域适应联邦学习
Contents
域适应
blog:[1]
在迁移学习中, 当源域和目标的数据分布不同 ,但两个任务相同时,这种特殊的迁移学习叫做域适应 (Domain Adaptation,DA )。因为其任务相同,域适应属于一种直推式迁移学习。
另一方面,如果你没有为特定问题提供手动注释的大型数据集,卷积神经网络还允许利用已经通过迁移学习训练一个类似问题的网络的其他数据集。在这种情况下,你可以使用一个在大型数据集上预训练的网络,并使用你自己的带注释的小型数据集对其一些上层进行调优。
假定你的训练数据(无论大小)都代表了基本分布。但是,如果测试时的输入与训练数据有显著差异,那么模型的性能可能不会很好。在这些场景中表现不佳的原因是问题域发生了变化。
在这种特殊情况下,输入数据的域发生了变化,而任务域(标签)保持不变。在其他情况下,你可能希望使用来自相同域的数据(针对相同的基本分布绘制)来完成新任务。同样,输入域和任务域可以同时发生变化。在这些情况下,域适应 就会来拯救你。域适应是机器学习的一个子学科,它处理的 场景是,在不同(但相关)的目标分布的背景下,使用在源分布上训练的模型。通常,域适应使用一个或多个源域中的标记数据来解决目标域中的新任务。因此,源域和目标域之间的关联程度通常决定了适应的成功程度。
类别
域适应有多种方法。在“浅层(不是深度)”域适应中,通常使用两种方法:重新加权源样本,在重新加权样本上进行训练,并尝试 学习共享空间来匹配 源和目标数据集的 分布。虽然这些技术也可以应用于深度学习,深度神经网络 学习的深度特征,通常会产生更多的可转移表示。
作者区分不同类型的域适应,取决于任务的复杂性、可用的标记 / 未标记数据的数量以及输入特征空间的差异。它们特别定义了域适应问题,即任务空间相同,区别仅在与输入域的散度(divergence)。根据这个定义,域适应可以是同构(homogeneous)的(输入特征空间相同,但数据分布不同),也可以是异构(heterogeneous)的(特征空间及其维度可能不同)。
根据你从目标域获得的数据,域适应可以进一步分类为 监督(supervised)域适应(你确实标记了来自目标域的数据,尽管这些数据的数量,对于训练整个模型来说还是太小了)、半监督(semi-supervised)域适应(你既有已标记的数据,也有未标记的数据)、无监督(unsupervised)域适应(你没有来自目标域的任何标记数据)。
任务相关性
我们如何确定在源域中训练的模型是否可以适应我们的目标域呢?
如果两个任务都使用相同的特征进行决策,我们就可以将它们定义为相似的任务。另一种可能性是,如果两个任务的参数向量(即分类边界)很接近,则将它们定义为相似的。
如果两个任务的数据都可以通过一组变换 F 从固定的概率分布中生成,则这两个任务是 F 相关的。
尽管有这些理论上的考虑,但在实践中,可能有必要尝试在自己的数据集上进行域适应,看看是否可以通过使用源任务的模型为目标任务获得一些好处。通常,任务相关性可以通过简单的推理来确定,例如来自不同视角或不同光照条件的图像,或者在医学领域中来自不同设备的图像等。
三种基本技术
基于散度的域适应
基于散度的域适应,通过 最小化源和目标数据分布之间的散度准则来实现,从而实现 域不变的特征表示。如果我们找到这样一种特征表示,分类器将能够在这两个域上执行得同样好。当然,这是假设存在这样一种表示,而这种表示又假设任务以某种方式相关。
最常用的四种散度度量是:最大均值差异(Maximum Mean Discrepancy,MMD)、相关对齐(Correlation Alignment,CORAL)、对比域差异(Contrastive Domain Discrepancy,CCD)和 Wasserstein 度量。
基于对抗的域适应
这种技术是尝试通过对抗训练来实现域适应。
一种方法是使用 生成对抗网络 来生成与源域相关的合成目标数据(例如通过保留标签)。然后将这些合成数据用来训练目标模型。
基于重建的域适应
域适应 联邦学习
