联邦知识蒸馏
Contents

随着深度学习与大数据的进一步发展,效果好的模型往往有着较大的规模和复杂的结构,往往计算效率与资源使用方面开销很大,无法部署到一些边缘设备、移动终端或者嵌入式设备上。因此,如何在保证模型性能的前提下减少模型的参数量以及加快模型前向传播效率,这是一个重要的问题,总的来说不同的模型压缩与加速技术具体可以分为以下四类:
-
参数剪枝与共享(Parameter pruning and sharing):参数剪枝和共享用于降低网络复杂度和解决过拟合问题。网络模型越大,参数也越多,但是可能很大一部分参数是冗余的,所以我们可以将那些对输出结果影响不大的参数减去,这样就可以使得模型运行速度更快、模型文件更小。参数共享可以参考卷积神经网络每个过滤器的权重是固定的,可以看作模板,只关注数据的某一种特性,同时可以减少参数与计算量。
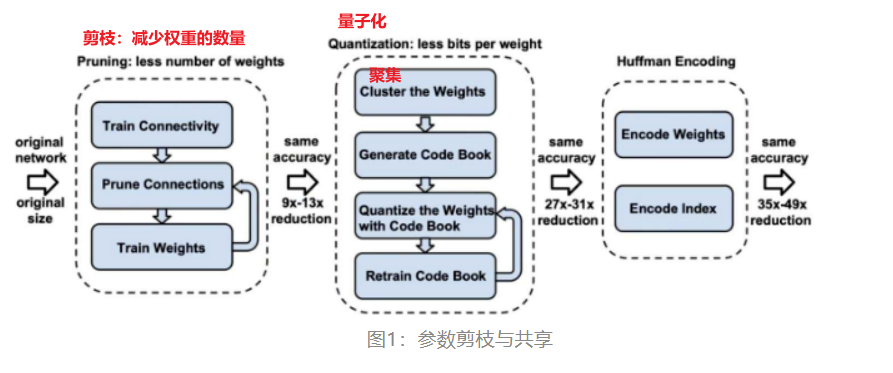
-
低秩分解和稀疏性(Low-rank factorization and sparsity):从线性代数的角度上来说,低秩矩阵每行或每列都可以用其他的行或列线性表出,其包含大量的冗余信息。低秩分解的目的在于去除冗余,并且减少权值参数,进一步来说权重向量往往分布在一些低秩子空间,所以我们可以用少量参数重建权重向量。在机器学习角度可以采用两个 K×1 的卷积核替换掉一个K*K 的卷积核,这将减少大部分参数。
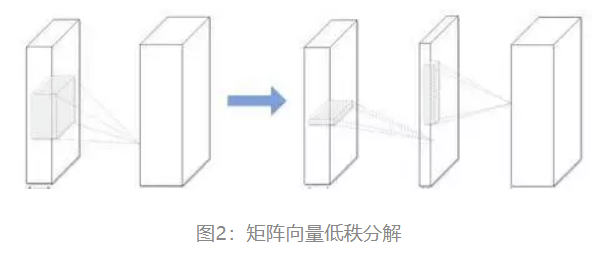
-
传输/紧凑卷积滤波器(Transferred/compact convolutional filters):由于卷积神经网络的滤波器通过一个个卷积核进行特征提取,而较大的卷积核可以通过小型卷积核的拼凑进行替换,即一个5*5的卷积核可以通过两个3×3的卷积核代替进行特征提取。通过增加卷积核之间的约束关系来优化空间和计算,从而实现压缩卷积核、减少计算的目的。
-
知识蒸馏(Knowledge Distillation):知识蒸馏是近年来发展起来的一类模型压缩与加速技术,其主要是利用一个已经训练好的复杂模型(作为教师),将其学习到的决策信息(知识)迁移到另一个轻量级模型(作为学生)中,帮助和指导学生模型的训练。知识蒸馏旨在通过将知识从深度网络转移到小型网络来压缩和改进模型。
联邦学习(FL)是一种机器学习设定,其中许多客户端(例如,移动设备或整个组织)在中央服务器(例如,服务提供商)的协调下共同训练模型,同时保持训练数据的去中心化及分散性。其核心目标是为了在不暴露数据的情况下分析和学习多个数据拥有者的数据。
联邦学习主要面临四大挑战:通信效率(communication efficiency)、系统异构性(system heterogeneity)、统计异构性(statistical heterogeneity)与隐私安全(privacy security)。同时由于联邦学习特有的客户端-服务器的系统架构,导致模型往往需要尽可能的便捷,同时需要保证传输模型时的实时性(面向多数设备)与快速性(传输效率高)。
自然而然的,人们就将联邦学习与模型压缩加速技术进行结合。通过模型压缩加速技术在联邦学习的训练过程、传输过程或推理过程进行优化,从而尽可能保障模型的传输高效率和实时性。而近期知识蒸馏的技术发展最为迅速,因此涌现出来不少的联邦知识蒸馏相关的论文与想法。
知识蒸馏概述
知识蒸馏将复杂且大的模型作为 Teacher模型,将模型结构较为简单需要优化的模型作为 Student模型,然后用Teacher来辅助Student模型的训练。知识蒸馏希望学生网络在模拟老师的输出的时候尽可能学到类与类之间的相似性和差异,从而增强学生模型的泛化能力。
知识蒸馏的主要关键点在于:知识的类型、蒸馏方法和教师-学生网络的结构。由于蒸馏方法往往大同小异,主要在于怎么设计Loss(但大部分也是从欧式距离、余弦距离、相似性等角度来设计损失),同时教师-学生网络的结构设计涉及到模型架构方面也较复杂,所以从知识类别角度来对知识蒸馏进行概述(个人感觉如何定义一个新的蒸馏的知识是创新最大的地方)。
