联邦半监督学习
Contents
国自然
现实场景中,如医疗、金融、法律等领 域没有大量的有标签数据,而对数据进行标注需要大量的人力和时间,特别是在些领域只有专家才能对样本进行有效标注。因此,基于监督假设下的联邦学习不具有很好的现实意义。
相对于全监督学习,同时利用少量有标签数据和大量无标签数据的半监督学 习可以克服有标签数据不足的问题。因此,将半监督学习与联邦学习相结合,应 该能够克服现有监督模式下联邦学习所面临的有标签数据不足的问题,满足实际 应用场景的需求。
–》联邦半监督学习
1)隐私安全,在半监督学习过程 中,采用标签“传播”对未标记样本进行标注,如何保证数据隐私安全;2)领域 差异,当有标签数据和无标签数据属于不同域时,如何有效解决数据的非独立同 分布(Non-IID)问题;3)鲁棒性和安全性,面对扰动、异常值、对抗性攻击等, 如何保证模型的鲁棒性和安全性。
本项目拟重点聚焦联邦半监督学习面临 的数据孤岛、数据隐私、领域差异和有标签数据不足等问题,深入挖掘联邦学习 和半监督学习之间关联和协作机制,
设计有效的水平联邦半监督学习和垂直联邦 半监督学习的表示和建模方法
水平联邦半监督学习是指具有不同的样本空间和相同的特征空间。当服务器端仅有有标签据,客户端仅有无标签数据,或者服务器端没有数据,客户端同时具有少量有标签数据和大量无标签数据,同时需要解决数据孤立、数据隐私、领域差异等问题,进而提升联邦半监督学习的性能,提升通信效率等。
本项目拟围绕上述三个关键问题,构建自训练和自适应水平联邦半监督学习的表示和模型,构建多视图垂直联邦半监督学习的表示和模型,设计客户端重要性判定和自适应选择方法,并将上述设计应用到显著性目标检测任务。本研究立足于在学术上创新、在技术上服务于智慧医疗、智慧城市等,因此,本项目的研究具有重要的理 论研究价值和广泛的应用前景。
文献[25]提出了一种基于图的联邦学习方法 GraphFL,采用自训练学习来标记客户端无标签数据,扩充有标签数据。该方法还可以解决图数据中的非独立同分布问题和带有新标签域的任务。文献[26]提出了一种自训练方法使用客户端的少量有标签数据在每个客户端中训练一个本地模型,然后利用本地模型为每个客户端中无标签样本预测伪标签,并选择一组具有最可靠预测的无标签样本连同其伪标签添加到客户端的训练集中,实现数据增强,使得每个客户端具有大量有标签(真的标签+伪标签)样本。文献[28, 29] 采用伪标记技术对无标签数据生成伪标记,实现数据增强,完成水平联邦半监督学习。FedSem[28]基于训练 好的 FedAvg[10]模型,采用伪标记技术对无标签数据生成伪标记,然后利用伪标 记数据对 FedAvg 进行再训练,得到最终的全局模型。文献[29]提出了一种鲁棒的 高效传输的联邦半监督学习系统,使用伪标签方法为客户端的无标签数据设置伪 标签,并使用数据扩充方法增加客户端数据的多样性。文献[30, 31]采用一致性正则化损失的方法实现水平联邦半监督学习。文献[30]提出的 FedMatch 引入了客户端间一致性丢失和参数分解方法,但这种方法仅适用于图像数据。文献[31]提出了一个通用自适应联合半监督学习框架 FedSemi,基于一致性的半监督学习方法,采用一致性损失和分类损失,利用师生网络处理客户端的无标签数据。文献[32, 33] 采用了知识蒸馏的方法对无标签数据进行标注,而文献[34]采用域自适应的方法进行水平联邦半监督学习。上述方法针对服务器端没有数据,客户端包括少量有标签数据和大量无标签数据的情形,或者是服务器端有少量有标签数据,客户端仅有大量无标签数据的情形,采用半监督学习中的伪标签标注、一致性正则化等方法,分别从数据增强、模型正则化等角度实现水平联邦半监督学习。但是,现有方法对于水平联邦学习与半监督学习之间的合作协议的挖掘和建立还有待提升, 构建有效、规范、泛化的水平联邦半监督学习模型。另外,现有方法在客户端聚合、通信效率、模型鲁棒性等方面还有待进一步提升。因此,本项目拟深入挖掘水平联邦学习和半监督学习之间的协作机制,构建水平联邦半监督学习的有效表示和模型,提升水平联邦半监督学习性能。
半监督学习
生成模型方法,数据增强方法,模型正则化方法,多视图训练与集成方法,基于图的半监督学习方法
半监督学习中采用生成模型从概率的角度对数据进行重构,如采用混合模型 进行估计。
平滑假设在半监督学习中被广泛应用,根据这个假设,可以对真实数据进行 调整来增强数据集。近年,平滑假设得到了显著扩展,从而出现了更为复杂的增 强技术,如剪裁、缩放、旋转等,以保持语义的紧密性。
围绕自训练和自适应水平联邦半监督学习方法,多视图垂直平联邦半监督学习方法,客户端重要性判定及自适应选取方法, 以及基于联邦半监督学习的显著性目标检测系统构建四项主要研究内容和三个关 键问题展开深入的探索和研究
本项目拟对水平联邦学习、基于数据增强和一致性正则化的半监督学习进行深入学习,探索有效合作机制,拟提出两种水平联邦半监督学习方法,即自训练水平联邦半监督学习方法和自适应水平联邦半监督学习方法,同时考虑数据的非独立同分布问题,以及通信效率等问题。
自训练:服务器端具有少量的有标签数据,而客户端则具有大量的无标签数据。一个是客户端和服务器端的训练过程,一个是服务器端有效聚合自有有标签数据的训练模型以及客户端多个训练模型。
采用自训练学习方法对无标签数据进行伪标注,增强有标签数据,从而在保证数据隐私安全的情况实现水平联邦半监督学习。
https://baijiahao.baidu.com/s?id=1677412653408516835&wfr=spider&for=pc
自适应:服务器端没有数据,客户端具有少量有标签数据和大量无标签数据。在服务器端,全局参数将通过自适应分配权重对本地参数进行更新,并进一步分布到每个客户端。在客户端,采用最小化分类损失和一致性损失对局部模型进行训练。计算师生网络的层级散度,在向服务器端上传客户端参数时,采用自适应措施删除学生网络的某些层。一方面提升了水平联邦半监督学习的性能,同时提升了通信效率。
多视图垂直联邦半监督学习
多视图标签集中式垂直联邦半监督学习
多视图标签分散式垂直联邦半监督学习
客户端重要性判定及自适应选取方法研究
本项目拟提出面向水平联邦半监督学习的基于自步学习的自适应客户端选择聚合方法
首先,进行初始化,采用自步学习使服务器选取一定数量的 客户进行联邦半监督学习,服务器根据自有的有标签数据训练初始模型,并将初 始模型传播给选定的客户;其次,客户端训练,客户端根据服务器端的初始模型,采用数据扩充的方法对自有无标签数据进行伪标注,得到伪标签,客户端进行训 练,将更新后的模型上传到服务器端;最后,服务器端聚合,使用几何中值聚合 算法聚合客户端上载的模型更新。本方法中拟采用几何中值聚合对自步学习自适应选取的客户端进行有效聚合。
半监督学习
https://mp.weixin.qq.com/s/OAN9QYKc3zYuiQ7hVcDFXg
半监督式学习(SSL),正如其名称所示,介于两个极端之间(监督式是指整个数据集被标记,而非监督式是指没有标记)。半监督学习任务具有一个标记和一个未标记的数据集。它使用未标记的数据来获得对数据结构的更多理解。通常,SSL使用小的带标签数据集和较大的未带标签数据集来进行学习。目标是学习一个预测器来预测未来的测试数据,这个预测器比单独从有标记的训练数据中学习的预测器更好。
典型的监督学习算法在标记数据集较小的情况下,容易出现过拟合问题。SSL通过在训练过程中依借未标记数据的结构来缓解这个问题。此外,这种学习技术减轻了构建大量标记数据集来学习任务的负担。SSL方法更接近我们人类的学习方式。
SSL的流行方法是在训练期间往典型的监督学习中添加一个新的损失项。通常使用三个概念来实现半监督学习,即一致性正则化、熵最小化和伪标签。在进一步讨论之前,让我们先理解这些概念。
一致性正则化:强制数据点的实际扰动不应显著改变预测器的输出。简单地说,模型应该为输入及其实际扰动变量给出一致的输出。我们人类对于小的干扰是相当鲁棒的。例如,给图像添加小的噪声(例如改变一些像素值)对我们来说是察觉不到的。机器学习模型也应该对这种扰动具有鲁棒性。这通常通过最小化对原始输入的预测与对该输入的扰动版本的预测之间的差异来实现。一致性正则化是利用未标记数据找到数据集所在的平滑流形的一种方法。
熵最小化 鼓励对未标记数据进行更有信心的预测,即预测应该具有低熵,而与ground truth无关(因为ground truth对于未标记数据是未知的)。理想情况下,熵的最小化将阻止决策边界通过附近的数据点,否则它将被迫产生一个低可信的预测。
伪标签 是实现半监督学习最简单的方法。一个模型一开始在有标记的数据集上进行训练,然后用来对没有标记的数据进行预测。它从未标记的数据集中选择那些具有高置信度(高于预定义的阈值)的样本,并将其预测视为伪标签。然后将这个伪标签数据集添加到标记数据集,然后在扩展的标记数据集上再次训练模型。这些步骤可以执行多次。这和自训练很相关。
标签锐化(Sharpen Label):标签锐化也是在半监督学习方面常用的一个技巧,模型预测某个样本得出结果logit,这是一个矩阵,矩阵的每一列代表该数据样本所对应类别的概率。为了防止噪音等因素干扰,使用标签锐化操作,其实就是一个基于softmax函数的放大最高概率的方法,特别地,当锐化因子T→0的时候,趋于one-hot。
视觉上的扰动:翻转,旋转,裁剪,镜像等是图像常用的扰动。

语言上:反向翻译是语言中最常见的扰动方式。在这里,输入被翻译成不同的语言,然后再翻译成相同的语言。这样就获得了具有相同语义属性的新输入。
半监督学习方法:
- π model:
目标是一致性正则化。π模型鼓励模型对两个相同的输入(即同一个输入的两个扰动变量)输出之间的一致性。π模型有几个缺点,首先,训练计算量大,因为每个epoch中单个输入需要送到网络中两次。第二,训练目标zĩ是有噪声的。
- Temporal Ensembling
这个方法的目标也是一致性正则化。众所周知,与单一模型相比,模型集成通常能提供更好的预测。通过在训练期间使用单个模型在不同训练时期的输出来形成集成预测,这一思想得到了扩展。简单来说,不是比较模型的相同输入的两个扰动的预测(如π模型),模型的预测与之前的epoch中模型对该输入的预测的加权平均进行比较。这种方法克服了π模型的两个缺点。它在每个epoch中,单个输入只进入一次,而且训练目标zĩ 的噪声更小,因为会进行滑动平均。这种方法的缺点是需要存储数据集中所有的zĩ 。
这在现实世界中是很常见的。由于标注是很昂贵的,特别是大规模数据集,特别是企业用途的,可能只有几个标签。例如,考虑确定用户活动是否具有欺诈性。在100万用户中,该公司知道有1万用户是这样的,但其他9万用户可能是恶意的,也可能是良性的。半监督学习允许我们操作这些类型的数据集,而不必在选择监督学习或非监督学习时做出权衡。
联邦半监督
减少被损坏的风险!!!
一种鲁棒的半监督联邦学习系统
- [1]王树芬,张哲,马士尧,陈俞强,伍一.一种鲁棒的半监督联邦学习系统[J].计算机工程,2022,48(06):107-114+123.DOI:10.19678/j.issn.1000-3428.0061911.
