个性化联邦
Contents
fedbn
ditto
fedala
fedb
PFLLIB
数据集处理
dataset等三个文件夹mark directory as sources root–import下列的文件时才可以识别到
system
flscore:
client
server
optimizers
until:
generate_mnist.py:生成数据集mnist在dirpath下
rawdata:原始数据集60000trian10000test
test、train:20个npz文件
jason串格式化ctrl+alt+l(所有代码格式化都可用,和网易云冲突但是)
For the label skew scenario :标签偏移
In non-IID scenario, 2 situations exist. The first one is the pathological non-IID scenario, the second one is practical non-IID scenario.
第一种是病理性非 IID 场景,第二种是实际的非 IID 场景。例如,在病理性非 IID 场景中,每个客户机上的数据只包含特定数量的标签(可能只有2个标签) ,尽管所有客户机上的数据包含10个标签,比如 MNIST 数据集。在实际的非内部 ID 场景中,使用了狄利克雷分布。
划分数据的不同场景
1、python generate_mnist.py iid balance - # for iid and balanced scenario
IID,平衡–每个client包含所有类,且每个client分到的当前类的样本数相同
2、python generate_mnist.py iid - - # for iid and unbalanced scenario
IID,不平衡场景–每个client包含所有类,但数据量当前类对应的
3、python generate_mnist.py noniid - pat # for pathological noniid and unbalanced scenario
4、python generate_mnist.py noniid - dir # for practical noniid and unbalanced scenario
“balance” 通常表示在训练过程中平衡各个参与方(如客户端)的贡献或资源分配。这可以包括确保每个参与方有足够的训练样本、计算资源或者对模型更新的贡献,以实现公平性和效率性。
联邦学习的不平衡场景可能包括以下情况: 1. 数据分布不均:参与方(如客户端)拥有的数据量差异很大,有些参与方拥有的样本数量非常少,而有些参与方拥有的样本数量非常多。 2. 计算资源不均:参与方的计算能力不同,有些参与方的设备性能较低,而有些参与方的设备性能较高。 3. 数据标签不均:在分类任务中,不同类别的样本数量差异很大,导致一些类别的数据在训练过程中被较少地考虑。 这些不平衡的场景可能会对联邦学习的模型训练和整体性能产生影响,需要采取相应的策略来解决。
1、iid and balanced scenario:将每个类(10)划分到所有客户端,将当前类对应的数据平均分给每个client(20)
2、iid and unbalanced scenario:
下载数据,将数据的训练集测试集揉在一起,然后划分到每个client,然后分为训练集和测试集。然后将划分的参数和每个client的数据情况保存到json串中。
pfl每个client都有测试集,揉和后划分之后再区分–保证客户端的训练集和测试集的分布一致,有利于pfl的准确率
|
|
运行
|
|
这是一个后台运行Python脚本的命令,使用了**nohup**命令来让命令在后台持续运行,同时将输出重定向到mnist_dataset.out文件中。**-u**选项在Python命令行中表示使用无缓冲的输出。它的作用是强制Python在标准输出和标准错误流中不进行缓冲,而是立即输出到终端。这对于实时查看脚本的输出或日志很有用,尤其是在脚本需要长时间运行或需要实时监控输出时。
|
|
client处理
learning_rate_decay:收敛性分析的时候要求学习率必须衰减,不衰减的话就没办法收敛,理论上是这样,实际上不衰减也能收敛,能达到一个比较高的准确率,北大的 On the Convergence of FedAvg on Non-IID Data,blog
local epochs:每次聚合的时候本地训练次数
每个本地 epoch 内执行多通常情况下,在每个本地 epoch 中,模型会根据本地训练数据进行一次参数更新,然后进行一次模型评估。然而,当采用多个更新步骤时,模型将在同一本地 epoch 内执行多次参数更新,而不是仅执行一次。这种方法可能会提高模型的收敛速度,特别是在使用大型模型和数据集进行训练时。然而,需要注意的是,多次更新步骤可能会增加过拟合的风险,因此需要仔细权衡。个参数更新步骤。
join_ratio:客户端每轮参加的比例,用于衡量client dift的程度
