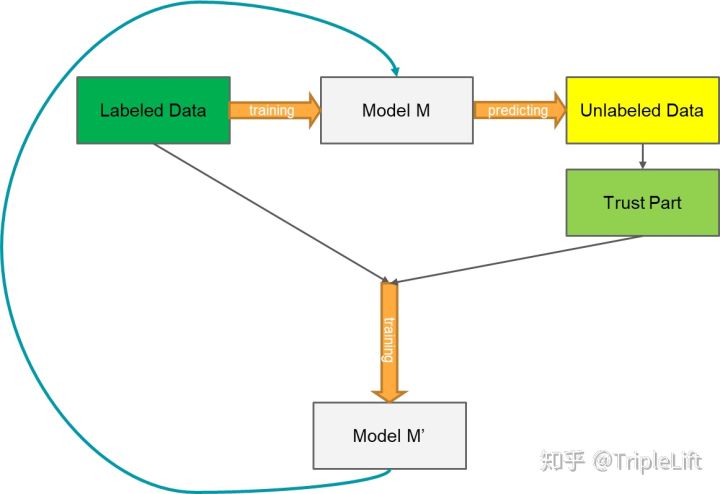
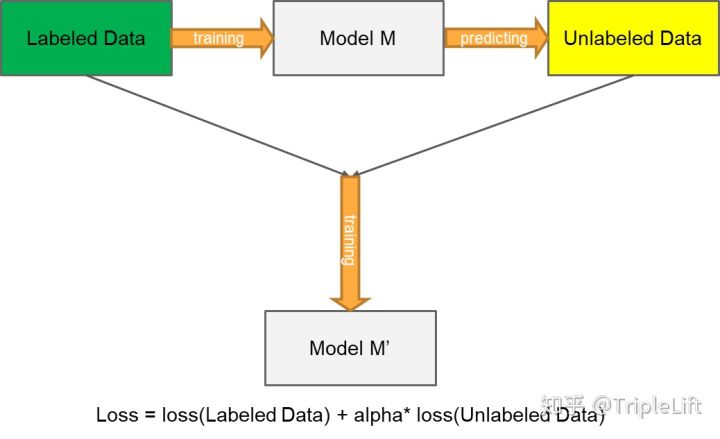
-
1. 使用标记数据训练有监督模型M
2. 使用有监督模型M对无标签数据进行预测,得出预测概率P
3. 将模型损失函数改为Loss = loss(labeled_data) + alpha*loss(unlabeled_data)
4. 使用有标记数据以及伪标签数据训练新模型M’
伪标签为何有用?
-
根据聚类假设(cluster assumption),这些概率较高的点,通常在相同类别的可能性较大,所以其pseudo-label是可信度非常高的。(合理性)
-
熵正则化是在最大后验估计框架内从未标记数据中获取信息的一种方法,通过最小化未标记数据的类概率的条件熵,促进了类之间的低密度分离,而无需对密度进行任何建模,通过熵正则化与伪标签具有相同的作用效果,都是希望利用未标签数据的分布的重叠程度的信息。(有效性)
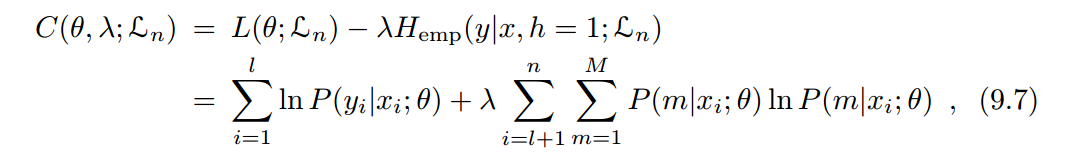
-
值得注意的是:当场景不满足 聚类假设 、熵正则化失效(样本空间覆盖密集)情况下,伪标签技术很有可能失效。在用之前判断适用条件,对症下药,才能将伪标签这把匕首的作用发挥出来。
Introduction
联邦学习的实践已经从基于数百万移动设备中的数据构建强大的移动应用程序扩展到解决组织之间或组织内部的数据碎片和隔离问题。例如,银行的许多业务决策可能依赖于其客户的购买偏好。该银行可能与拥有当地居民购买偏好数据的当地零售公司共享一些客户。因此,银行可以邀请零售公司合作构建一个共享模型,利用双方的数据功能来改善其业务。零售公司也可以从共享模式中受益。
垂直联邦学习(VFL),使参与方能够通过充分利用其重叠样本的分散特征而不公开数据来协作训练机器学习模型。然而,VFL的一个关键先决条件是,它要求各方共享足够数量的重叠样本,以实现良好的性能。 [Liu等人,2018]提出了一个联邦迁移学习框架,以解决VFL设置中的监督薄弱(标签较少)问题。 它并没有利用所有标记数据进行监督训练,也没有充分利用未标记样本来提高学习质量。 许多其他类似的方法,如领域自适应和知识蒸馏,已经应用于联邦学习环境中。然而,它们主要关注各方共享相同特征空间的场景(也称为水平联邦学习)
在本文中,我们提出了一种新的VFL环境下的半监督算法,称为FedMVT,以解决现有垂直联邦学习方法的局限性。
- 当各方之间的重叠样本有限时,FedMVT显著提高了联邦模型的性能;
- FedMVT有助于提高拥有标签方的本地分类器的性能,从而使该方更有信心地进行本地预测;
- FedMVT处理各种类型的数据。这在实践中很重要,因为现实中的VFL应用程序经常需要处理异构特性;
- FedMVT不要求参与者共享其原始数据和模型参数,只要求中间表示和梯度,而FATE实现的VFL-DNN(深度神经网络)框架可以进一步保护这一点。
Related Work
- Vertical Federated Learning (VFL).垂直联邦学习。
VFL在一些文献中也称为特征分割机器学习。