利用 FedMix 方法分析全局模型迭代之间的隐式关系,将在标签数据和无标签数据上学习到的监督模型和无监督模型 进行分离学习。采用 FedLoss 聚合方法缓解客户端之间数据的非独立同分布(non-IID)对全局模型收敛速度和稳定性的影响,根据客户端模型损失函数值动态调整局部模型在全局模型中所占的权重。CIFAR-10 数据集Fashion-MNIST
目前,伪标签和一致正则化方法已广泛应用于半监督领域,但是伪标签主要利用预测值高于置信度阈 值的伪标签来实现高精度模型,一致正则化技术通 过在同一个无标签数据中分别注入两种不同噪声应 保持相同模型输出来训练模型
第一个是传统 SSFL 方法[7,12-13] 直 接将半监督技术(例如一致性损失和伪标签)引入 FL 系统,之后使用联邦学习算法来聚合客户端的模 型参数。这样将导致模型在利用大量无标签的数据 学习后会遗忘从少量标签数据中学习到的知识。文 献[10]分解了标签数据和无标签数据的模型参数用 于进行分离学习,却忽略了全局模型迭代更新之间 的隐式贡献。因此,全局模型将偏向于标签数据(监 督模型)或无标签数据(无监督模型)。
在异构数据的训练过程中,客户 端局部最优模型与全局最优模型会出现很大的差 异。这将导致标准的联邦学习方法在 non-IID 设置 下全局模型性能出现显著下降和收敛速度慢的问 题。例如文献[14]利用局 部批处理归一化来减轻平均聚合模型和局部模型之 前的特征偏移。然而,此类方法给服务器或客户端 增加了额外的计算和通信开销。
本文针对上述第一个问题,提出 FedMix 方法, 分析全局模型迭代之间的隐式效果,采用对监督模型和无监督模型进行分离学习的模型参数分解策略。针对上述第二个问题,为了缓解客户端之间的 non-IID 数据分布对全局模型收敛速度和稳定性的 影响,提出 FedLoss 聚合方法,通过记录客户端的模型损失来动态调整相应局部模型的权重。此外,在 实验中引入 Dirchlet 分布函数来模拟客户端数据的 non-IID 设置。
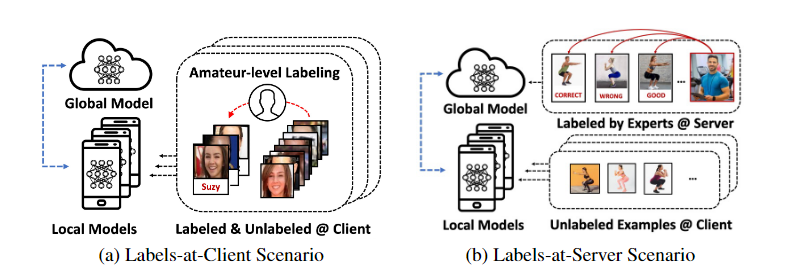
半监督联邦学习试图利用无标签数据进一步提 高联邦学习中全局模型的性能[9] 。根据标签数据所 在的位置,半监督联邦学习分为标签在客户端和标 签在服务器两种场景[10]。
本文研究了标签数据在服务器上 这 一 场 景 ,同 时 也 解 决 了 联 邦 学 习 中 non-IID 的 问题。
由于每个客户端本地数据集的分布与全局分布相差较大,导致客户端的目标损失函数局部最优与 全局最优不一致[19-21],特别是当本地客户端模型参数更新很大时,这种差异会更加明显,因此 non-IID 的数据分布对 FedAvg[1] 算法的准确性影响很大。一些研究人员试图设计一种鲁棒的联邦学习算法去解决联邦学习中的 non-IID 问题。,FedProx[22]通过限制本地模型更新的大小,在局部目标函数中引入一个额外的 L2 正则化项来限制局部模型和全局 模型之间的距离。然而,不足之处是每个客户端需 要单独调整本地的正则化项,以实现良好的模型性 能。FedNova[23]在聚合阶段改进了 FedAvg,根据客户端本地的训练批次对模型更新进行规范化处理。
聚合。服务器收集客户端上传的模型 并使用聚合方法(例如 FedAvg)聚合生成一个新的全局模型,即 ωt+1 = ωt +∑Dk/D ωkt。之后服务器将更 新后的全局模型ωt+1 发送给下一轮被选择参与训练的客户端。
半监督学习中的一个基本假设和两种常用的半监督学习方法
半监督学习其实就是利用大量的无标签数据来弥补少量标签数据指导模型训练所容易造成的过拟合现象(提高泛化能力)。
一致性:如果两个无标签样本 u1、u2的特征相似,那么 相应模型的预测结果 y1、y2也应该相似[14],即 f (u1 ) = f (u2 )
一致性正则化:主要思想是对于无标签的训练样本,无论是否加入噪声,模型预测结果都应该是相同的。通常使用数据增强(如图像翻 转和移位)的方式来给无标签样本添加噪声以增加 数据集的多样性。假定一个无标签数据集 u ={ui } m i = 1 中的无标签样本 ui ,其扰动形式为 u ⌢ i ,则目标是最小 化 未 标 记 数 据 与其扰动输出两者之间的距离。
伪标签:一 般 使 用Sharpening[15]和 argmax[15]方法来设置伪标签,其中 前者使模型输出的分布极端化,后者会将模型输出 转变为 one-hot。伪标签方法也称为自训练方法。
在 SSFL 系统中,根据标签数据所在的位 置,可以分为两种场景:第一种场景是客户端同时具 有标签数据和无标签数据的常规情况,即标签在客 户端场景;第二种场景是标签数据仅可用在服务器 上,即标签在服务器场景。本文针对标签在服务器 场景,给出问题定义:当标签数据只在服务器端,客 户端仅有无标签数据时,在 SSFL 中假设有 1 个服务 器 S 和 K 个客户端。
fedmix:在服务器端训练,本地训练利用服务器模型得到伪标签,聚合客户端上传的无监督模型。
fedloss:根据客户端模型训练的损失值调整相应局部模型的权重,用于提高聚合的全局模型的性能。原因是有些客户端模型在本地训练后性 能较好,那么这些客户端就应该对全局模型做出更多 的贡献。本文的目标是增大客户端性能好的本地模型 对全局模型的影响,以提高模型的性能。
在训练过程中,本文 方 法 和 基 线 方 法 均 使 用 随 机 梯 度 下 降(Stochastic Gradient Descent,SGD)来优化初始学习率为 η=1e3 的 ResNet-9 神经网络。
基于自编码神经网络的半监督联邦学习模型
提出了 一种基于自编码神经网络的半监督联邦学习模型 ANN⁃SSFL,该模型允许无标记的客户端参与联邦学习。 无标 记数据利用自编码神经网络学习得到可被分类的潜在特征,从而在联邦学习中提供无标记数据的特征信息来作 出自身贡献。 在 MNIST 数据集上进行实验。
有标记数据集的客户端利用监 督学习训练模型,获得一个性能好的分类预测器;无标签数据 的客户端利用自编码器进行特征提取,通过联邦学习过程进行 交互,使得该潜在特征可被分类器判别,学习到用于优化分类 的潜在特征。 无标签数据的客户端在训练中不仅自身贡献,也 从其他参与联邦学习训练的客户端获益。 最终获得一个共享 的联邦学习模型。 ANN⁃SSFL 模型是对传统联邦学习的扩展, 将使得联邦学习不再受限于监督学习,具有更好的兼容性和适 应性。
现阶段,联邦学习的研究主要集中在隐 私安全、通信代价和 Non⁃IID 数据性能等方面。
FedProx,即通过改进文献[1]的 FedAvg 算法来解决联邦网络异构问题.
将传统半监督技术直接引入联邦学习中效 果并不理想。 文献[17]探索了半监督学习与联邦学习可能的 结合方向;文献[18]提出半监督联邦学习(SSFL)概念,并提出 FedMatch 算法来提升联邦学习与半监督算法简单结合的效 果,该算法引入客户端之间的一致性损失函数,将模型分解成 可相加的两部分,稠密的参数模型由监督训练得来,稀疏的参 数模型由无监督训练得来;文献[19] 提出 FedMix 算法,一种 分离策略,对在标签数据和无标签数据上学习到的模型进行分 离学习;文献[20]提出 FedSiam 方法,利用孪生网络并且动量 更新的方式来完成半监督联邦学习;文献[21]假设所有客户 端的数据均为无标签数据,服务器存储有标签数据,利用伪标 签方式为客户端数据标注实现半监督学习,并针对客户端发起 投毒攻击情况,提出 RC⁃SSFL 方法,采用基于极大极小优化的 客户选择策略,选择持有高质量更新的客户进行模型聚合,通 过新型对称量化方法提升通信效率;文献[22]提出的 FedSem 同样利用伪标签技术,利用监督训练的 FedAvg 模型对无标签 数据进行标注,生成新的有标签数据集再对 FedAvg 重新训练 得到更新的全局模型;文献[23]提出 SemiFL,通过交替监督训 练服务器与无监督训练客户端来提高伪标签质量;文献[24] 利用蒸馏的方式获得公开数据集的标注信息,重新训练客户端 实现模型更新。 半监督联邦学习在许多领域已展开应用,如行 为识别[25] 、智慧城市[22] 、智慧医疗等[26] 。
利用伪标签技术的半监督联邦学习,容易对低精度的 伪标记数据产生过拟合,从而影响最终模型精度。 多数研究致 力于提高伪标签的可靠性,如文献[21 ~ 23]等。 同时,一些工 作需要辅助数据集,要求服务器端存储有标签数据,如文献 [19,21,23]。 联邦学习的初衷是解决隐私问题,从而不中心 化存储数据。 本文考虑现实中,一个用户只有无标签数据参加 联邦学习的场景,研究结构简单、通用的半监督联邦学习方法。
模型结构:主要包括自编码网 络和分类器两部分。 自编码神经网络是一种试图接近恒等函 数的无监督学习算法,其目的是使其输出尽可能接近输入。 换 句话说,自编码主要目的是从原始输入数据中学习潜在表示 (latent representation)来重建输入数据。 编码器包含学习潜在 表示的编码器(潜在表示也称为代码)和重建输入数据的解码 器。 从编码器中学习的潜在表示是由 softmax 分类器预测的特 征,同时该预测器能够很好地发挥作用。
自编码强制编码器 e(·)学习隐式表示( hidden represent⁃ ation)和解码器 d(·)重建原始输入。 通过最小化重建损失, 使得重建输入 x^ 接近原始输入 x,并利用均方差项计算重建 误差。进一步,e(·)可以看成是一个特征提取器,该特征提取 器将分类损失 LCE 和重建损失 LMSE 联合进行优化。 同时, d(·)是通过优化重建损失 LMSE学习的解码器。
与传统的半监督联邦学习模 型(SSFL) [17 ~ 24]相比,本文并没有将半监督学习的技术(如伪 标签和一致性损失)直接移植于联邦学习系统的构建中,而是 从自编码网络和分类器的构造出发,提出一种更为通用的 SS⁃ FL 模型架构。 这种思想考虑了全局数据(标签数据和无标签 数据)模型,具有更好的理论意义
自编码器,1,2,3:通常包括一个编码器一个解码器,编码器的主要特点就是吸收输入数据的“特点”,然后再释放出来,也讲自编码器理解为降维的过程。自编码器属于无监督学习,不同于神经网络,自编码器不需要任何其他的数据,只需要对输入的特征进行提取就行,当然要添加一些二外的限制条件来“强迫”自编码器提取我们想要的东西。
自编码器我们想要它能够对输入的数据进行分析获取一些特性,而不是简单的输入输出,所以我们通过限制的维度来实现,强迫自编码器去寻找训练数据中最显著的特征。编码器和PCA(PCA是一个简单的机器学习算法,通过寻找矩阵中最大的特征向量来寻找输入数据的"特点”)很像。都是通过编码和解码来得到训练数据的隐含信息,但是如果这个隐含层是线性层(上图提到的)或者隐含层的容量很大,那么自编码器就无法学习到我们输入数据的有用信息。仅仅起一个复制的作用。
※FedMatch
Federated Semi-Supervised Learning with Inter-Client Consistency & Disjoint Learning- Jeong W, Yoon J, Yang E, et al. Federated Semi-supervised Learning with Inter-client Consistency & Disjoint Learning[C]//9th International Conference on Learning Representations,
ICLR 2021. International Conference on Learning Representations, ICLR, 2021 - code,blog,2
标签在客户端场景:有标签和无标签的数据都可以在本地客户端上使用。(本地即包括有标签数据也包括无标签的数据)(b)服务器上的标签场景:有标签的实例只在服务器上可用,而没有标签的数据在本地客户端可用。
本地训练模型后,根据模型相似性创建k维二叉树,进而选择helper client 进行客户端一致性训练。
FedMatch 改进了联邦学习和半监督学习方法的简单组合,增加了新的客户端间一致性损失和参数分解,用于标记和未标记数据的不相交学习。
它强制跨多个模型做出的预测之间的一致性。此外,即使标记数据在客户端可用(图 1 (a)),从未标记数据中学习也可能导致模型忘记模型从标记数据中学到的内容。为了解决这些问题,我们将模型参数分解为两个,一个用于监督学习的密集参数和一个用于无监督学习的稀疏参数。这种稀疏的加性参数分解确保了对标记和未标记数据的训练是有效分离的,从而最大限度地减少了两个任务之间的干扰。我们通过仅在通信轮次中发送参数的差异,进一步降低了分解参数的通信成本。
研究了两种不同的场景,即局部数据被部分标记(Labels-at-Client)或完全未标记(Labels-at -server)。学习多个客户端之间的客户端间一致性,并分解模型参数以减少监督和非监督任务之间的干扰以及通信成本。展示了我们的方法FedMatch 在传统的客户端标签和新的服务器标签场景下,跨多个具有非i.i.d.和 i.i.d.数据。
传统的一致性正则化方法强制来自增广实例和原始(或弱增广)实例的预测,以输出相同的类标签。基于类语义不受小输入扰动影响的假设,这些方法基本上确保了同一输入的多个扰动之间预测的一致性。对于我们的联邦半监督学习方法,我们还提出了一种新的一致性损失,它将在多个客户机上学习的模型正则化,以输出相同的预测。服务器在每一轮通信中选择并广播 H 个助手代理。我们还在每个本地客户端使用数据级一致性正则化,类似于 FixMatch。在生成伪标签时,我们丢弃低于置信阈值 τ 的低置信预测的实例。然后我们使用伪标签 y 执行标准交叉熵最小化。
对于辅助代理,我们为每个客户端选择 H 个辅助代理作为与其他客户端最相关的模型。通过对位于服务器的相同任意输入 a 的预测 m 来表示每个模型(我们使用随机高斯噪声)。
一旦每个客户端将其权重更新到服务器,服务器就会尝试保留和更新来自客户端的所有模型嵌入 m1:K,并在当前轮 r 中在 m 上创建 K 维树(KD 树)用于最近邻搜索以快速选择下一轮中每个客户的助手代理。我们每 10 轮发送一次助手代理,如果某个客户端在上一步中尚未将其权重更新到服务器,那么服务器将在该轮跳过向客户端发送助手。
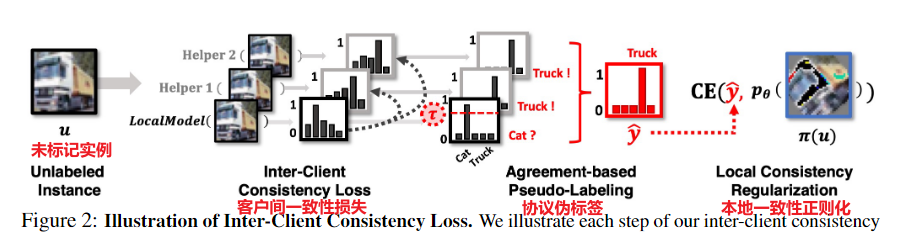
Inter-Client Consistency Loss:客户间一致性损失
FedMatch的核心思想在于一致性正则化(Consistency Regularization)技术,一种在半监督学习配置下从无监督数据中学习知识的技术,核心思想:对于一个输入,即使受到微小的干扰,模型的预测结果应该是一致的。因此,作者提出:本地模型输出结果和服务器选出的模型(大家共识的)的结果尽可能相似。对于如何选择大家共识的模型(客户端)作者提出基于可靠性的聚合方法(Reliability-based Aggregation)。