联邦学习➕域自适应 源域和目标域 目标域是无标签的也就是无监督学习 迁移学习 目标域上迁移精度≤源域上的损失+源域和目标域上的特征距离(源域和目标域的特征分布对齐) 对齐:MMD距离(计算分布距离,取一个batch的目标域和源域映射到特征空间计算距离,要求最小化距离 问题:需要源域和目标域的数据–Fl 源域和目标域的数据保存在本地 同时迁移学习也是一种noiid问题(源域和目标域) —联邦迁移学习 如何对齐?通信损失和隐私安全?负迁移问题(每个源域的贡献大小? 不考虑目标域源域,将目标域扩展成同等地位源域,在源域上做联邦学习,信息共享,完成对没有标注的目标域的知识迁移其实也就和之前的联邦半监督学习的场景很类似,一部分客户端有标签,一部分没有。
Federated Adversarial Domain Adaptation
目标域作为服务器端模型
联邦学习背后的主要思想是让每个节点学习自己的本地数据,而不共享数据或模型参数。 虽然联邦学习承诺更好的隐私和效率,但现有方法忽略了每个节点上的数据以非独立同分布的方式收集的事实,导致节点之间的domain shift(邻域偏移)。 例如,一台设备可能主要在室内拍照,而另一台设备主要在室外拍照。
本文解决了将知识从分散节点转移到具有不同数据域的新节点的问题,而不需要用户的任何额外监督。 文章定义了这个新问题:无监督联邦领域自适应 (UFDA)
联邦设置提出了几个额外的挑战:
- 首先,数据存储在本地,无法共享,这阻碍了主流领域适应方法,因为它们需要访问标记的源数据和未标记的目标数据;
- 其次,模型参数针对每个节点分别进行训练,并以不同的速度收敛,同时还根据两个域的接近程度为目标节点提供不同的贡献;
- 最后,从源域节点学习到的知识是高度耦合的entangled,这可能会导致负迁移。
disentanglement:解耦 一句话概括就是:解耦的特征中,每一个维度都表示具体的、不相干的意义。其中最重要的是要让学到的表征具备人类可理解的意义。但是最核心且不变的诉求是要让表征可读!
- 一个问题,或者数据集中,一定存在某种控制它们的变量(因子)。每一个变量都独立地影响结果。人有五官,它们都对容貌产生影响并且相互独立。嘴巴歪了和眼睛歪不歪没有关系。但是当我们得到一张人脸的照片时,所有的这些因子都被隐含在图片上,我们不再能直接获取这些因子。这个时候,我们说因子耦合了。我们所有的观察(observation)都是耦合的结果。因为没有耦合就没有变量,没有变量也就没有不同。所以
解耦的目的就是把这些耦合了的变量重新拆开。解耦可以理解为某种程度上的降维。
Feature Disentanglement:特征解耦
团队针对上述问题提出了一种称为联邦对抗域适应 (Federated Adversarial Domain Adaptation, FADA) 的解决方案,旨在通过对抗性技术解决联邦学习系统中的域偏移问题。 团队的方法通过为每个源域节点训练一个模型并使用源域梯度的聚合更新目标模型来保护数据隐私,与经典联邦学习不同,FADA 在保证数据分散学习模型的同时实现了减少域偏移。首先,文章从理论角度分析联邦域适应问题并提供泛化界限。 基于理论分析的结果,作者提出了一种有效的基于对抗性自适应和表示分离的自适应算法。此外,作者还设计了一个动态注意力模型来处理联邦学习中不同的收敛速度问题。
FADA 是指:在联邦学习的架构中使用对抗性适应技术,通过在每个源节点上训练一个模型并通过源梯度(source gradients)的聚合来更新目标模型,同时保护数据隐私、减少域迁移。
图 1. (a) 本文针对 UFDA 问题提出了一种方法,令模型在每个源域上分别训练,并利用动态注意力机制聚合其梯度来更新目标模型;(b) FADA 模型学习使用对抗性域对齐(红线)和特征分解器(蓝线)来提取域不变特征。
图 1(b)中提到 FADA 使用对抗域对齐和特征分离器来提取域不变特征。关于提取域不变特征的问题,主要是指深度神经网络能够在多个隐藏因素高度纠缠的情况下提取特征。学习分离表示有助于去除不相关和特定领域的特征,从而只对数据变化的相关因素建模。
联邦域自适应的泛化界:
联邦对抗域适应:
我们提出了动态注意模型来学习权重 α 和联合对抗性对齐,以最小化源域和目标域之间的差异,如图 1 所示。此外,我们利用表示解缠结来提取域不变表示以进一步 加强知识转移。
注意力机制:在联邦域自适应系统中,不同节点上的模型具有不同的收敛速度。另外,源域和目标域之间的域迁移是不同的,导致一些节点对目标域没有贡献甚至是负迁移。为了解决这个问题,作者提出了动态注意力,它是源域梯度上的一个掩模。纳入动态注意力机制的原理是增加那些梯度对目标域有利的节点的权重,而限制那些梯度对目标域不利的节点的权重。具体来说,利用间隙统计(Gap Statistics)来评估无监督聚类算法(K-Means)对目标特征 f^t 的聚类效果。
直观地说,较小的间隙统计值表明特征分布具有较小的类内方差。通过两个连续迭代之间的间隙统计增益来衡量每个源域的贡献,表示在目标模型用第 i 个源模型梯度更新之前和之后
联邦对抗对齐:由于域差异的存在,机器学习模型的性能急剧下降。作者提出了联邦对抗性对齐,将优化分为两个独立的步骤,一个特定领域的局部特征抽取器和一个全局鉴别器。具 体包括:(1)对于每个域,训练一个本地特征提取器,Gi 对应 Di,Gt 对应 Dt,(2)对于每个(Di , Dt) 源域 - 目标域对,训练一个对抗性域标识符 DI,以对抗性的方式对齐分布。
首先,训练 DI 来识别特征来自哪个领域,然后训练生成器(G_i , G_t) 来混淆 DI。值得注意的是,D 只访问 G_i 和 G_t 的输出向量,而不违反 UFDA 的规则。
表征分解:使用对抗性分解来提取域不变特征,将(G_i , G_t) 提取的特征分解为领域不变特征和领域特定特征。如图 1(b)所示,分离器 Di 将提取的特征分为两个分支。首先分别基于 f_di 和 f_ds 特征训练 K 路分类器 Ci 和 K 路类别标识符 CI_i 正确地预测具有交叉熵损失的标签。其中 f_di 和 f_ds 分别表示域不变和域特定特征。
这篇文章代码造假,写的代码根本不是federated learning,更有意思的是,把他文章中提出的所有模块删掉以后,整体会提5个点https://www.zhihu.com/question/348016090/answer/897469095
Federated Adversarial Debiasing
Federated Adversarial Debiasing for Fair and Trasnferable Representations
然对抗性学习通常用于集中式学习以减轻偏见,但当把它扩展到联邦式框架中时,会有很大的障碍。 在这项工作中,我们研究了这些障碍,并通过提出一种新的方法 Federated Adversarial DEbiasing(FADE)来解决它们。FADE不需要用户的敏感群体信息来进行去偏,并且当隐私或计算成本成为一个问题时,用户可以自由地选择退出对抗性部分。
KD3A
Unsupervised Multi-Source Decentralized Domain Adaptation via Knowledge Distillation
一种满足隐私保护要求的去中心化无监督域适应范式
KD3A:基于知识蒸馏的无监督多源分散域适应
|
|
|
|
KD3A/dataset/DomainNet/splits/clipart_test.txt
|
|
|
|
|
|
|
|
|
|
|
|
Digit5是一个数字分类数据集,包括MNIST (mt)、MNISTM(mm)、SVHN (sv)、Synthetic (syn)和USPS (up)
简单总结
如何进行特征对齐–知识投票
源域训练的模型发送给目标域,在目标域上对源域上的知识共识进行投票,得到高质量的域共识,用这个域共识做知识蒸馏的训练,然后用无标签的数据和部分共识训练得到的模型,在目标域上可以起到知识迁移的效果。
训练完之后就根据知识提出了知识共识的度量,度量每个源域的知识共识的多少来进行加权,从而来过滤不好的源域。
BatchNorm MMD:通过模型保留的两种参数来计算不同源域之间的二次mmd距离,减少不同源域的距离损失,分布距离.