在特征空间中划分数据的安全线性机器学习在[Gascón等人,2016]中得到了很好的研究;他们使用混合MPC(安全多方计算)协议或加性同态加密来进行安全线性模型训练。Cheng et al.,2019]在VFL设置中提出了一种安全的联合树增强(SecureBoost)方法,该方法使具有不同功能的参与方能够协作构建一组增强树,并且他们证明SecureBoost提供了与其非隐私保护的集中式对等方相同的准确度。FATE设计并实现了一个VFL-DNN(深度神经网络)框架,该框架支持VFL设置中的DNN。VFL-DNN在VFL训练过程的前阶段和后阶段利用一种混合加密方案来保护数据隐私和模型安全。[Vepakomma et al.,2018]提出了几种分离深层神经网络的配置,以支持健康实体之间的各种形式的协作,每个健康实体都拥有一个部分深层网络并拥有不同的患者数据模式。
SecureBoosthttps://blog.csdn.net/u013714645/article/details/104821958
https://zhuanlan.zhihu.com/p/114461884
- Semi-supervised Learning (SSL).半监督学习
SSL旨在通过允许模型利用未标记的数据来缓解对大量标记数据的需求。 许多最近的半监督学习方法使用transfer learning迁移学习[Pan等人,2010年]、consistency regularization一致性正则化[Tarvainen和Valpola,2017年;Laine和Aila,2017年]或pseudo-labeling 伪标签[hyun Lee,2013年;Clark等人,2018年]从未标记数据中学习。[Berthelot et al.,2019]提出了混合匹配,它统一了三种主要的半监督方法:熵最小化[Grandvalet and Bengio,2004],一致性正则化和一般正则化。 他们证明,混合匹配可以接近完全监督训练所获得的错误率,数据量明显减少。 [Clark et al.,2018]提出了一种半监督交叉视图训练(CVT)方法,该方法基于所有标记数据和多个只看到未标记数据受限视图的辅助模型,同时训练完整模型。 在训练期间,CVT辅助模型匹配完整模型的预测,以改进representation learning(表示学习),进而改进完整模型。 [Liu等人,2018]提出了一个安全的联邦迁移学习(FTL)框架,这是第一个使VFL能够从转移学习中获益的框架。 FTL利用源域丰富的标签资源,帮助目标域中的一方建立预测模型。
Problem Definition
party A having dataset DA := {(x^A,i, y^A,i)}^(N^A) _i=1
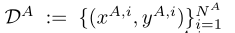
-
x^A,i∈ R^a 是第i个样本的特征
-
y^A,i∈ {0, 1}^C 是对应于x的一个复数C类,对应的one-hot encoding ground-truth 标签。