一种考虑本地模型可靠性(是否包含可靠的知识)的聚合方法,该可靠性还用于服务器进行helper agents的选择,即共识。FedMatch算法设计了一种考虑本地模型可靠性的聚合方法来对各个本地模型进行聚合,此处的可靠性指的是模型从数据中所学到知识对于解决相关任务的可靠性程度。在服务器端的模型可靠性计算也为之前所讲解的一致性正则化损失函数提供了helper agent的选择机制,即helper agent是每轮各个本地模型的集合中可靠性最大的H个模型的集合。此处的可靠性衡量其实就是一种各个客户端间所达成的共识机制。
我们可以将helper agent模型的输出看作是一种标签(在知识蒸馏中,softmax的输出其实就是相对于one-hot硬标签的一种软标签),那么上述公式就可以理解为本地模型的预测结果与各个共识模型提供的标签之间的差异应该尽可能的小,即上文所提到的一致性正则化思想。由此,我们即可从无标签数据中学习到各个样本中所包含的有效信息。
在标准的半监督学习方法中,对标记和未标记数据的学习是用一组共享的参数同时完成的。然而,由于这不适用于不相交的学习场景(图1(b)),并可能导致忘记标记数据的知识(见图6(c)),我们通过将模型参数分解为两组参数,一组用于有监督学习,另一组用于无监督学习,将有监督学习和无监督学习分开。为此,我们将模型参数θ分解为两个变量,监督学习的σ和非监督学习的ψ,这样θ=σ+ψ。我们对σ进行标准监督学习,同时在训练期间保持ψ不变,将损失项最小化。我们还在 ψ 上添加了 L2 和 L1 正则化,使得 ψ 是稀疏的,同时不会偏离 σ 所学的知识。
- 从标记数据中保存可靠的知识:我们凭经验发现,使用一组参数对标记和未标记数据进行学习可能会导致模型忘记从标记数据中学到的知识(见图 6(c))。我们的方法可以通过仅在监督学习中使用不相交的参数来有效地防止任务间干扰。
- 降低通信成本:无监督参数ψ的稀疏性允许降低通信成本。此外,我们通过减去每个参数的学习知识来进一步最小化成本,使得 Δψ = ψl r - ψG r 和 Δσ = σl r - σG r ,并且仅将差异 Δψ 和 Δσ 传输为稀疏矩阵用于客户端到服务器和服务器到客户端的成本。
- 不相交学习:在联邦半监督学习中,标记数据可以位于客户端或服务器,这需要模型的学习过程具有灵活性。我们的分解技术允许监督训练的模型在别处单独完成。
labels at client:用户有一部分标签,大部分数据没有标签。本地学习σlr1:A 和 ψlr1:A,本地训练完成后,客户端将学习到的知识 σlr1:A 和 ψlr1:A 更新到服务器。然后,服务器在嵌入基于模型相似性的局部模型之后分别聚合 σl1:A 和 ψl1:A 并创建 KD-Tree 以快速检索每个客户端的前 H 个最近邻居 ψh1:H。在下一轮,服务器传输聚合的 σr+1 和 ψr+1。对于辅助代理,服务器每 10 轮检索 H 个辅助代理 ψh1:H 给每个客户端。
labels at server:标记的数据仅在服务器上可用,因此服务器上的全局模型学习标记数据,而客户端的本地模型仅学习未标记数据。全局模型 G 在服务器上的标记数据 SG 上学习 σ,本地客户端 学习 ψl1:A,本地训练完成后,客户端将学习到的知识ψl1:A更新到服务器。然后,服务器根据模型相似性嵌入本地模型,并创建一个 KD-Tree,用于快速最近邻搜索,为每个客户端搜索前 H 个最相似的 ψh1:H 模型。在下一轮,服务器传输其学习的 σr+1 和聚合的 ψr+1。服务器每 10 轮通信向每个客户端传输 top-H 相似ψh1:H。
在这项工作中,我们介绍了联邦半监督学习(FSSL)的两个实际场景,其中每个客户端只使用部分标记的数据学习(客户端的标签场景),或者仅在服务器上使用受监督的标签,而客户端使用完全未标记的数据(服务器上的标签场景”)。为了解决这个问题,我们提出了一种新的方法,联邦匹配(FedMatch),它引入了客户端间的一致性损失,旨在最大限度地提高针对不同客户端训练的模型之间的一致性,不相交学习的参数分解,将参数分解为一个用于标记数据,另一个用于未标记数据,以保存可靠的知识,降低通信成本,以及不相交学习。
模型聚合:由上式可以看出,该聚合方法其实就是基于模型在公共验证集上的分类准确度来对各个模型进行加权聚合。 除此之外,在服务器端的模型可靠性计算也为之前所讲解的一致性正则化损失函数提供了helper agent的选择机制,即helper agent是每轮各个本地模型的集合中可靠性最大的模型的集合。此处的可靠性衡量其实就是一种各个客户端间所达成的共识机制。
resnet
数据划分:
batch-iid:将60000个实例分成训练集(54000)、有效集(3000)和测试集(3000)。我们为每个客户端(K=100)每个类(C=10)提取5个标记实例作为标记集S,其余的实例(49000)用作未标记数据au,这样我们就可以将S和U均匀地分成Sl1:100和Ul1:100,这样局部模型在训练时就可以在相应的标记和未标记数据上学习
Batch-NonIID(类不平衡):这个任务的设置与Batch-IID任务基本相同,除了我们任意控制每个客户端每个类的实例数量的分布,以模拟类不平衡的环境。
|
|
–
CODE:
数据增强之RandAugment,blog:[1],[2],[3]。code:[1]
这就有了深度学习天生的一个短板:数据不够多、不够好。而数据增强就是解决这一问题的有效办法。
数据增广可以显著提高深度学习的范化性能,与此同时,在半监督机制下因为对原有数据集进行了扩充,从而增加了数据集的鲁棒性
tensorflow:1
with tf.GradientTape() as tape 梯度带 Tensorflow自动求导API,[1],[2],[3]
scipy.spatial.KDTree 二叉树结构,[1],[2],[3]
helpclient
网络层layers:1
|
|
|
|
|
|
|
|
聚合到组再聚合、Benchmarking
-
Improving Semi-supervised Federated Learning by Reducing the Gradient Diversity of Models -
Zhang Z, Yang Y, Yao Z, et al. Improving semi-supervised federated learning by reducing the gradient diversity of models[C]//2021 IEEE International Conference on Big Data (Big Data). IEEE, 2021: 1214-1225.
在这项工作中,我们考虑的是更现实的场景,其中用户只有未标记的数据,而服务器有一些标记数据,并且标记数据的数量小于未标记数据的量。
首先,我们发现在半监督学习中广泛使用的所谓一致性正则化损失(CRL)性能相当好,但具有较大的梯度分集。其次,我们发现批量归一化(BN)增加了梯度多样性。用最近提出的群归一化(GN)代替BN可以减少梯度分集并提高测试精度。第三,当用户数较大时,CRL与GN相结合仍然具有较大的梯度分集。基于这些结果,我们提出了一种新的基于分组的模型平均方法来代替FedA-vg平均方法。
主要基于客户端包含无标签数据,服务器端包含有限数量的带标签数据的场景下进行讨论
提出一种研究Non-IID数据分布的原则方法:一种衡量客户端间类分布差异的指标 Metric R for non-iid level,消融实验:研究各种因子对于SSFL性能的影响,验证了BN和GN这两种normalization方法的优劣性,提出一种grouping-based model averaging方法来加快联邦学习全局模型的收敛速率。
无标签数据处理:主要基于半监督学习中的自洽正则化思想,具体而言是对无标签数据进行数据增强前后模型预测结果应当一致,从而充分利用客户端的无标签数据。同时,还可以对无标签数据进行弱增强,然后模型预测结果作为伪标签,再对原数据进行强增广作为数据并对数据和标签进行交叉熵损失函数计算
**Metric R指标:**提出一种研究Non-IID数据分布的原则方法,即一种衡量客户端间类分布差异的指标
模型聚合方法:作者考虑到原先的聚合方式(服务器端平均聚合所有被采样的客户端),不同用户之间较大的模型差异性会极大的减小模型训练的速率,因此作者提出grouping-based model averaging方法来加快联邦学习全局模型的收敛速率。其思路是在客户端和服务器之间加入若干个组,先对客户端聚合参数到组,然后组聚合参数到服务器
**Normalization影响:**由于BN可能在不同客户端之间存在统计上的差异,同时最新研究结果表明GN优于BN在Non-IID情况下的监督任务的联邦学习,因此考虑使用GN
基于对大梯度分集的观察,我们提出使用GN和一种新的基于分组的模型平均方法。我们在各种场景中进行了广泛的评估,以评估我们的解决方案。结果表明,即使与现有的半监督或监督FL算法相比,我们的SSFL方法也能获得更好的测试精度。
知识蒸馏
-
Distillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training with Non-IID Private Data -
无代码,blog
-
Itahara S, Nishio T, Koda Y, et al. Distillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training with Non-IID Private Data[J]. IEEE Transactions on Mobile Computing, 2021 (01): 1-1.
主要目标是:提高通讯效率,减少通讯开销,同时保证模型性能尽可能接近或高于联邦学习基准
DS-FL算法:使用一个全局共享的无标签数据集,相当于利用数据扩增的效果来提高模型性能。具体而言是将本地输出记为local logit,服务器端聚合输出记为global logit,然后利用服务器端global logit对本地local logit进行蒸馏;
ERA算法:考虑异构性数据集会导致样本信息的模糊性和较慢的收敛速率,论文提出ERA聚合算法,使得聚合的输出更加尖锐化,这样带来的好处有很多:例如在Non-IID配置下,可以起到加速收敛和模型稳定性作用、ERA算法的另一个附加功能是可以增加模型对于恶意用户所发起的攻击的鲁棒性(熵增相对较低)
DS-FL算法主要采用知识蒸馏思想:将本地模型看作学生,将local logit在服务器端聚合所得global logit作为教师的知识进行传递。ERA算法采用最小化熵的思想:因为Non-IID 数据分布会导致global logit产生更高的熵,从而导致其表达的信息更加模糊,造成模型收敛减速等问题,所以采用降低熵的做法来优化。
DS-FL算法:1)将本地模型视为student,将除自己外所有客户端输出的聚合看作teacher;2)本地需要计算每个标签的local loait,服务器要对所有客户端的local logit进行聚合形成global logit;3)关于logit可以看作为一种统计所得的软标签信息。
FedIRM
-
Federated Semi-supervised Medical Image Classification via Inter-client Relation Matching -
Liu Q, Yang H, Dou Q, et al. Federated semi-supervised medical image classification via inter-client relation matching[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2021: 325-335
目的是通过联合利用来自标记客户端和非标记客户端(即医院)的数据来学习一个联邦模型。针对这一问题,提出了一种改进传统一致性正则化机制的新方法,即一种新的客户端间关系匹配方案。该学习方案通过对齐所提取的疾病关系,明确地连接了标记客户端和未标记客户端之间的学习,从而缓解了未标记客户端任务知识的不足,促进了来自未标记样本的鉴别信息。
我们研究了一个实际的FL问题,该问题只涉及几个标记客户端,而大多数参与客户端是无标记的,即联邦半监督学习(FSSL)。我们第一次将这个问题扩展到一个更实际但更复杂的场景,其中涉及多个分布式标记和非标记客户机。
要解决这个问题,一个简单的解决方案是简单地将现成的半监督学习(SSL)方法集成到联邦学习范式上。然而,以前的SSL方法通常是为集中训练设置而设计的[2,10,17,29],它严重依赖于标签数据是可访问的假设,为从未标签数据中学习提供必要的帮助.例如,在基于一致性的方法[5,31]中,扰动不变模型预测的正则化需要同步标记数据监督,以便获得必要的任务知识,对施加一致性正则化的无标记数据产生可靠的模型预测。不幸的是,这种来自标记数据的密切帮助在ssl场景中丢失了,在这种场景中,本地数据集可能完全没有标记。这将使局部模型在基于一致性的训练过程中脱离原始任务,无法充分利用未标记客户端的知识。
如何构建标记客户机和非标记客户机之间的学习交互是FSSL的主要挑战。在这项工作中,我们的洞察力是通过传播他们在疾病关系中固有的知识来实现这一目标。这一想法的动机是观察到不同疾病类别之间的关系自然存在,并反映了医学图像分类背景下的结构任务知识,如疾病相似度度量[18,20]所证明的。更重要的是,这种疾病关系是独立于所观察的医院的,也就是说,一家医院的类似疾病在其他医院也应该是高度相关的。我们可以考虑从标记客户端中提取这种客户端不变的疾病关系信息,以监督未标记客户端的学习,从而减少未标记客户端的任务知识损失,有效地利用未标记样本。
我们提出了我们所知的第一个用于医学图像分类的FSSL框架,通过探索与客户端无关的疾病关系信息,以促进在未标记客户端的学习。该方法基于最先进的一致性正则化机制,在不同的输入扰动下增强预测一致性,以利用未标记数据。为了解决无标记客户端任务知识丢失导致学习退化的问题,我们引入了一种新的客户端间关系匹配方案,通过显式正则化无标记客户端,捕获与标记客户端相似的疾病关系,以保留判别性的任务知识。为此,我们建议从 pre-softmax 特征中推导出标记客户端的疾病关系矩阵,并设计一种基于不确定性的方案,通过过滤掉不准确的伪标签来估计未标记客户端的可靠关系矩阵。
fig1:Naive FSSL解决方案只是在未标记的客户机上执行无监督学习(例如一致性正则化),因此随着训练的进行,局部模型容易忘记原始的任务知识。我们的FedIRM明确地利用来自标记客户机的知识,通过对齐它们所提取的疾病关系,来协助在未标记客户机上的学习,从而减少了在未标记客户机上的任务知识的损失,并促进了从未标记数据中提取的歧视性信息。
我们采用建立良好的联邦平均算法FedAvg来更新全局模型,通过聚合局部模型参数,其权重与每个局部数据集的大小成正比。标记客户端的本地学习目标采用交叉熵损失来获取判别性任务知识。在未标记客户端,我们保留了最先进的一致性正则化机制,该机制通过在输入扰动下加强模型预测的一致性,以无监督的方式利用未标记数据.