四个domain上训练了四个模型,有一个目标域的数据,我们将模型发到目标域,用这四个模型对数据进行预测,然后通过ensemble得到四个模型的共识知识。ensemble包含三步,inference,confident gate筛选比较相信的预测(比较相信的结果是有价值的,模棱两可的没有价值),对剩下的进行投票 同样认为是共识的模型保留下来,平均一下,并记录支持这个共识的domain的数量。以此作为训练的目标,知识蒸馏的目标知识。
构造一个扩展性的source domain,数据是目标域的数据,共识是得到的共识。对这个数据和共识用知识蒸馏损失训练一个新的模型,最终模型是对这k+1个模型进行加权平均。
不考虑目标域源域,把目标域扩展到了同等定位的源域,在这些源域上进行联邦学习,让他们进行知识共享,完成了对于没有标注的目标域的知识迁移。对目标域做task risk的定义,方便进行计算迁移损失bound。
如果一个共识知识被很多的source domain以很高的信度支持,那么认为是一个可靠的知识。将这个知识作为知识蒸馏的目标对目标域进行训练。三步下来未必会得到有效的知识,给他一个比较低的权重0.001。为什么不直接删掉,图像本身是有信息的,揭示了分布的规律,如果删掉目标域的分布对应不上了,出现目标域上的domain-gift,所以保留。损失函数=权重乘知识蒸馏损失。
负迁移:对负迁移的鲁棒–本质上界定每个源域,每个客户端对源域的贡献。
之前的模型采用分布距离进行加权,源域和目标域的分布近就权重大一些。问题,数据保护的条件下没法得到数据本身,源域和目标域很像,但源域的数据是错的,被注入攻击了。
如果有个source domain的知识总是和共识相符合,那么认为这个source domain贡献是多的。
总的Consensus quality: 知识的domain个数乘以最大的信度累加,就是所有的source domain在target domain的共识质量。计算每个domain的共识质量(除去本身之后)。
算法过程:1、本地训练模型。2、本地训练模型通过中央服务器传给目标域,要求目标域用本地训练的模型进行知识蒸馏,在目标域上知识蒸馏出一个扩展的模型。3、整个模型的分发参数。
KD3A的泛化界:bound,目标域的迁移效果要好,首先源域效果要好,源域和目标域的特征距离要接近。好的源域,目标域和源域的分布特征要尽量的接近。
--->目标域的迁移效果要好,首先源域效果要好,源域和目标域的特征距离要接近。(个性化来提升源域的性能—目标域的性能提升)但是个性化一方面就是会损失精度?是否有联邦迁移学习做个性化的?
知识蒸馏:用共识知识扩展源域 ,用数据和共识利用知识蒸馏损失训练一个模型。
本地训练十个epoch通信一次。代码中1次。
最关键的是知识投票
知识蒸馏代码体现在哪里?知识投票得到的域共识,然后用这些域共识进行知识蒸馏损失训练
域间分布距离如何体现?
摘要
传统的无监督多源域适应(Multi-source Unsupervised Domain Adaptation)方法假设所有源域数据都可以直接访问。然而,隐私保护政策要求所有数据和计算都必须在本地进行,这对域适应方法提出了三个挑战:首先,最小化域间距离需获取源域和目标域的数据并进行成对计算,而在隐私保护要求下,源域数据本地存储、不可访问。其次通信成本和隐私安全限制了现有域适应方法的应用。最后,由于无法鉴别源域数据质量,更易出现不相关或恶意的源域,从而导致负迁移。为解决上述问题,我们提出一种满足隐私保护要求的去中心化无监督域适应范式,称为基于知识蒸馏的去中心化域适应(KD3A),通过对来自多个源域的模型进行知识蒸馏来构建可迁移的共识知识。大量实验表明,KD3A显著优于其他域适应方法。此外,与其他去中心化的域适应方法相比,KD3A 对负迁移具有鲁棒性,并可将通信成本降低100倍。