one-hot encoding:(独热编码)。离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码。独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。1 2 3自然状态码为:000,001,010,011,100,101 独热编码为:000001,000010,000100,001000,010000,100000ground-truth:大概的意思就是参考答案或参考标准或真实值的意思。比如,在有监督的学习中,数据通常是(data, label),其中label表示的就是data的标签,也就是预测时需要进行对比的真实值
party B having DB := {x^B,i}^(N^B) _i=1,x^B,i∈ R^a
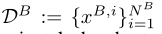
DA和DB由双方私下持有,不得相互接触。N A和N B分别是DA和DB的样本数。
我们假设双方之间存在一组有限的重叠样本Dol,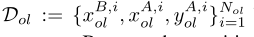 ,其中分区DBol为乙方所有,
,其中分区DBol为乙方所有,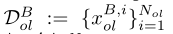 ,其余DAol为甲方所有,
,其余DAol为甲方所有,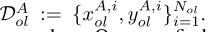 。Nol为重叠样本数。人们可以在隐私保护设置中通过加密实体对齐技术找到重叠样本集[Nock等人,2018]。在此,我们假设甲乙双方已经找到或知道重叠样本的id。我们表示DAnl为甲方非重叠样本,
。Nol为重叠样本数。人们可以在隐私保护设置中通过加密实体对齐技术找到重叠样本集[Nock等人,2018]。在此,我们假设甲乙双方已经找到或知道重叠样本的id。我们表示DAnl为甲方非重叠样本,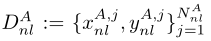 ,DBnl为乙方非重叠样本,
,DBnl为乙方非重叠样本,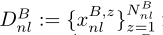 。
。
如果我们在一个表格视图中将DA和DB连接为一个大的虚拟数据集,那么这个虚拟数据集是垂直分区的,并且每一方都拥有这个数据集的一个垂直分区。这就是“纵向联邦学习”一词的由来。图中显示了由A和B两方拥有的垂直分区虚拟数据集的表格视图。
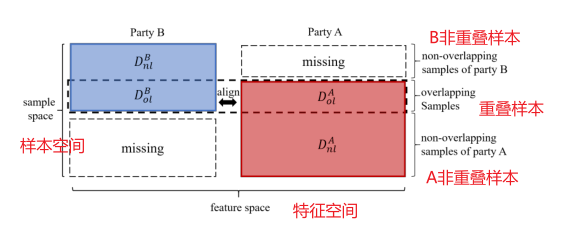
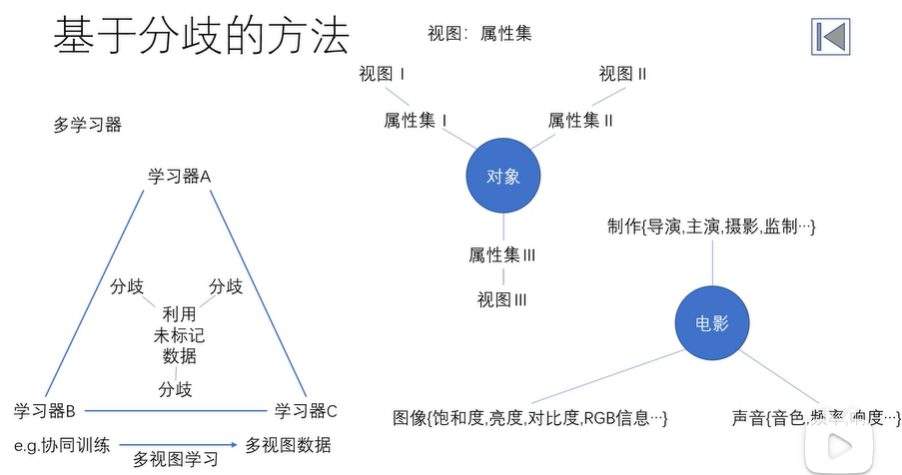
普通的VFL试图建立一个联邦机器学习模型,只使用重叠的样本Dol,而不使用不重叠的样本DAnl和DBnl。因此,提出一种带多视图训练的半监督VFL(FedMVT)方法,该方法不仅充分利用所有可用数据,还估计缺失特征的表示(如图1所示),不仅显著提高联邦模型的性能,而且有助于提高甲方本地模型的性能。
The Proposed Approach
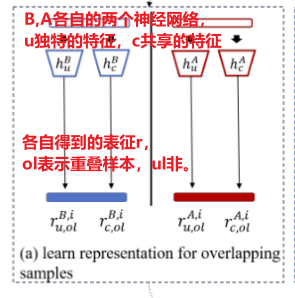
深度神经网络已被广泛用于表征学习。对于每一方,我们利用两个神经网络从原始输入数据学习特征表示。一种是学习双方之间弱共享的特征表示hpu,另一种是学习双方独有的特征表示hpc。
表征学习(representation learning、feature learning)是指自动的从原始数据中学习、提炼数据特征的一类技术或者方法。比如,深度学习就是表征学习的一种方法,深度神经网络中间隐层的输出结果就是原始数据的抽象特征。再比如,PCA 可以将高维数据映射到低维空间,也可以作为表征学习的一种方法。