eval_gap:几轮评估test一次模型
copy.deepcopy是用于创建对象的深度拷贝,这意味着它会递归地复制对象及其包含的所有对象,而不仅仅是复制对象本身。这样做可以确保self.model是args.model的完整和独立的副本,而不是对原始对象的引用。
nn.BatchNorm2d批标准化被用于加速神经网络的训练,并且有助于处理梯度消失/爆炸问题。用于在卷积神经网络的卷积层后应用批标准化。它通过规范化每个输入通道的输出,然后应用缩放和偏移,以使模型更容易训练并提高泛化能力。在使用深度学习框架构建卷积神经网络时,批标准化通常被认为是一种标准的正则化技术,并且已被证明在许多情况下能够提高模型的性能和训练速度。
准确率和AUC是两个不同的指标,用于评估分类模型的性能,它们分别从整体准确性和类别排序能力的角度来衡量模型的表现。ROC 曲线下面积(ROC AUC)是一种用于衡量分类模型性能的指标,它表示分类模型在不同阈值下真正例率(True Positive Rate)与假正例率(False Positive Rate)之间的权衡。ROC 曲线是以真正例率为纵轴,假正例率为横轴所绘制的曲线,ROC AUC 则是 ROC 曲线下方的面积,取值范围在 0 到 1 之间。ROC AUC 值越接近 1,表示模型性能越好;越接近 0.5,表示模型性能越一般;小于 0.5,则表示模型性能不如随机猜测。ROC 曲线和 ROC AUC 可以帮助我们评估分类模型在不同阈值下的整体性能和稳定性。
AUC(Area Under the Curve)和准确率是两种不同的性能评估指标:
- AUC(Area Under the Curve):用于衡量分类模型在不同阈值下真正例率(True Positive Rate)与假正例率(False Positive Rate)之间的权衡。ROC 曲线下面积(ROC AUC)是对整个 ROC 曲线的一个总体性能指标,表示分类模型对正负样本的排序能力,范围在 0 到 1 之间。
- 准确率(Accuracy):表示模型在所有预测样本中正确分类的比例,是最常见的分类模型性能指标之一。但准确率不能很好地处理样本不均衡的情况,当正负样本比例严重失衡时,准确率并不是一个很好的评价指标。
总的来说,AUC 是评估分类模型排序能力的指标,而准确率是评估模型分类能力的指标。 AUC 更适用于样本不均衡的情况,而准确率则更适用于样本均衡的情况。
- Epoch(周期) 是指整个训练数据集被送入神经网络进行了一次正向传播和反向传播的过程。一个 epoch 表示神经网络已经学习完整个训练数据集的过程。
- Batch(批次) 是指将整个训练数据集分成若干批次,每个批次包含若干个样本。在每个批次中,模型根据批次内的样本进行一次正向传播和反向传播,然后更新参数。
- 在使用时,可以将整个训练数据集划分为多个批次,每个批次包含固定数量的样本。在每个 epoch 中,神经网络会依次处理每个批次的数据,并进行参数更新。这样可以加速训练过程,减少内存占用,并且有助于模型的收敛。
|
|
|
|
client端先通过DataLoader分好batch,用batch的每个样本做梯度下降
clientavg.py
一个epoch把所有训练集跑一遍,一个batch是一个batchsize的数据
client.train()
|
|
server处理
main.py
初始化超参数,生成模型和选择算法,使用 FedAvg 类来执行 FedAvg 算法,设置client(数据集和实例化client),server.train()服务器端训练,计算测试结果
for i in range(args.prev, args.times):# (0,1)–实验运行的次数,打印信息用的,并不是模型聚合的次数
|
|
|
|
serveravg.py
server.train():
for i in range(self.global_rounds+1)#2000+1–模型聚合的次数2000次
下发全局模型(server->client),评估全局模型(acc,auc,loss),每个client进行训练(client.train()),接收client模型,聚合模型,保存结果,保存全局模型
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Installing collected packages: torch, opacus Attempting uninstall: torch Found existing installation: torch 1.10.1+cu113 Uninstalling torch-1.10.1+cu113: Successfully uninstalled torch-1.10.1+cu113 ERROR: pip’s dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
重新安装了torch 1.10.1+cu113
凸优化?