不同数据源域存在域偏移(Domain Shift),简单地混合不同数据源域进行训练往往效果很差。无监督多源域适应(Unsupervised Multi-source Domain Adaptation,UMDA)构建具有迁移能力的特征,能够从多个源域迁移到某个无标注的目标域,从而解决域偏移问题。
现有的无监督多源域适应范式包含两个主要步骤执行知识转移:首先,结合来自源域与目标域的数据,构建源域-目标域数据对。然后,通过最小化域间分布距离(H-散度)在潜变量空间(latent space)中建立可迁移特征。当所有源域数据都可以直接获取时,该域适应范式获得了很大成功。然而,在隐私保护政策下,很多敏感数据,例如来自不同公司的客户信息,或是来自不同医院的患者数据,是不可访问的。这种情况下,源域的所有数据,以及对这些数据进行的计算,都必须保持本地化,而仅有三部分信息是可用的:K个源域上训练数据集的大小 N,在源域上本地训练的K个模型 ℎ ,以及具有 Nt个无标注数据的目标域 DT 。利用联邦学习,一个典型的分布式域适应训练范式如下图所示:首先,在各个源域本地训练模型。然后将模型参数(模型更新)发送到中央服务器,中央服务器采用联邦平均算法汇总本地模型,得到全局模型。最后,将全局模型迁移到目标域上。
现有的域适应算法用于隐私保护的去中心化场景存在三个挑战:首先,最小化域间分布距离(H -散度)需要收集源域和目标域的数据进行成对计算,而源域上的数据不可访问。其次,通信成本与隐私安全也限制了模型的应用。例如,联邦对抗域迁移 (Federated Adversarial Domain Adaptation, Peng et al., 2020) 提出了去中心化的对抗训练方法。然而该方法需要每一个源域在每一个训练Batch后进行模型同步,这带来巨大的通信成本并导致隐私泄露。最后,由于原始数据不可访问,因此可能会存在一些不良域或是恶意域,从而导致负迁移(Negative Transfer)问题。例如,SHOT (Liang et al., 2020) 与Model Adaptation (Li et al., 2020) 提出无源(Source-free)域迁移来解决源域数据不可用问题,但是它们无法识别不良源域,容易受到负迁移的影响。由于难以治理数据质量,可能存在一些与目标域相差甚远的无关源域,甚至存在一些执行投毒攻击的恶意源域。有了这些坏域,就会发生负迁移。
提出了一种基于知识蒸馏的去中心化域适应新范式,缩写为KD3A,即通过对来自不同源域的模型进行知识蒸馏来进行分散域自适应,以解决上文所总结的三个挑战。KD3A由三个串联使用的组件构成:首先是一种名为知识投票(Knowledge Vote)的多源模型知识蒸馏方法,用以获取高质量的域共识知识。然后,定义每一个源域所贡献共识知识的质量,并推导出一种可以识别无关域与恶意域的新指标,一种动态加权策略,名为共识焦点(Consensus Focus),利用共识焦点对各个源域进行动态加权可以防止负迁移。最后,利用深度学习模型的batch norm层中所记录的特征滑动均值与方差,提出BatchNorm MMD 距离,用于对域间距离进行分布式优化MMD分布距离。
相关工作
无监督多源域适应:无监督多源域自适应(UMDA)通过减小源域DS和目标域dt之间的h散度建立可转移特征。提供h散度优化策略的主流范式有两种(特征对齐的主流方案),即最大平均差异(MMD,分布距离,用深度学习把输入映射到特征空间,然后在特征空间上进行计算)和对抗训练(判别器就是来进行分布对齐的)。此外,知识蒸馏也被用于执行模型级的知识转移。
MMD基础方法:(Tzeng et al., 2014)利用kernelκ构建再现核希尔伯特空间(RKHS) Hκ,并通过最小化Hκ上的MMD距离dκMMD(DS, DT)来优化h -散度。最近的研究提出了烟雾弹的变体,例如多核烟雾弹(Long等人,2015)、类加权烟雾弹(Yan等人,2017)和跨域烟雾弹(Peng等人,2019)。然而,所有这些方法都需要对来自源域和目标域的数据进行两两计算,这在去中心化约束下是不允许的。