更具体地说,我们表示用rpu,作为独特的特征表示,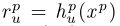 。rpc作为共享特征表示,
。rpc作为共享特征表示,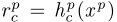 ,分别在p∈{A, B}中通过神经网络hpu和hpc学习的特征xp,
,分别在p∈{A, B}中通过神经网络hpu和hpc学习的特征xp,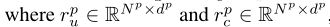 ,dp是p方神经网络的上隐表示层的维数。然后,xp的完整特征表示表示为rp = [rpu;rpc],其中[;]是沿特征轴连接两个矩阵的连接运算符。
,dp是p方神经网络的上隐表示层的维数。然后,xp的完整特征表示表示为rp = [rpu;rpc],其中[;]是沿特征轴连接两个矩阵的连接运算符。
为了方便起见,我们将rp u,ol和rp c,ol表示为从p∈ {A,B} 方的重叠样本xp ol中学习到的特征表示。而rp-u,nl和rp-c,nl作为非重叠样本xp-nl的特征表示。相应地,xp ol和xp ul的完整特征表示分别表示为rp ol=[rp u,ol;rp c,ol]和rp nl=[rp u,nl;rp c,nl]。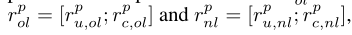 .
.
大概就是先按照特征进行区分(独特的特征u和共享的特征c),然后通过两个不同的神经网络(hpu,hpc)进行表征学习,得到表征rpu和rpc,而表征又可以分为重叠样本ol和非重叠样本nl的表征。
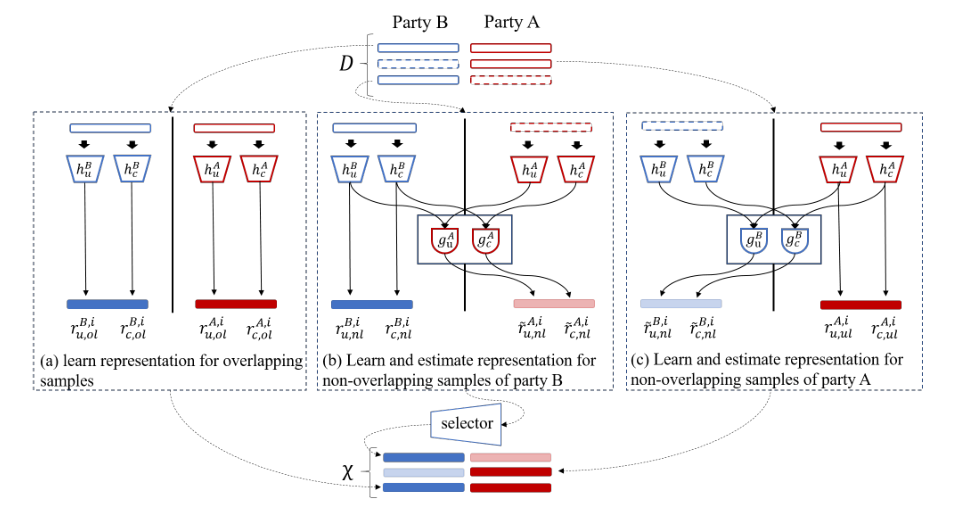
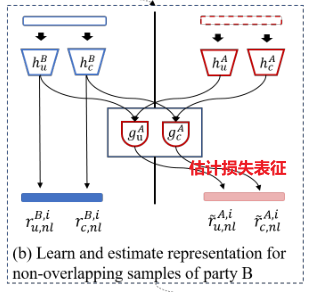
学习图,从D中的原始特征中估计和选择表示,然后形成一个扩大的训练集χ。(a)从甲乙双方的重叠样本中表征学习。(b)从乙方的非重叠样本中学习表征,并估计甲方对应缺失特征的表征(红线虚线部分)。(c)从甲方的非重叠样本中学习表征,并估计乙方对应缺失特征(蓝虚线的条带)的表征。
 ,
,
直观地说,h pc的目标是捕获双方之间的共同特征表示,而h pu则帮助学习特定领域的表示。
我们提出以下三个损失项来加强神经网络学习所需的表示(1)(2)(3)。。。通过最小化(1),推入神经网络hAc和hBc,从双方的原始数据中学习共同的特征表示。(2)、(3)为正交约束,鼓励属于p∈{A, B}的神经网络hpc和hpu学习不同的特征表示。
受多视图学习的启发[Clark等人,2018]在模型之间共享表征,并改善模型的表征学习,我们联合训练三个softmax分类器f A、f B和f AB,每个分类器都以从虚拟数据集的不同视图学习的特征表示作为输入(图1),并输出估计的类分布。在4.1和4.2节中,我们将详细阐述如何估计缺失特征的表示,并为未标记的样本确定伪标签。
Feature Representation Estimation
特征表示估计
我们通过采用缩放的点积注意函数估计虚拟数据集(图1)中缺失特征的表示。我们通过估算甲方中缺失特征的表示的过程来解释估算是如何计算出来的。