“Convex"是一个几何和数学术语,用来描述凸形或凸函数。在数学中,一个集合被称为凸集,如果集合中包含的任意两点之间的线段仍然在该集合内部。凸函数则是一种特殊的函数,其图像上的任意两点之间的线段位于函数图像的上方。
在优化和凸优化中,凸集和凸函数具有重要的性质,例如任意局部最小值都是全局最小值等。因此,凸集和凸函数在数学建模和优化问题中具有重要的作用。
“Non-convex"是指非凸的意思。在数学中,非凸通常用来描述不满足凸性质的集合或函数。对于一个集合来说,如果存在集合内的两点,连接这两点的线段不完全位于集合内部,则该集合是非凸的。对于一个函数来说,如果函数图像上的某一部分不满足凸性质,那么该函数就是非凸的。
在优化问题中,非凸函数通常具有多个局部最小值,使得寻找全局最小值变得更加困难。非凸问题的优化通常比凸问题更具挑战性,因为非凸函数的性质更为复杂。
MLR(多元线性回归)是凸函数,因为其损失函数是平方损失,平方损失函数是凸函数。
CNN(卷积神经网络)通常是非凸函数,因为它们的损失函数通常是非凸的,例如交叉熵损失函数。交叉熵损失函数在一般情况下是非凸的,因此导致了 CNN 通常是非凸函数。
需要注意的是,在特定情况下,CNN 的一些部分可能是凸函数,但整个网络通常是非凸的。
交叉熵损失:对于 Logit模型来说,交叉熵损失函数是凸的,因为这个函数是对数和 exp 函数的一个凸组合,这个函数是凸的。这种凸性允许使用基于梯度的方法进行有效的优化。然而,在神经网络环境中,由于交叉熵损失函数由于多层和激活函数引入的非线性而不能保证是凸的。神经网络中权值和偏差的复杂相互作用导致损失函数通常是非凸的,使得优化更具挑战性。因此,神经网络训练通常涉及使用基于梯度的优化算法,可以处理非凸函数,如随机梯度下降及其变体。
梯度下降的学习率是指在每次迭代中,沿着梯度方向更新参数时所乘以的步长大小。学习率的选择会影响算法的收敛速度和最终的收敛效果。过大的学习率可能导致震荡甚至发散,而过小的学习率则会导致收敛速度过慢。因此,选择合适的学习率对于梯度下降算法的有效性至关重要。
梯度下降可能会遇到以下问题:
- 局部最优解:可能陷入局部最优解而无法找到全局最优解。
- 学习率选择困难:选择不合适的学习率可能导致收敛缓慢或发散。
- 高维度问题:在高维空间中,梯度下降的收敛可能变得困难,需要更复杂的优化算法来解决。
- 鞍点问题:在鞍点处梯度接近零,使得优化过程变得困难。
针对这些问题,有许多改进的优化算法,如随机梯度下降、动量法、自适应学习率方法等。
在深度学习中,梯度下降不当可能导致以下问题:
- 收敛缓慢或不稳定:选择不合适的学习率或优化算法可能导致训练过程收敛缓慢或不稳定。
- 陷入局部最优解:梯度下降可能使模型陷入局部最优解,而无法达到全局最优解。
- 梯度消失或爆炸:在深层网络中,梯度下降不当可能导致梯度消失或梯度爆炸,使得网络难以训练。
- 过拟合:梯度下降过程中的参数更新可能导致模型过度拟合训练数据,导致泛化性能下降。
为了解决这些问题,深度学习中常用的优化算法包括随机梯度下降(SGD)、动量法、Adam优化器等,它们通常能够更稳定地训练深度神经网络
过拟合是指模型在训练数据上表现很好,但在测试数据上表现不佳的情况。过拟合通常是由以下原因导致的:
- 模型复杂度过高:模型过于复杂,能够很好地拟合训练数据的细节和噪声,但泛化能力较差。
- 训练数据不足:训练数据量太少,模型无法从有限的数据中学习到数据的真实分布,容易记住训练集的特定样本而无法泛化到新数据。
- 特征选择不当:选择的特征过多或过少,或者特征工程不合适,都可能导致模型过拟合。
- 噪声干扰:数据中的噪声干扰使得模型学习到了数据的随机变化而非真实的模式。
为了缓解过拟合问题,可以采取的方法包括增加训练数据、正则化、特征选择、交叉验证等。