对抗性训练策略:(Saito et al., 2018;Zhao等人,2018a)在特征空间中应用对抗训练来优化h -散度。事实证明,在对抗性训练策略下,UMDA模型可以在隐私保护策略下工作(Peng et al., 2020)。然而,对抗性训练需要每个源域在每批处理后与目标域交换和更新模型参数,这消耗了大量的通信资源。
领域适应中的知识蒸馏:自监督学习有很多应用(Zhang et al., 2021;Chen et al., 2021)在缺乏标签的场景中有很多应用。知识蒸馏(KD) (Hinton et al., 2015;Chen et al., 2020)是在不同模型之间转移知识的一种有效的自我监督方法。最近的作品(孟等人,2018;Zhou et al., 2020)通过师生培训策略将知识蒸馏扩展到领域适应:在源域上训练多个教师模型,并在目标域上集成它们,以训练一个学生模型。在实践中,该策略优于其他UMDA方法。但是,由于存在不相关和恶意的源域,传统的KD策略可能无法获得适当的知识。
联邦学习:最近的工作(McMahan et al., 2017)发现了模型性能和通信效率之间的权衡,即为了使全局模型获得更好的性能,我们需要进行更多的通信轮,这提高了通信成本。此外,频繁的沟通还会造成隐私泄露(Wang et al., 2019),使得训练过程不安全。
联邦域自适应:FADA (Peng et al., 2020)首先提出了联邦域自适应的概念。它在不访问数据的情况下,应用对抗训练优化H-divergence。但是,FADA消耗了较高的通信成本,容易受到隐私泄露攻击。模型自适应(Li et al., 2020)和SHOT (Liang et al., 2020)提供了无源方法来解决单源分散域自适应。但是,在多源情况下,它们容易受到负迁移的影响。
KD3A
theorem1 目标域上的迁移精度<=源域上的损失加上源域和目标域上的特征距离。
分散场景的问题表述:在去中心化UMDA中,来自K个源域的数据存储在本地,不可用。每个通信轮的可访问信息包括:1、源域上的训练集的大小,以及模型的参数。2、目标域上NT个未标记的数据。
在KD3A中,我们在不访问数据的情况下,应用知识蒸馏来执行领域自适应。
用共识知识扩展源域
知识蒸馏可以通过不同的模型进行知识转移。们用qk S (X)表示每个类的置信度,并用置信度最大的类作为标签。
如图1a:UMDA中的知识蒸馏分为两个步骤:首先,对于每个目标域数据XT i,我们获得源域模型的推断.然后,利用集成方法获得源模型的共识知识.
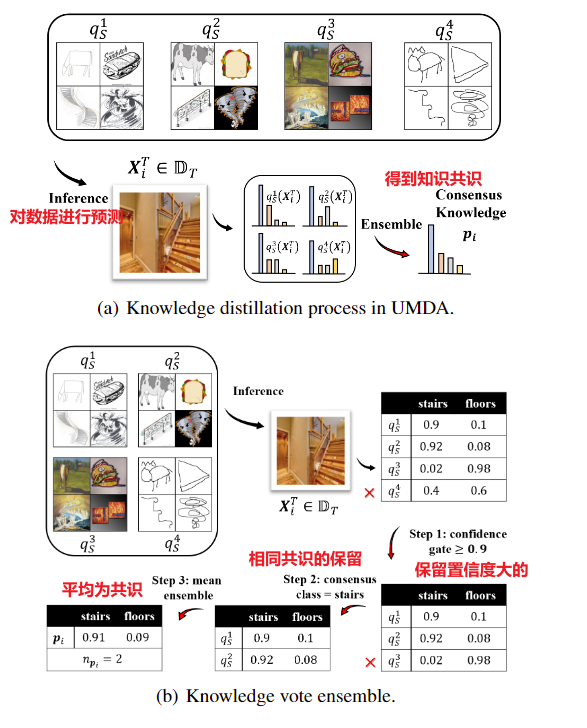
为了利用共识知识进行域适应,我们定义了一个扩展源域DK+1S,每个目标域数据XT i的共识知识pi。利用这个新的源域,我们可以通过知识蒸馏损失来训练源模型hk +1S。
最小化KD损失可以优化新的源域的精度。有了这个认识,我们可以推导出知识蒸馏的泛化界如下。
知识投票:产生良好的共识
当共识知识足够好地代表地真标签时,新的源域DK+1S将改善泛化界。然而,由于源域的不相关和恶意,传统的集成策略(如最大集成和平均集成)可能无法获得适当的共识。因此,我们提出知识投票,以提供高质量的共识。
- 首先使用一个高级置信门对教师模型的预测进行筛选,并剔除不可信模型。
- 对于剩下的模型,将预测结果相加,以找到具有最大值的共识类别。然后我们放弃与共识类不一致的模型。
- 在类投票之后,我们得到了一组都支持共识类的模型。最后,通过对这些支持模型进行均值集合,得到共识知识pi。我们还记录了支持pi的域的数量,用npi表示。对于那些被置信门排除了所有教师模型的XT,我们简单地使用均值集合来得到p,并给它们分配一个相对较低的权重,即np = 0.001。
用npi对知识蒸馏损失进行重新加权,与其他集成策略相比,我们的知识投票使模型学习到高质量的共识知识,因为我们赋予高置信度和多个支持域的项目较高的权重。
共识焦点:反对负转移