如果没有标签数据监督的辅助,仅使用一致性正则化的无标签客户端的局部学习容易忘记原始的任务知识,无法充分利用无标签样本的信息。为了解决这一问题,我们提出了一种新的客户间关系匹配(IRM)方案,该方案利用疾病关系中固有的丰富信息,明确地从标记客户端提取知识,以辅助未标记客户端的学习。这种关系在不同疾病类别之间自然存在,反映了医学图像分类中的结构性任务知识,不受所观察医院的变化影响。基于此,我们的目标是在标记客户端和未标记客户端之间加强这种疾病关系的对齐,从而促进在未标记客户端学习判别信息,以保存这种结构任务知识。
标记客户的疾病关系估计:受到来自深度网络的知识蒸馏的启发,我们从深层模型捕获的类模糊度(即每个类的软标签)中估计疾病关系,并强制它们在标记和未标记的客户端之间保持一致。形式上,我们首先考虑标记客户端的关系估计。对于每个标记的客户端Dl,我们通过计算每个类别的平均特征向量vl c∈RC (c表示总类数)来总结模型对每个类c的知识,然后将得到的vlc缩放到一个软标签分布,在温度 τ > 1 [7] 下具有软化的 softmax 函数。这种对软标签sl的提炼知识传达了某一类样本的网络预测如何在所有类中普遍分布,反映了深度模型所捕获的不同类之间的关系。因此,来自所有类的软标签的集合可以形成一个软混淆矩阵xml = [sl1,…, sl C],它编码了不同疾病类别之间的类间关系,因此作为疾病关系矩阵。
未标记患者的可靠疾病关系估计:由于在未标记的客户端上无法获得数据注释,我们利用模型预测生成的伪标签来估计疾病关系矩阵。然而,如果没有在未标记的客户端提供足够的任务知识,在未标记数据上的模型预测可能是噪声和不准确的。因此,我们采用一种基于不确定性的方案来过滤不可靠的模型预测,只保留可信的模型预测来度量可靠关系矩阵。
根据关于不确定性估计的文献,我们用贝叶斯网络 [9] 的丢失来近似模型预测的不确定性。具体来说,我们在随机 dropout 下对输入 mini-batch xu 执行 T 时间前向传播,得到一组预测概率向量 {qu t }T t=1。然后将不确定性 wu 估计为预测熵,由于预测熵有一个固定的范围,我们可以过滤掉相对不可靠的预测,只选择确定的预测来计算疾病关系矩阵。
客户端间关系匹配的目标:我们的目标是强制未标记的客户端产生与标记客户端相似的疾病关系,以保存这种鉴别任务知识。具体来说,在每个联邦回合结束时,中央服务器从每个标记的客户端收集关系矩阵Ml,并将它们平均起来,计算出一个表示从所有标记数据中捕获的一般疾病关系信息的矩阵M,然后将得到的M传递给未标记的客户端,以监督其下一轮本地培训。
我们在两个重要的医学图像分类任务上验证了我们的方法,包括:来自大脑CT的颅内出血(ICH)诊断和来自皮肤镜图像的皮肤病变分类。因此我们从数据集中随机抽取 25000 个切片,其中包含 ICH 的 5 个子类型之一进行评估。然后将这些样本随机分为 70%、10% 和 20% 用于训练、验证和测试。由于该数据集中的多个切片可能来自同一患者,因此我们确保三个切片中不存在重叠患者以进行有效评估。我们对这两个任务执行相同的数据预处理。具体来说,我们首先将原始图像的大小从 512 × 512 调整为 224 × 224。为了使用预训练模型,我们使用从 ImageNet 数据集收集的统计数据对图像进行归一化,然后再将它们输入网络。
为了模拟 FL 设置,我们将训练集随机划分为 10 个不同的子集,作为 10 个本地客户端。按照 SSL [28] 中的实践,我们在 20% 的标记数据下评估模型性能。
采用DenseNet121[11]作为医学图像分类的骨干利用两种类型的扰动来驱动一致性正则化,包括输入数据的随机变换(旋转、平移和翻转)和网络中的dropout层。局部训练采用动量为 0.9 和 0.99 的 Adam 优化器,并且标记和未标记客户端的批量大小均为 48。当全局模型稳定收敛时,我们总共训练了 100 轮联邦轮次,局部训练 epoch e 设置为 1。
比较:Fed-SelfTraining[32],该方法通过迭代更新模型参数和未标记数据的伪标签以期望最大化来在未标记的客户端执行自我训练;和 Fed-Consistency [30],它采用最先进的 SSL 策略,即一致性正则化,来利用未标记客户端的数据(与我们的方法相比,没有客户端间关系匹配)。我们还与仅使用标记客户端或所有标记客户端训练的 FedAvg [19] 模型进行比较,该模型用作 FSSL 中的基线和上限性能。
该方案明确利用从标记客户那里学到的区分关系信息来促进未标记客户的学习。如果没有 L_IRM 的监督,单纯从一致性正则化进行的局部训练很容易忘记原始任务信息,因此无法充分利用来自未标记数据的判别信息。
客户间关系匹配下的学习行为:正如所观察到的,随着联合训练的进行,标记客户的疾病之间的关系变得越来越清晰,这表明该模型逐渐捕获了这种结构性知识。值得注意的是,我们的方法中未标记的客户可以很好地保留这种疾病关系,具有高度一致的矩阵模式作为标记的客户和差异矩阵中的低响应。这一观察结果证实了转移这种区分性知识以促进未标记客户的学习的好处,并解释了我们的绩效提升。
我们在我们的方法中调查了不同标记的客户编号的影响:要的是,仅使用 40% 的标记客户端,我们的方法达到了 89.21% 的 AUC,这非常接近使用 10 个标记客户端(90.48%)训练的上限 FedAvg 模型。这认可了我们的方法利用来自未标记客户的数据来改进 FL 模型的能力。
我们最后分析了未标记的客户端数量对我们的 FSSL 方法和 FedConsistency 性能的影响,通过将标记的客户端数量固定为 2 并逐渐增加中的未标记的客户端数量。FSSL 性能随着未标记客户端数量的增加而提高,这表明在现实场景中聚合更广泛存在的未标记客户端以改进 FL 模型的潜力。值得注意的是,我们的方法在不同的未标记客户数量下始终优于 Fed-Consistency 方法,突出了我们提出的 FSSL 学习方案的稳定能力。
我们提出了一个新的 FSSL 框架,据我们所知,这是第一个结合未标记客户端来改进医学图像分类的 FL 模型的方法。为了解决 FSSL 中一致性正则化的缺陷,我们的方法包括一种新颖的客户端间关系匹配方案,以明确利用标记客户端的知识来辅助未标记客户端的学习。在两个大型数据集上的实验证明了有效性。我们的方法可扩展到 FSSL 设置中的非 IID 场景,因为所采用的疾病关系独立于观察到的客户并且不受图像分布的影响。
—》本文中为IID.
※RSCFed:随机抽样共识联邦半监督学习
作者–有没有相关论文,无
-
RSCFed: Random Sampling Consensus Federated Semi-supervised Learning
-
Liang X, Lin Y, Fu H, et al. RSCFed: Random Sampling Consensus Federated Semi-supervised Learning[C]//Proceedings of the IEEE/CVF Conference on
Computer Vision and Pattern Recognition. 2022: 10154-10163.
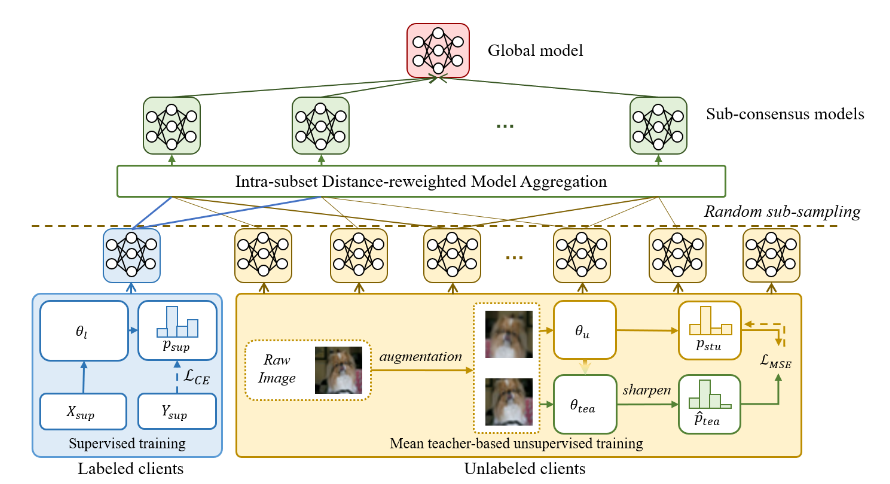
标记客户端:采用交叉熵损失 未标记客户端:采用基于Mean Teacher的一致性正则化
从选定的客户端收集模型,执行距离重加权模型聚合(DMA),得到子共识模型
DMA:动态增加接近平均模型的模型的权重->更接近平均模型的模型权重大一点
该场景下 标记和未标记已经分开,所以没必要使用参数分离的
resnet、cnn
在本文中,我们通过考虑来自完全标记的客户端、完全未标记的客户端或部分标记的客户端的模型之间的不均匀可靠性,提出了一种随机采样共识联邦学习,即 RSCFed。我们的主要动机是,给定模型与标记客户端或未标记客户端的偏差很大,可以通过对客户端执行随机子采样来达成共识。为了实现这一点,我们不是直接聚合局部模型,而是首先通过对客户端的随机子采样提取几个子共识模型,然后将子共识模型聚合到全局模型。为了增强子共识模型的鲁棒性,我们还开发了一种新的距离重加权模型聚合方法。实验结果表明,我们的方法在三个基准数据集(包括自然图像和医学图像)上优于最先进的方法。
#研究其在医学图像诊断[10、14、28]、图像分类[16]和目标检测[22]中的应用。
一项研究通过考虑每个客户端具有部分标记和未标记的图像来研究 FSSL。例如,郑等人。 [8] 引入了客户端间一致性损失,通过鼓励来自多个客户端的一致输出来改进全局模型。 FSSL [21, 28] 的另一行假设一些本地客户端具有完全标记的图像,而一些客户端包含未标记的图像,我们分别表示为标记的客户端和未标记的客户端。然而,现有方法有两个主要限制。首先,他们没有考虑本地客户端之间不独立且同分布的数据(Non-IID),这是 FL 的一个关键问题,可能会导致准确性下降 [9, 15]。其次,一些解决方案[21]在本地客户端之间共享相关矩阵,这可能会导致信息泄露。
本文研究了具有两种广泛使用设置的 FSSL:(1)联合训练完全标记和完全未标记的客户端; (2)联合训练部分标注的客户。一个直接的解决方案是将现有的 FSSL 方法 [21, 28] 扩展到非 IID 设置。然而,FedIRM [21] 和 Fed-Consist [28] 都无法推广到非 IID 设置。这是因为 FedIRM [21] 提出基于每个客户端具有相同的类关系的假设,在客户端之间共享一个类间相关矩阵。但是,在 Non-IID 设置下,由于本地客户端之间的异构数据,无法正确学习类关系,从而损害了模型性能。 Fed-Consist [28] 建议对标记和未标记客户的模型权重进行平均平均。然而,当未标记的客户端增加时,性能会显着下降,因为全局模型可能由未标记的客户端主导。调整标记和未标记客户端的聚合权重是一种解决方案,即增加标记客户端的权重,同时降低未标记客户端的权重。然而,这个结果实现了有限的性能。
为此,我们提出了随机抽样共识联邦学习,即 RSCFed,通过考虑在非 IID 设置下来自完全标记和完全未标记的客户端或来自几个部分标记的客户端的模型之间的不均匀可靠性,并且客户端之间没有任何信息泄漏。另一方面,使用几个部分标记的客户端进行训练也可能导致模型可靠性不均,因为每个客户端中的图像在数量偏斜和标签偏斜上分布不均。为了实现一个健壮的全局模型,我们的关键思想是将局部模型视为噪声模型,并在聚合到全局模型之前通过随机抽样提取几个共识模型。具体来说,在每个同步轮次中,我们随机子样本客户端并将子样本模型的平均权重记录为子共识模型。通过多次执行操作,我们通过聚合多个子共识模型来更新全局模型。为了从随机抽样的本地客户端中提取稳健的子共识模型,我们引入了距离重加权模型聚合 (DMA) 模块,该模块动态增加接近子共识模型的模型的权重,反之亦然。这个想法与随机样本共识 (RANSAC) [5] 具有相似的精神,如果它们远离模型,则将点识别为异常值。
• 在本文中,我们提出了一种新的 FSSL 方法,称为 RSCFed,以解决非 IID 本地客户端的不均匀可靠性。与现有的直接聚合本地客户端的 FSSL 框架不同,RSCFed 提出了通过聚合多个子共识模型来更新全局模型的概念。• 为了改进子共识模型,我们引入了一种新颖的距离重加权模型聚合(DMA)模块,该模块将每个采样的本地客户端的权重动态调整到子共识模型。• 对三个公共数据集的实验表明,我们的 RSCFed 明显优于其他最先进的 FSSL 方法。我们进一步表明,随着未标记数据的比例越大,RSCFed 可以实现的改进越好
联邦学习的两个常见问题是系统异质性和统计异质性,指的是客户端之间计算能力和数据分布的不一致。一项开创性的工作提供了最广泛认可的 FL 基线 FedAvg [23],随后是许多异构 FL 解决方案,可分为两个分支:面向本地训练的方法 [16] 和面向模型聚合的方法。
面向本地训练的方法:在局部目标中添加了一个额外的正则化项,表示全局模型和局部模型之间的距离,从而对模型漂移进行约束。证明控制变量可以纠正局部模型更新。引入了一个对比损失项来防止局部模型出现局部最小值。
面向模型聚合的方法:在平均之前对接收到的局部梯度进行归一化。使用贝叶斯非参数方法进行逐层平均。将已知的全局和局部模型视为来自假设分布的样本,其中另一组模型被采样为教师模型,然后在未标记数据可以保存在服务器上的假设下用于服务器端知识蒸馏。进一步将单个全局模型扩展到多个全局模型,其中在每个客户端计算对所有全局模型候选者的亲和力。最后,根据每个客户,以个性化的方式通过亲和力对全局模型进行加权平均。然而,这些方法是为有监督的联邦学习而开发的,而我们的工作侧重于 FSSL,其模型可靠性来自标记和未标记的客户端。