Logits KD:知识蒸馏的开山之作,Hinton在2014年提出基于logits的知识蒸馏方法,主要思想在于用学生网络的预测logits去学习教师网络的输出logits,从而引导学生网络训练,可以学习到自身预测不出来的类之间的相似性知识。主要方法是通过基于温度参数的softmax函数,对输出logits进行软化,将其看作一种知识从教师端转移到学生端。
Hints KD:该论文是第一个考虑到模型中间隐藏层的知识蒸馏方法,其主要是将模型隐藏层的特征看作是一种知识,然后学生网络通过学习教师网络的隐藏层特征知识,可以提升学生模型自己的性能,同时可以和logits KD方法在一起结合使用。
损失函数主要使用了MSE Loss,如果教师网络和学生网络的隐藏层输出特征不同大小,那么将其变换成相同大小再进行损失计算。
Attention KD:该论文将神经网络的注意力作为知识进行蒸馏,并定义了基于激活图与基于梯度的注意力分布图,设计了注意力蒸馏的方法。大量实验结果表明AT具有不错的效果。
论文将注意力也视为一种可以在教师与学生模型之间传递的知识,然后通过设计损失函数完成注意力传递,本质上来说学生模型学习到了教师模型针对输入数据权重更高的地方,即输入数据对模型的影响程度。
Cooperative KD:通常来说,大小模型的效果对比十分显著,意味着logits的差别是很大的,因而使小模型去逼近大模型的logits无疑是比较难的任务。该论文通过结合课程学习思想,思考模型从易到难训练可能会有更好的效果,而从易到难的方法简单来说就是大小模型同时在下游任务进行微调,并在每个周期epoch中让大模型引导小模型进行学习。
关键之处在于:teacher模型和student模型共同训练、teacher和student模型loss损失的计算。同时教师模型不再固定参数,而是随着学生模型反馈而进行轻微改动。
Similarity KD:提出了一种新的知识蒸馏损失形式,称为相似性知识,灵感来自于相似的输入会倾向于在训练的网络中引起相似的激活模式,与以前的蒸馏方法相比,学生不需要模仿教师的表示空间,而是需要在其自己的表示空间中保持与教师网络成对的相似性。
保持相似性的知识蒸馏指导学生网络的训练,使在训练的教师网络中产生相似激活的输入也在学生网络中产生相似激活。当输入相同的数据时,学生网络学习教师网络的神经元激活。
更进一步来说,如果两个输入在教师网络中产生高度相似的激活,那么引导学生网络,这也会导致两个输入在学生中产生高度相似的激活;相反地,如果两个输入在教师中产生不同的激活,我们就希望这些输入在学生中也产生不同的激活。
Relation KD:作者引入了一种新的方法,称为关系知识蒸馏(RKD),它可以转移数据示例的相互关系,对于RKD的具体实现,作者提出了距离和角度的蒸馏损失来惩罚关系中的结构差异。
作者主要将关系结构看作是一种知识,然后又通过欧式距离与余弦距离作为损失函数来传递知识,从而使得RKD训练学生模型形成与教师相同的关系结构。
总结
通过若干知识蒸馏论文的解读我们可以发现,相比较而言,蒸馏知识的创新比较重要,一种知识的定义主要在于两方面:
1)在模型学习训练过程中,什么构成了知识;
2)如何将知识从教师网络转移到另一个学生模型中。
进一步而言,我们可以考虑从哪方面定义知识,例如模型的预测标签、模型网络的中间层、模型权重等等方面,或者综合多个角度进行结合,也可以考虑基于任务的知识蒸馏(例如目标检测、语义分割等任务),从而设计出基于任务的知识/蒸馏算法或者师生模型架构。
在传统联邦学习,传输的数据量和模型比例正相关,而且会随数据的Non-IID分布影响并减少准确度,所以有一些文章思考如何结合知识蒸馏与联邦学习从而带来效率与性能方面的提升。接下来,我们将结合一些文章解析基于联邦学习的知识蒸馏算法与思想。
知识蒸馏是一种模型压缩方法,通过利用复杂模型(Teacher Model)强大的表征学习能力帮助简单模型(Student Model)进行训练,主要分为两个步骤:
1)提取复杂模型的知识,在这里知识的定义有很多种,可以是预测的logits、模型中间层的输出feature map、也可以是模型中间层的attention map,主要就是反映了教师模型的学习能力,是一种表征的体现;
2)将知识迁移/蒸馏到学生模型中去,迁移的方式也有很多种,主要是各种loss function的实现,有L1 loss、L2 loss以及KL loss等手段。
知识蒸馏可以在保证模型的性能前提下,大幅度的降低模型训练过程中的通信开销和参数数量,知识蒸馏的目的是通过将知识从深度网络转移到一个小网络来压缩和改进模型。
这很适用于联邦学习,因为联邦学习是基于服务器-客户端的架构,需要确保及时性和低通信,因此最近也提出很多联邦知识蒸馏的相关论文与算法的研究,接下来我们基于算法解析联邦蒸馏学习。
FL-FD 数据增强的联邦蒸馏算法
在联邦学习(Federated Learning: FL)中,在每个设备端执行训练过程需要与模型大小成比例的通信开销,从而禁止使用大型模型,因此,作者寻求在非IID私有数据下可以实现通信高效的设备上ML方法。
作者提出联邦蒸馏(FD)算法,这是一种分布式在线知识蒸馏方法,其通信有效成本的大小不取决于模型大小,而取决于输出尺寸。在进行联邦蒸馏之前,我们通过**联邦增强(FAug)**来纠正非IID训练数据集。
这是一种使用生成对抗网络(GAN)进行的数据增强方案,该数据增强方案在隐私泄露和通信开销之间可以进行权衡取舍。经过训练的GAN可以使每个设备在本地生成所有设备的数据样本,从而使训练数据集成为IID分布。
联邦蒸馏(FD):在FD中,每台设备都将自己视为学生,并将其他所有设备的平均模型输出视为其老师的输出。每个模型输出是一组通过softmax函数归一化后的logit值,此后称为logit向量,其大小由标签数给出。
使用交叉熵来周期性地测量师生的输出差异,交叉熵成为学生的损失调整器,称为蒸馏调整器,从而在培训过程中获得其他设备的知识,具体损失是:KDLoss(Local_Logit,Global_Logit)+CELoss(Local_Logit,Local_Lable)。FD中的每个设备都存储着本地每个标签的平均logit向量,并定期将这些本地平均logit向量上载到服务器。
服务器将从所有设备上传的本地平均Logit向量平均化,从而得出每个标签的全局平均Logit向量。所有标签的全局平均logit向量被下载到每个设备。然后,当每台设备进行蒸馏的时候,其教师的输出为与当前训练样本的标签具有相同标签的全局平均logit向量。
联邦增强(FAvg):因为蒸馏最好在具有相同数据集的效果下进行,由于不同设备之间具有异质性所以在蒸馏前进行数据增强可以提升蒸馏效果。FAug中每个设备都可以识别数据样本中缺少的标签,称为目标标签,并通过无线链路将这些目标标签的少量种子数据样本上载到服务器。
服务器则会通过例如Google视觉数据图像搜索等方法对上传的种子数据样本进行超采样,并使用这些数据来训练一个GAN。
最后,下载经过训练的GAN生成器使每个设备补充目标标签,直到达到IID训练数据集为止。FAug的操作需要确保用户生成的数据的私密性。
实际上,每台设备的数据生成偏差(即目标标签)都可以轻松地显示其隐私敏感信息,为了使这些目标标签对服务器不公开,每个设备还将从目标标签以外的其他标签进行上载(冗余数据样本),由此减少了从每个设备到服务器的隐私泄漏。
事实上,模型的输出精度会随着训练的进行而增加,因此,在局部logit平均过程中,最好采用加权平均值随着局部计算时间的增加而增加,即当模型采用整体损失函数:a * KDLoss(Local_Logit,Global_Logit)+CELoss(Local_Logit,Local_Lable) * (1-a),随着迭代次数的增加,a应该逐渐减小(模型的输出精度会随着训练的进行而增加,所以本地模型比重应该增大)。
Author kong
LastMod 2022-03-21