域权重α决定了每个源域的贡献。Ben-David et al.(2010)证明了当所有源域都同等重要时,最优α应与数据量成正比。然而,这个条件在KD3A中很难满足,因为一些源域通常与目标域非常不同,甚至带有损坏标签的恶意域。这些坏域导致负迁移。一个常见的解决方案(Zhao et al., 2020)是用h散度作为重估每个源域的权重。
然而,计算h散度需要访问源域数据。此外,H-divergence只度量输入空间上的域相似度,没有利用标签信息,无法识别恶意域。合理地,我们提出共识焦点来识别那些不相关的和恶意的域。正如知识投票中提到的,UMDA的绩效与共识知识的质量有关。有了这个动机,共识焦点的主要思想是给那些提供高质量共识的域分配高权重,而惩罚那些提供糟糕共识的域。为了实现共识焦点,我们首先推导出共识质量的定义,然后计算每个源域对共识质量的贡献。
一般来说,如果一个共识类被更多的源域支持,置信度越高,那么它就越有可能代表真实的标签,这意味着共识的质量越好。
共识焦点(CF)值,以量化每个源域的贡献,描述了单个源域Dk S对所有源域S的共识质量的边际贡献。
在知识投票中引入了一个新的源域DK+1S,所以我们分两步计算域权值。首先,根据数据量,得到DK+1S的αK+1 = NT /(∑K K =1 Nk + NT)。然后,我们使用CF值重新加权每个原始源域。
与(6)中的重加权策略相比,我们的Consensus Focus有两个优势。首先,α cf的计算不需要访问原始数据。其次,通过Consensus Focus获得的α cf基于共识的质量,既利用了数据信息,又利用了标签信息,能够识别恶意域。
KD3A对Clipartand Real等高质量领域提供了更好的共识知识,同时也确定了Quickdraw等不良领域。CMSS 通过使用独立的网络检查每个数据的质量来选择域。与 CMS 相比,KD3A 不会引入额外的模块,并且可以在隐私保护场景中执行源选择。
BatchNorm MMD: H−散度的分散优化策略
为了获得更好的UMDA性能,我们需要最小化源域和目标域之间的h散度,其中基于核的MMD距离被广泛使用。
然而,这些方法并不适用于分散的UMDA,因为源域数据不可用。此外,仅使用fc层的高级特征可能会丢失详细的二维信息。因此,我们提出了BatchNorm MMD,它利用每个BatchNorm层中的均值和方差参数来优化h -发散,而不访问数据。
直接优化损失 (17) 需要遍历所有 Batchnorm 层,这是耗时的。受审稿人建议的启发,我们提出了一种包含两个步骤的计算效率方法。首先,我们直接推导出损失(17)的μ(πT l)的全局最优解,即∀l, 1≤l≤L。
直接将这个解代入hT的每个Batchnorm层,并将其作为全局模型。尽管这种计算效率高的实现可能看起来是启发式的,但我们发现它实际上是可行的,并且可以达到与原始最大化步骤相同的性能。
算法
整个域适应模型的训练过程如下图所示:
- 各源域本地训练模型,并将模型发送到中央服务器。
- 在多个源域模型上进行知识投票,构建一个额外的共识源域,包括共识知识 Pi 以及支持Pi 的源域个数 nPi ,记为D 。知识蒸馏得到新的源域模型。
- 随后通过共识焦点聚合 K+1 个源模型得到目标模型。
- 使用 BatchNorm MMD 来最小化域间分布距离(H -散度),将特征适应于目标域。
泛化误差分析
实验:
在四个基准数据集上进行了实验:(1) Amazon Review (Ben-David et al., 2006),这是一个情感分析数据集,包含四个源域。(2)Digit-5 (Zhao et al., 2020),这是一个数字分类数据集,包括五个源域。 (3) Office-Caltech10 (Gong et al., 2012),包含来自四个源域的十类图像。(4) DomainNet (Peng et al., 2019),这是最近推出的具有 345 个类和 6 个域的大规模多源域适应基准数据集,如下图所示。
resnet101
Model-Contrastive Federated Domain Adaptation