标准半监督学习旨在以集中方式优化具有标记和未标记数据的模型。学习范式通常涉及基于平滑的一致性正则化 [4, 18, 25, 31],基于熵最小化的自我训练方法 [3, 35] 及其组合 [1, 7, 24]。融合解码器预测和来自弱增强图像的自注意力GradCAM,以获得可靠的伪标签,从而可以监督强增强图像的预测。基于自我训练和协同训练的方法在数据中心化数据方案中也很受欢迎。然而,这些方法在训练过程中需要标记图像和未标记图像。而在 FSSL 设置中,标记和未标记的图像分别分散到标记和未标记的客户端。本文没有研究如何通过标记和未标记图像获得好的模型,而是提出了一种新的模型聚合方法,该方法具有来自标记和未标记客户端的不均匀模型可靠性。
FSSL 可以大致分为两类。一类假设每个本地客户端都包含部分标记的图像。让每个客户端同时保存标记和未标记的数据。假设标记数据仅在服务器上可用。假设标记和未标记的数据是孤立的,但存在客户端间样本重叠。
另一类认为一些客户端被完全标记,而一些客户端包含未标记的图像。提出学习类间关系,该关系从有标签的客户那里学习,并在有标签和无标签的客户之间共享。但是,此方法在非 IID 设置下失败,因为由于数据异质性,客户端之间的类间相关性不再相似。引入了一种基于一致性的方法,其中将不同的增强应用于未标记的图像,使其预测相似性最大化。虽然一致性损失仍然适用于异构数据,但他们的方法只涉及一个未标记的客户端。但是,我们发现这些方法无法推广到非 IID 设置。我们提出的 RSCFed 显示了它在 FSSL 下对不均匀模型可靠性的鲁棒性。
RSCFed 的概述。对于一些标记和未标记的本地客户端,我们的 RSCFed 在每一轮中分别执行以下步骤:(1)随机抽样本地客户端; (2) 将当前全局模型分配给选定的客户端作为初始化,并对选定的客户端进行本地训练; (3)从选定的客户端收集模型,执行距离重加权模型聚合(DMA),得到子共识模型; (4) 多次重复步骤(1)-(3),得到一组子共识模型; (5) 从子共识模型中聚合一个新模型作为下一个全局模型。
RSCFed 概述。标记和未标记的客户端分别通过监督交叉熵损失 LCE 和基于均值教师的一致性损失 LM SE 进行优化。我们的 RSCFed 使用距离重加权模型聚合 (DMA) 在所有客户端中执行多个随机子采样,以增加接近子共识模型的客户端的权重,反之亦然。该模块可以帮助避免偏离的局部模型对全局模型的影响。
在该方法中,我们考虑了具有完全标记和完全未标记客户端的 FSSL。有标记的客户端有m个,未标记的客户端n个。
本地训练:在第 t 轮同步开始时,所有局部模型都使用当前全局模型 θt glob 进行初始化。我们提出的 RSCFed 分别对标记和未标记的客户端采用标准的监督和无监督训练。为简化起见,我们默认本节中的所有表示都发生在第 t 轮同步中。
标记客户端:采用交叉熵损失 LCE 作为目标函数,然后客户端在训练后将 θl 返回给服务器。未标记客户端:采用基于Mean Teacher均值教师的一致性正则化框架[blog],并将学生模型视为本地模型。当这个客户第一次被选中时,教师模型 θtea 被初始化为 θ0glob。在未标记客户端的每次局部迭代中,一批输入图像被增强两次,并分别输入学生和教师模型。在生成了他们的预测pstu和ptea之后,我们利用[1]中定义的“锐化”来提高教师预测的温度,因此 ptea 被“锐化”为 ^ptea,样本被推离决策边界以生成更好的一致性对齐目标。通过对不同增强输入的两种预测,均方误差损失被用作未标记客户端的局部目标。只有学生模型通过局部函数更新。教师模型在每次局部迭代后通过指数移动平均接收学生模型参数:未标记的客户端最终将学生模型作为其本地模型 θu 返回。
一致性正则化损失是Student模型和Teacher 模型的预测之间的距离,并且该差距应该最小化。
-->从服务器端接收的为教师模型,然后将(经过知识蒸馏?并不是)学生模型作为本地模型,然后更新学生模型,上传学生模型。
t越大,结果越平滑,让本来t=1时大的结果变小一点,小的变大一点,得到的概率分布更“平滑”,相应的t越小,得到的概率分布更“尖锐”,这就是t的作用
随机抽样共识 FL:我们提出了 RSCFed,一种具有随机子集采样和距离重加权模型聚合的新型 FSSL 框架,以从严重偏差的局部模型中获得更稳健的全局模型。更具体地说,我们对所有客户进行随机抽样,并收集他们上传的模型以挖掘他们的基本共识。然后,我们通过聚合收集的模型获得子共识模型,其中引入了距离重加权模型聚合(DMA)策略来动态调整它们的权重。我们将这两个步骤重复 M 次,得到一组子共识模型。最后,我们聚合子共识模型集以获得每一轮的全局模型。
多重随机子采样。提出了随机子采样来提取子共识模型。我们建议执行多个随机子采样以获得多个子共识模型。为了实现它,在同步轮 t 开始时,我们执行 M 次独立随机子采样以对 K 个客户端进行采样。然后服务器将全局模型 θt glob 发送给采样客户端,然后对采样客户端执行本地训练。请注意,如果客户端在一轮中被多次采样,我们不需要再次发送全局模型进行初始化,以节省通信成本。
距离重加权模型聚合。为了增强子共识模型的稳健性,我们提出了一种新颖的距离重加权模型聚合(DMA),而不是像 FedAvg [23] 那样聚合多个选定的客户端。我们的关键思想是动态增加接近平均模型的模型的权重,反之亦然。对于抽样客户的本地模型,我们使用我们设计的基于模型距离的重新加权策略执行模型聚合。对于每个子集,我们首先计算子集内平均模型。我们的 DMA 不是简单地平均本地客户端,而是为每个子集中的第 i 个客户端动态扩展 wi。模型距离除以局部数据量 ni,以减少局部迭代对模型漂移的影响。然后我们将子集内模型权重标准化为 [0, 1]。在得到一组子共识模型后,我们将它们的等权平均表示为最终的全局模型。
-->更接近平均模型的模型权重大一点。
基准数据集。 SVHN 和 CIFAR-100 ,ISIC 2018。对于所有三个基准数据集,每个数据集的 80% 图像被随机选择用于训练,其余图像用于测试。对于 SVNH 和 CIFAR-100,我们将这两个数据集的原始 32×32 图像调整为 40×40 像素,随机裁剪一个 32×32 区域,然后对裁剪区域进行归一化操作以生成我们网络的输入.关于 ISIC 2018,我们将原始图像的空间分辨率从 600×450 调整为 240×240,随机裁剪一个 224×224 区域,并将裁剪后的区域归一化作为网络输入。
特征提取主干。在 SVHN 和 CIFAR-100 上进行训练时,我们按照 [16] 采用简单的 CNN 作为特征提取主干,其中包含两个 5×5 卷积层、一个 2×2 最大池化层和两个全连接层。对于 ISIC 2018 数据集,我们使用 ResNet-18 [6] 作为特征提取主干。之后,我们使用两层 MLP 和全连接层在每个客户端为所有数据集制定分类网络。此外,在比较方法的每个客户端也使用相同的分类网络,以进行公平比较。
联邦学习设置。我们遵循现有方法 [16,26,32] 使用 Dirichlet 分布 Dir(γ)(所有三个基准数据集的 γ=0.8)在客户端中生成非 IID 数据分区。在这样的 Non-IID 数据划分策略之后,每个客户端的类和样本的数量彼此不同,因此并非所有客户端都包含来自所有类的样本。
实施细节。我们使用 SGD 优化器,并使用 PyTorch 实现我们的方法。
FSSL 设置。在此设置中,训练数据集包含 10 个客户端:一个带有标记图像的标记客户端和 9 个仅带有未标记样本的未标记客户端。
尝试增加聚合权重对于集合中的标记客户端{20%, 30%, 50%, 70%}。我们的实验表明,50% 达到了最好的分类准确率。因此,我们根据经验将标记客户端的权重扩大到 50% 左右,其他 9 个未标记客户端在每个 FSSL 同步轮中共享剩余的 50% 权重。当我们重新实现 FedIRM [21] 和我们的 RSCFed 时,这种聚合权重也用于保证深度模型的性能。
比较方法。我们将我们的网络与最先进的 FSSL 方法进行比较,包括 (1) FedIRM [21],它计算标记客户端的类间关系并将其用作未标记客户端的额外监督; (2) Fed-Consist [28],它计算来自平均教师框架 [25] 中未标记数据的多个增强输入的预测的一致性损失。我们还将我们的网络与使用所有 10 个标记客户端训练的 FedAvg [23] 作为上限分类结果,以及使用所有 1 个标记客户端训练的 FedAvg [23] 作为下限分类结果进行比较;见表 1。此外,我们引入了四个广泛使用的指标来比较不同的方法,它们是准确度、ROC 曲线下面积 (AUC)、精度和召回率。
定量比较。表 1 根据四个指标报告了我们的网络和最先进方法在三个基准数据集上的定量结果。基本上,我们可以发现两种比较的 FSSL 方法(即 FedIRM [21] 和 Fed-Consist [28])和我们的网络的结果介于 FedAvg [23] 获得的上限结果和下限结果之间] 对于所有三个基准数据集。从这些定量结果中,我们可以观察到我们提出的 RSCFed 在三个基准数据集上的指标性能优于所有竞争对手。我们优于 Fed-Consist 的性能表明通过我们网络中的聚合策略获得的泛化能力增强。此外,我们的网络在三个数据集的四个指标方面也优于 FedIRM。背后的原因是由于我们工作中所有客户端的非 IID 数据分布,客户端之间类间关系的一致假设是不正确的。
FSSL 设置。为了更好地阐述 RSCFed 在解决不均匀模型可靠性方面的能力,我们进一步将 RSCFed 扩展到 FSSL 的另一行,其中所有本地客户端都被部分标记,即只有 10% 的图像被标记。对于此设置,我们采用与之前设置相同的网络主干。由于所有客户端都被部分标记,因此不执行权重缩放操作。可以看到,我们的 RSCFed 在大多数指标上仍然优于 Fed-Consist [28] 1% 以上。
进行消融实验以评估我们的 RSCFed 的主要组件(子采样和聚合策略)的有效性,并进一步讨论其在不同未标记比率、不同通信成本限制和不同超参数方面的性能。
为了评估我们在不同未标记客户端比率下的性能,我们进行了消融研究,以根据不同客户端数量比较不同的联邦半监督学习方法,其中标记客户端的数量在所有方法中都设置为 1。随着未标记客户的数量从 4 个增加到 49 个,准确率提高从 1.51% 逐渐增加到 3.98%,AUC 提高从 0.5% 提高到 3.5%。
通信成本限制。请注意,比较的两种方法在每个同步轮中通过了 10 个本地客户端模型,而我们的方法考虑了 15 个本地模型,因为我们使用了 3 个子采样操作,并且在每个子采样操作中选择了 5 个本地客户端。因此,我们方法的通信成本是 Fed-Consist [28] 的 1.5 倍。
超参数。请注意,我们的网络有两个主要的超参数,它们是子采样操作的数量 (M) 和每个子采样操作中使用的本地客户端的数量 (K)。显然,我们根据经验设置 M = 3 和 K = 5。
这项工作提出了一个重要、实用但被忽视的联邦学习问题:非 IID 本地客户端的联邦半监督学习。考虑到标记和未标记客户端之间的可靠性不平衡,我们的关键思想是可以通过对客户端执行多次子抽样来达成共识。我们不是简单地聚合本地模型,而是通过对客户端进行随机子采样来设计子共识模型,并引入距离重加权模型聚合模块来聚合每个同步轮中的子采样模型。三个基准数据集的实验结果表明,我们的网络始终优于最先进的方法,这证明了我们方法的有效性。
对比了FedIRM
SemiFed
无代码
imFed-Semi
-
Dynamic Bank Learning for Semi-supervised Federated Image Diagnosis with Class Imbalance
-
Jiang M, Yang H, Li X, et al. Dynamic Bank Learning for Semi-supervised Federated Image Diagnosis with Class Imbalance[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2022: 196-206.