收敛性分析是指对迭代算法在解决特定问题时的收敛性质进行分析和研究的过程。在数值优化、机器学习等领域中,收敛性分析通常用于评估迭代算法在何种条件下能够收敛到期望的解,或者收敛到问题的某种性质(如局部最优解)。
收敛性分析通常包括以下内容:
- 收敛准则:确定算法收敛的准则,例如迭代序列是否收敛到某个极限、误差是否趋于零等。
- 收敛速度:分析算法的收敛速度,即迭代序列收敛到目标解的速度有多快。
- 收敛性质:研究算法收敛到的解的性质,如局部最优解、全局最优解等。
通过收敛性分析,可以评估算法在实际问题中的表现,并为选择合适的算法、调整参数提供指导。
在CNN中,梯度下降是通过反向传播算法来计算的。
- 前向传播:首先进行前向传播,通过输入数据,计算损失函数,并沿着网络逐层计算每一层的输出。
- 反向传播:然后进行反向传播,利用链式法则计算损失函数对每一层权重参数的梯度。
- 梯度下降更新:最后使用计算得到的梯度,按照梯度下降的更新规则,对每一层的权重参数进行更新。w = w - learning_rate * gradient
这样,通过反向传播算法,CNN可以高效地计算梯度并更新网络参数,从而实现模型的训练和优化。
知乎答主LEON分享了他的并行式FL工作,可以大大增加FL的运算速度 知乎主页如下:https://www.zhihu.com/people/leon-6-17-37 代码如下:https://github.com/LEON-gittech/PFLlib.git
FedALA -AAAI2023
paper-张剑清 上交
本文:添加了一个微调的ALA模块进行元素级别的聚合(ALA只修改局部模型初始化的方法)->模型能够适应客户端的目标
全局模型较低层包含了很多的信息,因此在对局部模型进行初始化的时候设置一个超参数p,在较高层使用上述的ALA方法进行初始化,而在下面的层直接将全局模型的参数复制过来。
W矩阵式每个客户端自己的一个需要学习的超参数,当在第二轮W收敛之后的学习过程中W几乎保持不变,因此FedALA在之后训练过程中”复用“它。p也是超参数,但是没有对p的学习方法进行说明。
超参数分析:
s:客户端用来ala初始化的数据占比。实验表明s更大能够取得更好的测试准确率,然而s过大会增加计算开销,设置s为80
p:实验表明减少p,ala中需要学习的参数减少了,并且ala的准确率下降并不明显,设为1
结果分析:效果好
计算开销:用时与fedavg类似,但fedala只用了额外的0.34min实现了极大的提升
通信开销:相似
–
ALA 模块通过以下方式自适应地聚合全局模型和本地模型,以应对不同的数据分布和模型结构:
- 逐元素聚合:ALA 模块逐元素地聚合全局模型和本地模型,以适应每个客户端的局部目标。这样可以更好地捕捉全局模型中有利于改进局部模型的信息。
- 局部初始化:在每次迭代中,ALA 模块在训练之前用自适应地聚合的全局模型和本地模型来初始化局部模型。这有助于提高局部模型的质量,从而提高全局模型的性能。
- 分层聚合:ALA 模块允许用户通过设置超参数 p 来控制聚合范围,将 ALA 应用于模型的高层,而在较低层次上保留全局模型的信息。这样可以在降低计算开销的同时,仍然捕捉到有用的一般信息。
- 适用性:由于 ALA 模块仅修改 FL 中的局部初始化过程,因此它可以应用于大多数现有的 FL 方法,以提高它们的性能,而无需修改其他学习过程。这使得 ALA 可以广泛应用于不同的数据分布和模型结构。
–
但由于客户机之间数据不可见,数据的统计异质性(数据非独立同分布(non-IID)和数据量不平衡现象)便成了FL 的巨大挑战之一。数据的统计异质性使得传统联邦学习方法(如FedAvg等)很难通过FL过程训练得到适用于每个客户机的单一全局模型。
与寻求高质量全局模型的传统FL不同,pFL方法的目标是借助联邦学习的协同计算能力为每个客户机训练适用于自身的个性化模型。现有的在服务器上聚合模型的pFL研究可以分为以下三类:
-
(1)学习单个全局模型并对其进行微调的方法,包括Per-FedAvg和FedRep;