式(8)估计共享表示,记为r~A,i c,对于甲方的缺失特征,与乙方第i个样本xB,i对应,利用共享特征表示从xB,i 中学习rB,i c ,从xA中学习的和rAc 。直观地,gAc可以被解释为一个搜索引擎,由乙方给出rB,i c,它在甲方中给出了属于 r~A,i c 的结果。–>根据共享的表征估计甲方损失的表征
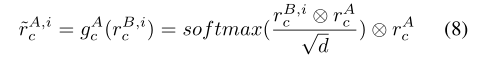
我们应用公式(9)估计独特的表示,记为 r~A,i u,对于甲方第i个特征xB,i对应的缺失特征,乙方利用独特的特征表示rB,i u ,rB u,ol从乙方的xB,i和xB ol学习到,而rA u,ol则从甲方的xA ol学习到。–>独特的表征估计
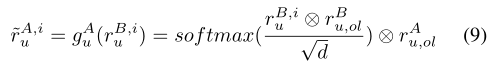
由此,我们分别得到A方和B方缺失特征估计的表示rAnl和rBnl,并构造扩大训练集χ。由以下三部分组成: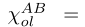
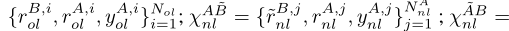
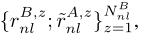
其中,χ AB ol是从A和B的重叠样本中学习到的;χ AB~ nl从甲方的非重叠样本中学习,并估计出乙方相应缺失特征的表示。χ AB ol and χ AB~ nl在甲方有ground-truth标签,而χ A~B nl没有标签。我们将在下面估计χ A~B nl中的标签。
Pseudo-label Prediction
伪标签
应用训练好的softmax分类器fA、fB和f AB分别为χ A~B nl中每个未标记的样本产生三个候选伪标签,只有当三个候选伪标签中至少有两个是相等的,并且它们的概率高于预定义的阈值t时,我们才将这个伪标签样本添加到训练集中。当χ内所有样本均有标签时,f A、f B和f AB分别在训练集上接受χ Aol +nl、χBol+nl和χ的训练。
算法1概述了完整的FedMVT算法,其中concat函数沿特征轴连接输入矩阵,而combine函数沿样本轴连接输入矩阵。
Security Analysis
FedMVT不要求各方共享其原始数据和模型参数,而只要求中间表示和梯度。中间表示是原始特征通过具有多层转换函数的深度神经网络转换的结果。因此,另一方几乎没有机会对原始特征进行逆向工程。最近,有很多关于通过梯度泄露隐私的潜在风险的讨论。为了防止中间表示和梯度被暴露,FATE设计并实现了一个VFL- dnn(深度神经网络)框架,该框架可以在VFL训练过程的前阶段和后阶段有效地执行加密。为了实验方便,我们没有使用FATE来实现FedMVT。然而,FedMVT与VFL-DNN框架兼容,可以轻松迁移到FATE。
Conclusion
我们提出了联邦多视图训练(federalmultiview Training, FedMVT),这是一种半监督学习方法,可以在有限重叠样本的情况下提高VFL的性能。FedMVT利用特征表示估计和伪标签预测来扩展训练集,并联合训练三个分类器来提高模型的表示学习。FedMVT不仅显著提高了VFL中联邦模型的性能,而且提高了标签方的本地模型的性能。
Author kong
LastMod 2022-01-02