本文研究了类不平衡半监督FL(IMED-SEMI)的一个实际而具有挑战性的问题,它允许所有客户端只有未标记的数据,而服务器只有少量的标记数据。通过一种新的动态银行学习方案解决了这一IMFED-Semi问题,该方案通过利用类别比例信息来改善客户的训练。该方案由两部分组成,即为每个本地客户提取不同类别比例的动态银行结构,以及利用本地模型学习不同类别比例的子银行分类。
类别不平衡(class-imbalance)就是指分类任务中不同类别的训练样例数目差别很大的情况。
我们在两个公共现实医学数据集上对我们的方法进行了评估,包括25,000个CT切片的颅内出血诊断和10,015个皮肤镜图像的皮肤病变诊断。
关键挑战:首先,现有方法通常假设一个或多个客户端被完全标记,而不允许所有客户端都未被标记的极端但实际有利的情况。其次,客户之间的类别不平衡问题(由于不同的患者人口统计和疾病发病率[19,21])阻碍了模型的准确性,但尚未得到仔细考虑。
我们假设只有服务器持有少量的已标记数据,而所有客户端只提供存在类不平衡的未标记数据。现有的半监督方法通常对未标记的样本应用一致性正则化[8,14,23,24]或伪标记[1,2,29,31]。例如,FedPerl[2]通过对一组相似客户端的模型进行集成来获得未标记数据的伪标签,而FedIRM[14]通过在已标记客户端和未标记客户端之间添加类关系约束来强制实施一致性正则化。遗憾的是,这些方法需要对某些客户端进行部分或全部标记。此外,它们还受到类别不平衡问题的性能下降的影响,即未标记的客户端具有来自每个疾病类别的不同比例的样本。这样的局限性是因为,对未标记数据的样本级监督导致每个客户端模型训练局部地被其自己的多数类所支配,从而影响FL中服务器端的模型聚集。
解决IMFED-Semi问题的关键在于如何设计班级比例意识监管,以加强对未标记客户的训练。我们的见解是依靠服务器上的已标记数据来帮助未标记的客户端估计特定于类的比例。该算法借鉴标签比例理论[6,15,17],将数据分成多个子集,利用子集的标签比例信息对无标签客户模型的训练进行弱监督。换句话说,我们可以拆分客户端内部的数据来从伪标签中提取各种标签比例,因为使用软全局信息而不是不可靠的样本级伪标签来训练模型更有意义,特别是当客户端中的所有样本都未标记时。因此,如何获得准确的比例估计就成为一个重要的步骤,由于困难样本(Hard Sample)存在误分类问题,直接使用伪标签是不可靠的。
Hard Sample:错分成负样本的正样本,也可以是训练过程中损失最高的正样本。软:保留每项的概率,结果是各项的加权和(由各项商量);硬:只取某一项,结果就是该项(不可商量)
在本文中,我们针对 imFed-Semi 问题提出了一种新颖的动态银行学习方法。我们的方法由两部分组成,动态银行构建以提取每个客户内的各种类别比例信息,以及子银行分类以强制本地模型学习不同的类别比例。具体来说,动态银行在训练过程中迭代收集高置信度的样本来估计客户类别分布,并将样本拆分为存在不同伪标签比例的子银行。此外,还设计了一个先验转换函数,将原始分类任务转换为子银行分类任务,明确利用不同的类比例来训练局部模型。由于这种标签比例感知监督,本地客户端训练得到增强,以学习不平衡类的不同分布,以避免被本地多数类控制。我们在两个大型真实世界医学数据集上验证了我们的方法,包括 25,000 个 CT 切片的颅内出血诊断和 10,015 个皮肤镜图像的皮肤病变诊断。与许多最先进的半监督学习和 FL 方法以及综合分析研究相比,我们的方法的有效性已得到验证,这两项任务的性能都有显着提高。
方法概述。我们的方法构建子银行来收集可信样本并估计每个客户 c 的类别先验 (πk c )。然后通过使用先验转换函数学习不同的类比例来设计子银行分类任务。最后,提升局部模型以学习判别性决策边界。
分类任务的目标是通过使用服务器上的多个标记样本和存在此类不平衡客户端的大规模未标记数据来获得全局 FL 模型 fg: X → Y。
我们框架的 FL 训练范式采用流行的 FedAvg [16] 算法.然后,将全局模型广播回客户端进行本地训练,这样的过程不断重复,直到收敛。我们的服务器标签设置中的特殊做法是,在广播之前,更新全局模型以在服务器上使用标记样本进行额外一轮梯度下降。本地客户端执行无监督学习。
考虑到当前的半监督方法容易使每个客户端的局部训练由多数类主导,我们鼓励 FL 模型通过从全局角度利用不同的类比例来学习判别决策边界。受未标记样本的类比例学习的启发[15],我们设计了一个动态的银行学习方案,它估计了客户训练的类比例。具体来说,我们首先建立了一个动态库,以基于高预测概率的阈值来收集置信样本。然后,我们将动态银行拆分为 K 个子银行,以在本地呈现不同的类比例。通过进一步设计一个类先验转换函数,我们通过学习不同的类比例将 K-class 分类问题转换为 K-bank 分类。
动态银行建设。随着训练的进行,我们通过逐步存储置信样本来构建动态库。给定每个客户端的未标记样本 xc,我们将 pi(为便于表示,省略 c)表示为局部模型在所有类别中的最高预测概率,即 pi = max fc(xc i )。我们使用阈值 τα 来选择超过高概率的置信样本。此外,由于类别不平衡,少数类别往往代表性不足[22],导致局部模型的预测概率较低。我们进一步使用另一个阈值 τβ 来拯救代表性不足的未标记样本,这有助于保持类的多样性。
银行在开始时被初始化为一个空集,即 Bc,0 = φ。在每一轮之前,银行都会收集概率超过阈值 τβ 的样本进行训练。然后通过仅保留预测概率超过 τα 的置信样本来调整它。通过以这种动态方式构建银行,我们可以在每一轮逐步收集和使用更多样本来估计类分布。特别是,随着训练的进行,几乎所有的样本都被承诺包含在银行中,这有助于本地模型摆脱忽视次要类的问题。
类先验估计。我们进一步使用构建的动态银行中的类比例来为未标记客户的培训提供监督。这个想法是通过提出子银行分类的辅助任务来强调类先验知识,该任务明确地将原始分类任务与类先验联系起来。子银行分类任务的真实值可以在训练期间轻松获得,从而提供比传统伪标签更可靠的监督。
我们将设计一个先验转换函数,将原来的分类任务转化为新的子银行分类,用于本地客户训练。
为了依靠类先验来监督客户培训,我们引入了先验转换函数来明确连接子银行先验和类先验。先验转换函数自然地连接了类概率和代理标签。我们可以通过子银行分类来学习分类识别知识。
对比:我们将我们的方法与最近最先进的半监督 FL 方法进行比较,包括将一致性损失和伪标记引入 FL 的 FSSL (MIA'21) [29]、FedIRM (MICCAI'21) [14]它通过客户端间关系匹配增强一致性正则化,以及应用客户端间一致性并分解服务器和客户端训练的模型参数的 FedMatch (ICLR'21) [10]。此外,我们将广泛使用的半监督方法(FixMatch [24],缩写为 FM)纳入基线 FedAvg [16] 和现有的用于类不平衡问题的 FL 算法,包括 FedProx [12] (MLSys'20)和 FedAdam (ICLR'21) [18]。
显著的改进得益于我们的动态银行学习方案,该方案有效地提供了特定于类分布的监督,以缓解由多数类主导的模型。
动态银行的学习过程。我们研究了我们提出的方法在 ICH 数据集上关于动态银行构建和类先验估计的学习行为。一开始,动态银行 Bc 逐渐收集到更多置信度的样本,使类先验估计接近真实,准确率迅速提高(从 74% 提高到 82%)。随着收集的样本越来越多,模型需要时间来逐渐适应不同的类别比例,最终银行几乎包含了所有样本(98%)。局部训练变得稳定,准确率高,估计误差低。
我们为具有挑战性的 imFed-Semi 问题提出了一种新方法。我们提出的动态银行学习方案为本地客户训练提供类比例感知监督,与其他最先进的半监督学习和 FL 方法相比,显着提高了全局模型性能。我们的方法的有效性在两个大规模的真实世界医学数据集上得到了证明。所提出的动态银行构建也适用于其他场景,例如自监督学习。未来,我们将进一步探索动态银行建设,通过整合来自其他客户的信息来解决处理更严重的类别不平衡的潜在限制,即每个本地客户可能无法涵盖所有可能的疾病类别。
在本文中,我们提出了一种用于医学图像分析的稳健且标签高效的自监督 FL 框架。具体来说,我们在现有的 FL 管道中引入了一种新颖的分布式自监督预训练范式(即直接在分散的目标任务数据集上预训练模型)。基于 Vision Transformers 最近取得的成功,我们采用掩码图像编码任务进行自我监督预训练,以促进更有效地将知识转移到下游联合模型。
Private Semi-Supervised Federated Learning
在这项工作中,我们设计了一个有效的联邦半监督学习框架(FedSSL),以充分利用标记数据源和非标记数据源。我们在所有参与代理之间建立统一的数据空间,以便每个代理可以生成混合数据样本,以促进半监督学习(SSL),同时保持数据局部性。我们进一步表明,FedSSL可以集成不同的隐私保护技术,以最小的性能下降为代价防止标记数据泄漏。在SSL任务中,只有0.17%的MNIST和1%的CIFAR-10数据集作为标记数据,我们的方法可以比最先进的方法实现5-20%的性能提升。
我们建议学习一个全局生成模型,在所有数据源之间建立统一的数据空间,使每个代理生成标记数据实例,用于本地模型训练。我们联合优化了训练局部模型F以估计生成样本的准确标签的目标和训练生成器G以根据F推断的标签提供真实的数据impups的目标。为了防止大量未标记数据的训练发散,我们进一步用自构造和现实主义最大化目标对模型进行正则化。
我们设计了一种对标记数据源和非标记数据源分别采用顺序和并行训练步骤的混合训练策略。本设计顺利地集成了FedSSL中的差分隐私(DP)方案,防止对标记数据的过度访问。
我们设计了一种混合数据生成策略,通过建立统一的数据空间而不进行直接的数据交换来利用有标签和无标签的数据源
经典的SSL方法包括伪标记和熵最小化。数据增强方法,如MixUp 、MixMatch 和FixMatch 也被开发并集成到DL模型中。他们对数据进行插值,并用随机比率标记来扩充训练数据。然而,现有的方法只能应用于集中式训练范式,而我们的方法可以有效地应用于分布式数据源。
设F为带参数w的学习模型,将数据映射到标签空间F: D→Y,全局FL目标是在所有数据源上最小化联合训练目标L,其中局部目标Lk为特定于任务的局部训练目标,如用于分类的交叉熵损失。
第一种类型的源拥有一些已标记的数据实例(没有未标记的数据),我们将具有这种源的代理称为支持代理(S-agents)。另一种类型的源拥有所有未标记的数据实例,我们将具有这种源的代理称为查询代理(Q-agents)。我们的研究任务是通过FL范式下的SSL来提高q -agent和s -agent的集体能力。
–
本文提出一种基于生成网络的方法,联合少量标签源,与大量无标签源,联合训练机器学习模型。该方法可以充分利用大量的无标签数据协助进行训练,实现有效的分布式半监督学习。
数据增强通过生成大量相同标签数据来增强数据集;伪标签技术通过使用训练中的模型,给无标签数据生成伪标签并进一步用于训练;数据混合增强MixUp、MixMatch等方法通过对两个数据和对应标签的分别叠加,来生成混合数据及对应的混合标签,用作增强的数据来提高模型学习类别边界的能力。
本文的工作要解决如何利用联邦学习进行模型的本地训练和全局融合,实现有标签和无标签数据的混合增强,使得标签源和无标签源能够共享数据空间进行联合模型训练,同时保护个人数据不被泄露。同时我们提出一种严格的隐私保护机制,防止标签源的数据泄漏到其他源上
本文设计了一种基于生成式(generative)模型的数据混合增强方法,来实现分布数据源的利用。我们设立分类模型(Classifier) F,数据生成模型(Generator) G,生成数据的判别模型(Discriminator) D。F用于实际的半监督学习分类任务,G用于数据的生成任务, D用于G的联合训练。训练的目的是,通过各源的F、G的互相提高训练并融合,不断迭代提高分类模型F的任务精度,同时提高生成模型G的数据真实度。
为了防止上述隐私泄露的问题,本文提出一种全新的差分隐私 (Differential Privacy) 学习方式,来训练联邦半监督学习。其基本思想是,建立一个隐私损失总体值, 然后顺序的在有标签源上进行训练,之后再并行的在无标签源上训练。每一次使用有标签数据训练的时候,对数据加入随机高斯噪声N (0, s^2)。该有噪声的训练过程,可以提供一个使用该有标签数据训练导致的隐私损失的上界[5]。在训练过程中,达到隐私损失的总体值之后,立刻停止继续使用有标签数据进行训练。
- Rc-ssfl: Towards robust and communication-efficient semi-supervised federated learning system
- Liu Y, Yuan X, Zhao R, et al. Rc-ssfl: Towards robust and communication-efficient semi-supervised federated learning system[J]. arXiv preprint arXiv:2012.04432, 2020.