模型对比联邦域自适应
在本文中,我们提出了一种名为 FCDC 的基于模型的方法,旨在解决基于对比学习和视觉transform (ViT) 的联邦域适应。特别是,对比学习可以利用未标记的数据来训练优秀的模型,ViT 架构在提取适应性特征方面比卷积神经网络 (CNN) 表现更好。据我们所知,FDAC 是第一个尝试通过在联邦设置下操纵 ViT 的潜在架构来学习可转移表示的尝试。此外,基于域增强和语义匹配,FDAC 可以通过补偿每个源模型和特征知识不足来增加目标数据的多样性。在几个真实数据集上的大量实验表明,FDAC在大多数情况下优于所有比较方法。此外,FDCA 还可以提高通信效率,这是联邦设置中的另一个关键因素。
一些作品[5],[6],[18]试图在不访问源数据的情况下适应知识,但未能达到高性能。由于本地数据跨源域分布的异构性,如何利用数据隐私源模型和未标记的目标数据成为一个主要挑战。为了在FDA处理这一挑战,至少应该考虑两个问题。首先,如何提取可转移的特征以适应跨异构领域的知识?其次,如何在不访问源模型的本地数据的情况下,通过学习源模型来对齐条件分布?
与传统的深度神经网络 (DNN)(如卷积神经网络 (CNN) [19]-[21])相比,视觉 Transformer (ViT) 可以提取更具适应性和稳健的特征。然而,基于 Vit 的方法面临几个挑战 [22]。例如,它们严重依赖大规模训练数据。因此,由于异构数据的多样性,在联合设置中弥合大型域差距更加困难。为了解决这个问题,需要域增强来考虑域之间的互补性[23]。根据[24],操纵 DNN 的隐藏层可以得到更好的特征表示。因此,利用 vit 的潜在架构可以在域级别增加数据并生成可转移特征以弥合 FDA 中的域差异
对比学习成为一种流行的基于增强数据嵌入的判别方法,并在分类等下游任务中显示出良好的效果[25],[25],[26]。由于一个原型可以代表一组语义相似的样本[27],因此每个源域的原型可以在不访问本地数据的情况下基于源模型生成[18]。然后,基于对比学习,通过匹配源域和目标域的语义信息,对条件分布进行对齐。虽然已经提出了几种方法[26],[28]-[31]来学习基于对比学习或原型的跨域可转移表示,但这些设置相对于ViT和FL下的设置相对简单,因为ViT比cnn更需要数据,并且在联邦设置中应考虑通信效率。
在本文中,我们提出了一种模型感知对比方法(FAC),以解决基于对比学习和视觉 Transformer 的联合域适应。特别是,FDAC 考虑了多源单目标 FDA 设置 [6]、[32],它比单源多目标场景更受欢迎[7]。FDAC 的一般思想如图 1 所示,其中域增强和语义匹配是适应不同模型知识的两个关键组件。
contributions:
我们利用ViT的隐藏架构进一步探索异构域之间的特征可移植性
我们提出了一种新的框架,该框架集成了域增强和语义匹配,以适应来自所有源模型的知识。此外,该框架可以增加数据多样性,跨域对齐类条件分布并避免灾难性遗忘。
挑战:1)在不访问每个源域本地数据的情况下增加目标数据的多样性具有挑战性。2) 由于每个类别信息不能详细描述,因此很难对齐不同领域的条件数据分布。
FDAC 的框架如图 2 所示,旨在将知识从不同的源模型转移到目标模型,同时保证通信效率。FDAC 的实现分别基于域增强和语义匹配,分别对应于域级和类别级对比学习。与传统的可迁移特征学习 [29]、(3) 不同,我们利用 VT 的可配置架构来执行基于域增强的对比学习,因为 DNN 的潜在操作可以改善特征表示 [24]。此外,这种域增强可以通过补充每个源域来增加目标域的数据多样性。另一方面,为了利用类相似性将知识转移从源数据到相似的目标类别,我们基于语义匹配提取域不变特征。由于没有可用的源数据来训练目标模型,我们首先为源域生成原型,然后根据这些原型学习判别信息。因此,当利用知识从不同的来源适应目标域时,这两个组件也能够避免灾难性遗忘。
Author kong
LastMod 2022-11-22