- 无代码。fedmix
自监督:iclr22https://mp.weixin.qq.com/s/A52lAKEaifC8W0nul7zt7g
客户端选择相关
客户端选择:https://www.baidu.com/s?ie=UTF-8&wd=%E9%9A%8F%E6%9C%BA%E6%8A%BD%E6%A0%B7%20%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0
数据采样:采样就是按照某种规则从数据集中挑选样本数据,大致分为3类:随机采样、系统采样和分层采样。
随机采样:就是从数据集中随机的抽取特定数量的数据,分为有放回和无放回两种。
系统采样:一般是无放回抽样,又称等距采样,先将总体数据集按顺序分成n小份,再从每小份抽取第k个数据。
分层采样:就是先将数据分成若干个类别,再从每一层内随机抽取一定数量的样本,然后将这些样本组合起来。
客户端选择的起因是因为数据的异构性
联邦学习在使用过程中面临的两大挑战:
数据异构(主要是用户间数据Non-IID) 系统异构(设备间通信和计算能力的差异)
通信效率https://baijiahao.baidu.com/s?id=1689217744608518370&wfr=spider&for=pc
元学习https://blog.csdn.net/qq_41444809/article/details/125707616
联邦学习中的数据异构性问题综述Federated Learning on Non-IID Data Silos: An Experimental Study
NIID-Bench提供了全面的划分策略和数据集来覆盖不同的Non-IID场景,文章还对几种算法进行了系统的比较,并讨论了机器学习在分布式数据中存在的问题及其未来的研究方向。具体的划分策略参考《Advances and Open Problems in Federated Learning》这篇文章中对Non-IID场景的分类。
2但是,由于在 FL 环境中存在大量的异构客户端(Heterogeneous client),这种随机选择客户端的方式会加剧数据异质性的不利影响。FL 环境中的异构性主要包括:(1)各个客户端设备在存储、计算和通信能力方面存在异构性;(2) 各个客户端设备中本地数据的非独立同分布(Non-Idependently and Identically Distributed,Non-IID)所导致的数据异构性问题;(3)各个客户端设备根据其应用场景所需要的模型异构性问题。客户端设备存在的这些异构性往往会影响全局模型的训练效率,客户端可能无法同时接受 FL 训练或测试。
提出了一种基于层级的联邦学习系统(A Tier-based Federated Learning System,TiFL),其核心是在每轮训练过程中自适应地选择训练时间相近的客户端参与到训练中,从而在不影响模型准确度的情况下缓解客户端数据异质性问题
在每轮训练中只识别和传输被认为是信息量大(例如,该过程距离其稳定状态还有多远)的客户端更新,从而减轻 FL 传输压力
提出了一个参与者选择框架(Oort),可以识别和挑选有价值的客户端进行 FL 训练和测试[5]。oort
提出了一个基于强化学习的经验驱动的联邦学习框架(Favor),它可以智能地选择参与每轮联邦学习的客户端设备,以抵消非独立同分布数据(Non-IID)引入的偏差,并加快收敛速度[6]。
提出了一个混合式联邦学习框架(Hybrid Federated Learning ,HFL),该框架包括一个同步内核和一个异步更新器,其主要目的是当 FL 环境中存在 stragglers 时增强 FL 的学习性能[7]。与经典联邦学习类似,同步内核局部更新序列的加权求和。异步更新器将 stragglers 的模型更新纳入到联邦模型训练过程中,这些 stragglers 可能比同步内核晚几步。
针对有偏客户端选择的联邦学习进行了收敛性分析。作者发现,偏向选择本地损失较高的客户端会提高整个模型的收敛速度。同时,作者提出了一种 Power-of-Choice 的客户端选择方法[9]。
基于聚类抽样进行客户选择 无偏抽样,
FedAvg和MD抽样是仅有的能保持最小server-clients通信代价的节点选择策略。FedAvg算法在每轮聚合时都只选择部分节点进行聚合,但它的选择方式是随机的,这将导致有偏抽样,且一些具有独特数据分布的客户可能难以被选中,进而影响全局模型的收敛。
(MD)抽样的节点选择概率与该节点的相对样本数量(样本数量在所有客户样本数量中的比例)相关。实验证明,MD抽样的表现优于FedAvg,且可实现无偏抽样。这可能使每一轮参与聚合的客户的数据分布与上一轮的存在巨大差异,且一些客户可能从头到尾未被抽到,进而降低了一些客户的代表性,并使全局模型的收敛存在较大的不稳定性。
聚类抽样是一种对MD抽样进行改进的新的无偏客户抽样方案,在保持最小的sever-clients通信代价的基础上,保证更小的节点选择差异性。同时为提高模型聚合时每个客户的代表性,聚类抽样保证了那些具有独特数据分布的客户可以被选中,从而实现更平滑、更快速的全局模型收敛。
MD根据相同的客户分布w 0 抽样m次,以获得m个客户并根据客户的相对样本数量进行全局聚合 ,聚类抽样则是根据m个客户分布每个分布抽样一次,获得m个客户并以 “客户 i 的样本数量在该分布w k ( t ) 中的比例” r k , i 作为聚合权重参与第 t 轮全局聚合。
满足命题1的聚类抽样算法有很多,文章提出了两种算法,分别是“基于样本数量”和“基于模型相似度”的聚类抽样。
根据“代表性梯度”,通过层次聚类将客户聚成k个类
Clustered Sampling: Low-Variance and Improved Representativity for Clients Selection in Federated Learning :这篇文章提出采用聚类抽样的方法进行节点选择,并证明了聚类抽样能提高用户的代表性、减少不同客户聚合时的权重方差。本文提出了基于样本数量和基于相似性的两种聚合抽样方法,并通过实验证明,采用聚类抽样的方法进行节点选择可以使聚合模型在训练和测试时取得更快更平滑的收敛性。
TrisaFed:异步联邦学习框架在异步联邦学习(AFL)中,其模型汇聚服务器在收集到少量本地模型后立即进行全局聚合,避免受到速度较慢设备的拖累。
相当于只选择部分客户端进行运行
联邦学习中基于Context-Aware 选择策略,本文主要研究了客户端的选择问题。即每一轮尽可能多地选择客户,并且在每个客户端预算有限的情况下。提出了一种COCS策略,该算法观察客户端本地计算和传输的辅助信息,作出客户端的决策,以在有限预算的情况下最大化网络运营商的效用。本文主要研究了HFL的客户选择问题,提出一种名为COCS的基于学习的策略。该算法基于MAB框架开发。通过获取客户端的计算信息,如计算资源、客户-边缘传输信息、带宽和距离等。能否成功地参与到相应的ES中取决于多方面的因素,这些因素被称为环境(context)。本文根据环境决定选择的客户端。
Client Selection for Federated Learning with Heterogeneous Resources in Mobile Edge
论文提出了FedCS协议,将传统联邦学习的随机选取参与用户改为由用户的资源情况选择尽可能多的“优质”用户来进行模型更新
FedCS协议的具体步骤:
- Resource Request 让随机的C*100%个clients给服务器发送自己的资源信息(无线信道状态、计算能力、任务相关数据集的大小等)
- Client Selection 服务器根据这些信息来评估模型分发、计算、上传步骤所需的时间,并选择参与本轮计算的用户
- Distribution 通过多播来将当前全局模型发送给选中的用户们
- Scheduled Update and Upload 用户们同时进行模型计算,然后依次上传updates
- Aggregation 服务器聚合updates并测试模型。 重复以上步骤直到模型收敛或到deadline。
https://www.bilibili.com/read/cv18409025
Active Federated Learning.
在每一轮客户端的选择不是随机的,而是以当前模型和客户端数据为条件的概率,以最大限度地提高效率。
首先提出给局部损失较大的客户分配较高的选择概率。
Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies
在本文中,我们提出了有偏客户选择策略的联邦优化的第一次收敛性分析,并量化了选择偏差对收敛速度的影响。我们发现偏向局部损耗较高的客户端选择可以获得更快的误差收敛。基于这种观点,我们提出了 Power-of-Choice,这是一种通信和计算效率高的客户选择框架,可以灵活地在收敛速度和解决方案偏差之间进行权衡。
选择随机抽样子集a⊆U中损失最大的tc客户,以减少选择偏差。
FedCor: Correlation-Based Active Client Selection Strategy for Heterogeneous Federated Learning。code
FedCor
an FL framework built on a correlation-based client selection strategy, to boost the convergence rate of FL. FedCor 一个建立在基于相关性的客户选择策略上的FL框架,以提高FL的收敛率。基于相关性的异构联邦学习主动客户选择策略
基于客户端的数据异构是阻碍联邦学习(FL)中有效训练的主要问题之一。在这项工作中,我们提出了基于相关性客户选择策略的fedcor FL框架,以提高FL的收敛速度。我们首先用高斯过程(GP)建模客户之间的损失相关性。在GP模型的基础上,我们推导出了在每一轮中都能显著降低全局预期损失的客户选择策略。此外,我们利用协方差平稳性,在FL场景下开发了一种高效的GP训练方法,且具有较低的通信开销。
我们提出了一种基于相关性的主动客户选择策略,该策略可以有效缓解数据异质性导致的准确性下降,并显著提高FL的收敛性。我们的关键思想主要基于以下直觉:
客户的贡献并不相等。例如,在“好”客户机上使用大型且平衡的数据集进行训练可以减少大多数客户机的损失,而在“坏”客户机中使用小型且极为偏颇的数据集训练可能会增加其他客户机的损耗。
客户端不独立贡献。选择一个客户机的影响取决于其他所选客户机,因为它们的本地更新将被聚合。
任务是选择两个客户机(不同的标记表示不同策略的客户机选择)来训练二进制分类器(如行所示)。独立选择两个局部损失最大的客户端(“Ind Result”)的选择策略不能减少全局损失。相比之下,我们的方法考虑了客户机之间的相关性(“Cor Result”),并得出了一个可以实现几乎最小全局损失的客户机选择(“Opt Result”)。
我们用高斯过程(GP)对客户流失变化进行建模,并提出了一种可解释的客户选择策略,在每一轮通信中显著降低了预期的全局损失。提出了一种利用协方差平稳性降低通信成本的GP训练方法。实验表明,采用该方法训练的GP能够很好地捕获客户端相关性。
主动客户选择,即尝试在每一轮中有策略地选择培训客户,而不是千篇一律地选择。Goetz等[6]首先提出给局部损失较大的客户分配较高的选择概率。Cho等人[4]选择随机抽样子集a⊆U中损失最大的tc客户,大小为d > C,以减少选择偏差。然而,两者在客户选择时都没有考虑到客户之间的相关性。
考虑到隐私和通信的限制,FL算法通常假设客户端部分参与并执行局部模型更新。
使第4.1节中损失减少的后视期望最大化。然后,第4.2节展示了经验证据,表明每一轮通信中损耗变化的先验分布可以建模为高斯过程(GP)。基于这一观察结果,我们利用GP来解决优化问题,并在第4.3节中获得了针对异构FL的有效客户选择策略。我们进一步分析了客户选择策略的选择标准,并在第4.4节给出了直观的解释。最后,在第4.5节中,我们描述了如何在通信约束FL中训练GP参数。
为了实现快速收敛,我们希望在每轮通信结束后找到能使全局损失减少最大的客户选择策略。在FL中,通过对不同客户端选择的多次试验来寻找最佳客户端选择是不切实际的,因为它引入了大量的通信和计算开销。因此,我们需要一种有效的方法来预测不同客户选择的全局损失减少量,并在非常有限的试验下做出决策。如果我们能够预测所选训练客户端的损失变化(∆ltKt (Kt)),我们就可以利用其后验均值预测全局损失变化并据此做出决策。
在贝叶斯优化中假设GP优先于未知目标函数是一种常见的做法。在一个通信轮中损失变化的先验分布遵循GP。具体来说,我们随机抽样一些客户选择,并执行一轮训练,以获得损失变化的样本。然后,我们对这些损失变化样本进行主成分分析,并绘制前几个主成分的直方图。图2中的红线是带有样本均值和样本方差的高斯PDF。我们可以看到这个高斯分布可以很好地近似样本的分布。
虽然我们已经得到了计算后验期望的概率模型,但仍然没有确定如何预测所选训练客户的损失变化。我们开发了一种预测损失变化的迭代方法,每次迭代选择一个客户端,如算法1所示。在一次迭代中有三个步骤:
1.在每次迭代中,我们首先为每个客户端k(如果它被选中的话)做出一个预测∆__ lt k。一般情况下,所选客户直接参与模型更新,损失减少较大。
2.客户端k *的选择是根据最后一步中所做的损失变化预测来最小化总体损失的后验期望
3.在选择客户端k *之后,我们更新GP以k *的损失变化预测为条件进行下一次迭代
我们的方法与传统的贝叶斯优化方法有一些相似之处:使用GP作为目标函数的先验,使用UCB和后验分布进行迭代选择。有一个关键的区别:在每一轮通信中,我们只使用预测而不是对全局损失变化的测量来确定客户选择,而传统的贝叶斯优化需要一系列的测量作为新信息来做出决策。对全局损失变化的测量将引入巨大的通信开销,在FL中是不可行的。
我们的选择准则考虑了客户之间的相关性,与那些只独立考虑每个客户损失的算法相比,我们的选择准则可以进行更好的选择
k ‘的选择不仅考虑它与其他客户端(rik ‘)的相关性,而且更倾向于与之前选择的客户端k1具有较小相关性的客户端rk1k ‘。这个准则惩罚了选择冗余,导致了数据多样化的客户端选择,从而减少了方差,使训练过程更加稳定。
实际上,不同客户损失变化之间的相关性主要来自于他们的数据集之间的相似性,这些相似性在FL过程中是不变的。
MDA: Availability-Aware Federated Learning Client Selection
Data Heterogeneity-Robust Federated Learning via Group Client Selection in Industrial IoT
自适应?
自适应选择,自适应分配权重?
Adaptive Aggregation自适应聚合
-
Asynchronous Federated Learning for Geospatial Applications (ECML PKDD Workshop 2018)1
联邦学习需要移动设备上传模型参数到联邦学习服务器进行聚合。传统的全局聚合的方法是同步的,即在一个固定的时间间隔内所有的设备都在本地进行一定轮数的训练,之后再聚合。对于给定的资源限制,需要研究如何通过调整聚合为适应性聚合,即能够根据资源限制和训练效率动态调整聚合时间来最大化训练效率
-
Asynchronous Federated Optimization 1
异步:在处理大量边缘设备时,可能会有大量掉队者。由于可用性和完成时间因设备而异,由于计算容量和电池时间有限,全局同步很困难,尤其是在联合学习场景中。异步训练相对更加灵活,在系统存在离散和异构延迟的情况下展现出了更通用的优势:无需等待其它设备参与全局聚合。然而,聚合权重由于某些设备模型的延迟上载需要被慎重考虑。
-
Adaptive Federated Learning in Resource Constrained Edge Computing Systems (IEEE Journal on Selected Areas in Communications, 2019) 1
-
The Distributed Discrete Gaussian Mechanism for Federated Learning with Secure Aggregation (ICML 2021)
Adaptive Federated Learning in Resource Constrained Edge Computing Systems
- Wei Wan, Shengshan Hu, Jianrong Lu, LEO YU ZHANG, Hai Jin and Yuanyuan He. Shielding Federated Learning: Robust Aggregation with Adaptive Client Selection
自步学习
自步学习:学习算法在每一步迭代中决定下一步学习样本。
样本的选择在自步学习中并不是随机的,或是在一次迭代中全部纳入训练过程中,而是通过一种由简到难的有意义的方式进行选择的。那么,选择简单的样本,也就是选择损失小的样本,也就是在线性回归问题中,和模型间距离近的样本。
SPL不是模型,只是一种不同的带权loss函数,所以在实现之前你需要选择一个model
自步学习研究的关键是假设样本的选择并不是随机的,或是在一次迭代中全部纳入训练过程中,而是通过一种由简到难的有意义的方式进行选择的。自步学习中从简单到复杂的样本选择过程是指,简单样本可以理解为具有较小的损失(smaller loss)或较大似然函数值(likelihood)的样本,复杂的样本具有较大损失(larger loss)的样本。
机器学习方法中也存在相关方法用于选择样本,例如:主动学习(active learning)和协同训练(co-training)。自步学习与二者的区别在于自步学习中所有样本的标签是完全存在的,在每次迭代过程中,我们可以通过计算预测值和标签的差别来选择置信度高的样本。而主动学习和协同训练往往应用于半监督学习框架,其中主动学习倾向于选择当前模型下确定性或置信度低的样本,而协同训练则是从无标签数据中选择分类器认为置信度可能高的样本,选择的样本并没有标签,无法断定估计结果是否准确。相比之下,自步学习则是选择预测值与真实值接近的、即分类器可以分辨的置信度真的高的样本。
主动学习的“主动”,指的是主动提出标注请求,也就是说,还是需要一个外在的能够对其请求进行标注的实体(通常就是相关领域人员),即主动学习是交互进行的。
而半监督学习,特指的是学习算法不需要人工的干预,基于自身对未标记数据加以利用。
开题主要研究
研究目标:
本课题的总体目标是针对联邦半监督学习存在的模型性能差和收敛速度慢等问题,进行基于自适应客户端选择的联邦半监督学习算法研究。首先,基于自步学习自适应选择客户端,衡量客户端模型对全局模型的贡献程度来选择客户端进行模型训练;其次,基于模型参数分离的思想,克服联邦半监督学习场景中数据的非独立同分布的不足,提升模型性能;然后,在相关数据集上验证所提算法的性能,分析算法的可行性和有效性,同时将所提算法应用于实际领域,比如多个医疗机构通过联邦学习来实现图像分类,为联邦半监督学习的落地应用提供参考。
主要内容:
本课题深入研究联邦学习理论、半监督学习理论、联邦半监督学习理论、自步学习理论、图像处理相关算法、图像分类理论与算法等知识,拟对基于自适应客户端选择的联邦半监督学习进行研究,旨在提升联邦半监督场景下模型的性能以及收敛速度。
本课题研究内容主要包括:
(1)在联邦半监督学习的基本架构中引入自步学习,衡量客户端模型对全局模型的贡献程度来选择客户端,从而实现自适应客户端选择;同时,基于模型参数分离思想,克服数据非独立同分布的不足,提升模型性能。
(2)提出新的基于自适应客户端选择的联邦半监督学习算法,并将其与现有的联邦半监督学习的算法进行性能比较和分析,验证所提算法的有效性和可行性。
(3)将提出的基于自适应客户端选择的联邦半监督学习算法应用于现实场景,比如联合多个医疗机构进行医学图像分类的实验,为现实应用提供参考。
关键问题:
(1)解决数据非独立同分布的问题,增加模型的泛化能力。非独立同分布是联邦学习设定的一个特殊的场景,该场景接近于现实世界中的数据,非独立同分布数据会导致模型过拟合、性能变差、聚合变慢等问题。
(2)客户端的有效选择问题。客户端选择是关乎联邦学习的一项重要任务,一些极端的或者有害的客户端会对全局模型的性能产生很大的损害,选取对模型有贡献有效的 客户端,则可以加快模型聚合,提升模型性能。
参数分离:即使是分开的,一部分有标签,一部分没标签。同样适用,只用有标签训练的时候会干扰之前在无标签上训练的结果。
相关疑问
再研究一下
模型复杂程度对于性能的影响
隐私保护对性能的影响
通信效率?实际上联邦学习更看重communication round这个参数,1
客户端价值评价?
加权平均
FedAvg,FedProx,SCAFFOLD和 FedNova 1,2
客户端选择的数量
异步有点自步学习的感觉,每次选择部分客户端。
客户端的数量?
NOIID-dirichlet
近期计划
2.fedlab框架 3.经典论文-》注重,客户端选择,模型聚合,损失函数? 4.自步学习研究一下 5.联邦半监督两篇 6.客户端选择相关 7.冗余,有害数据引入?
加油!!!
代码在哪?联邦学习代码库FedRepo https://zhuanlan.zhihu.com/p/502972718 https://github.com/lxcnju/FedRepo
家人们!!!设备选择方面的论文 有没有有代码的 我目前只看到贪婪算法的FedCS 而且没有开源。。。
很多框架都是用随机选择设备的选择方法,(如果别人论文没开源的话可以在框架的设备选择那里魔改
(比如大佬们的Fedlab就在这里
感觉要实现设备选择策略的话可以自己在这里做微调
–
The Non-IID Data Quagmire of Decentralized Machine Learning On the Convergence of FedAvg on Non-IID Data 这两篇
按照这个第一篇文章提供的参数尝试一下。
这是一个涉及深度学习随机性的深坑,尽量复刻前人的操作。
–
差分隐私:
Federated Learning With Differential Privacy: Algorithms and Performance Analysis
这篇很经典
流程,看他的那个算法我觉得挺清楚的。梯度下降用的fedprox
https://mp.weixin.qq.com/s/v9jMH6fbYhSs2wr1YfumvQ
–
联邦学习里资源分配相关文章 都是怎么仿真的呀 第一次接触这方面 大家有推荐好上手的代码吗可以参考下FedScale:https://github.com/SymbioticLab/FedScale,之前我们做过一些资源分配(如客户端选择)的工作
我自己看过的一些,可以关注一下cmu的virginia组
- DIVERSE CLIENT SELECTION FOR FEDERATED LEARNING VIA SUBMODULAR MAXIMIZATION
- Heterogeneity for the Win: One-Shot Federated Clustering
- Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies
- Birds of a Feather Help: Context-aware Client Selection for Federated Learning
个人认为fedlab的代码很好理解,和自己造轮子的想法比较像,拿来用和改都方便
单机simulation的时候用fedlab的standalone样例改改就行了
现在比较推荐master分支的版本,联邦数据集定义的话需要自己写dataloader,接口可以参考https://github.com/SMILELab-FL/FedLab/blob/master/fedlab/contrib/dataset/basic_dataset.py,同目录下有其他实现的划分数据集,可以看看。
https://github.com/SMILELab-FL/FedLab/tree/master/tutorials 这路径下有些tutorial可以学习自定义算法流程
–
fedlab有封装好的
我打算用来当baseline…
https://github.com/SMILELab-FL/FedLab
他们baseline的实现在这里
https://github.com/SMILELab-FL/FedLab-benchmarks
FedScale
–
Mr.Gulugulumaopao: 请问大家有支持graph split learning framework的repo么(每一方有全部节点的部分特征),刚刚看了federated scope,貌似都是每一方拥有部分节点的横向图联邦
要是我再聪明一点就好了: 自己写个不就好了
要是我再聪明一点就好了: 用pyg
要是我再聪明一点就好了: edge_index和y照搬,就把x拆开来(应该是这个意思吧
还有train test valid 的mask也照搬
要是我再聪明一点就好了: 就是pyg里把dataset下下来取dataset[0]就是pyg的data数据了
然后dataset[0].edge_index就是边的信息,y就是label,只要把x裁一裁就行了
Mr.Gulugulumaopao: 我只看过这篇耶,vertically federated graph neural network for privacy-preserving node classification
Mr.Gulugulumaopao: 目前看到的大部分split learning都是在image上
YoungFish: 我只见过这篇 https://arxiv.org/abs/2107.05917 Towards Representation Identical Privacy-Preserving Graph Neural Network via Split Learning
Truth: 已经有实际落地了吗?
PeterZHY🇭🇰: 翼方健数说他们有
PeterZHY🇭🇰: 实际我不太清楚
Truth: 嗯,谢谢
PeterZHY🇭🇰: 国内风投行业有个隐私计算四小龙的说法
PeterZHY🇭🇰: 蚂蚁金服 腾讯微众 华控清交 翼方健数
感觉可以关注一下MLsys会议,有FL投稿,这个会收的论文不多,但都比较硬.
learning with noisy label
blog:
- 有一定量的标注数据。– 通过搜索引擎、公开数据集等,很容易拿到。
- 标注数据的质量不高,存在或高或低的标注错误。
基于局部自正则化的抗噪声标签联邦学习 video
Towards Federated Learning against Noisy Labels via Local Self-Regularization
噪声记忆效应:正确标记的样本会被神经网络优先拟合,随后去拟合标签错误的样本。拟合正确的样本会降低的loss大一点,所以可能会偏向于先拟合正确的样本,再慢慢去拟合错误的样本
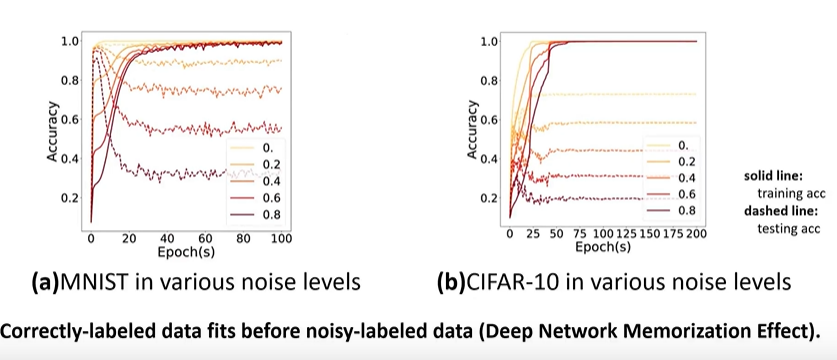
预实验,在fl场景下,也会出现这种现象,优先去学习正确的容易的模式
标签生成的方法,网络数据中的上下文,淘宝衣服的标题,上下文过滤的方式标签的识别;机器自动生成的标注,在小数据集下预训练的模型,会不可避免的带来标注的错误。
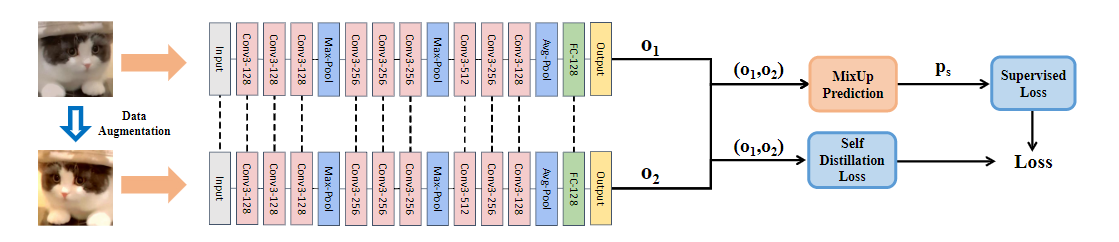
原始图像和增强后的图像,喂到同一个网络中,分别得到两个output的logits,送到两个组分(成分)中,一个去做混合预测,一个去做自蒸馏。将两种方式概括为,一个是隐私的约束:通过锐化运算和熵正则化提高模型识别的置信度;另一个是显示的约束:通过自蒸馏缩小原始实例和扩充实例的模型输出的差异
1、隐式
把预测进行混合。输出两个logits,o1,o2,通过softmax输入伪标签,p1,p2作为判别,然后做融合。
锐化操作:五分类,模型可以给出正确的预测结果为第二类,无论是增强后的图像还是原始图像都可以给出正确的结果,但是原始给出的标签是第一类,错误的。所以想通过这种方式,去加强模型对于自身判别的信心,从而抑制模型过度的拟合错误的标注。
然后拿出sharpen后的判别ps,去做交叉熵。能够尽可能的减少对于错误样本的拟合。
熵正则化:额外的优化
2、显式
希望对于原始数据和增强后的数据给出的判别比较接近。
知识蒸馏:实例级自蒸馏,通过知识蒸馏的温度去调整模型输出,以JS散度或L1 loss为度量
对logit做一个倍数的调整,调整后再去做softmax,得到概率输出定义为q1,q2。然后得出一个约束项,使得调整后的q1,2比较接近。具体采用JS散度或L1 loss为度量。
常见的两种噪声情况:对称噪声,Pairwise 对偶噪声。
Author kong
LastMod 2022-09-28