per-fedavg(联邦元学习):客户端根据全局模型初始化本身,然后在本地选择一小批数据计算损失的梯度,然后得到本地的元函数,再选取一小批的数据对元函数进行求导,最后本地模型更新以及上传模型
-
(2)学习额外个性化模型的方法,包括pFedMe和Ditto;
pfedme:额外的个性化模型即 moreau envelopes
-
(3)通过个性化聚合(或本地聚合)学习本地模型的方法,包括FedAMP、FedPHP、FedFomo、APPLE和PartialFed。
fedfomo:在上传本地的模型到服务器后,服务器会记录各个模型上传的参数,在本地客户端从服务器下载模型时,首先服务器会决定将哪些模型发送给哪些客户端(使用到关联矩阵),接着本地客户端根据下载的其他模型以及自己当前的模型在验证集上的损失来计算其他模型更新的权重,最后对本地模型聚合;使用差分隐私的方法对存在的风险归并
类别(1)和(2)中的pFL方法将全局模型中的所有信息用于本地初始化(指在每次迭代的局部训练之前初始化局部模型)。然而,在全局模型中,只有提高本地模型质量的信息(符合本地训练目标的客户机所需信息)才对客户机有益。全局模型的泛化能力较差是因为其中同时存在对于单一客户机来说需要和不需要的信息。
类别(3)中的pFL方法,通过个性化聚合捕获全局模型中每个客户机所需的信息。但是,类别(3)中的pFL方法依旧存在(a)没有考虑客户机本地训练目标(如FedAMP和FedPHP)、(b)计算代价和通讯代价较高(如FedFomo和APPLE)、(c)隐私泄露(如FedFomo和APPLE)和(d)个性化聚合与本地训练目标不匹配(如PartialFed)等问题。此外,由于这些方法对FL过程做了大量修改,它们使用的个性化聚合方法并不能被直接用于大多数现有FL方法。
为了从全局模型中精确地捕获客户机所需信息,且相比于FedAvg不增加每一轮迭代中的通讯代价,作者提出了一种用于联邦学习的自适应本地聚合方法(FedALA)。如图1所示,FedALA在每次本地训练之前,通过自适应本地聚合(ALA)模块将全局模型与本地模型进行聚合的方式,捕获全局模型中的所需信息。由于FedALA相比于FedAvg仅使用ALA修改了每一轮迭代中的本地模型初始化过程,而没有改动其他FL过程,因此ALA可被直接应用于大多数现有的其他FL方法,以提升它们的个性化表现。
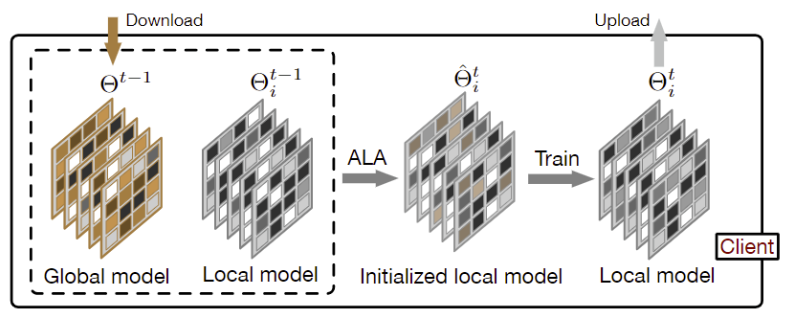
图1:客户端i第t轮,从服务器下载全局模型,通过ALA模块将全局模型与旧的局部模型局部聚合,进行局部初始化,训练局部模型,最后将训练好的局部模型上传到服务器。
自适应本地聚合(ALA)过程
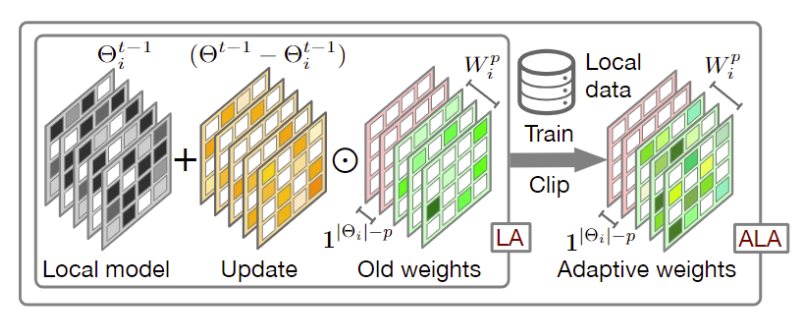
图2:ALA的学习过程。LA代表“本地聚合”。这里,我们考虑一个五层模型,setp = 3。颜色越浅,值越大。
相比于传统联邦学习中直接将下载的全局模型覆盖本地模型得到本地初始化模型的方式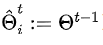 ,FedALA通过
,FedALA通过为每个参数学习本地聚合权重,进行自适应本地聚合,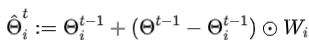 。
。
作者通过逐元素权重剪枝方法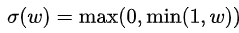 实现正则化,并将W中的值限制在[0,1]中。
实现正则化,并将W中的值限制在[0,1]中。
Hadamard乘积指的是对应位置上的元素相乘。在神经网络中,Hadamard乘积通常用于执行元素级别的乘法操作,例如两个具有相同维度的矩阵或向量进行元素级别的乘法运算。“element-wise aggregate” 是一个术语,指的是对每个元素进行独立的聚合操作。在神经网络中,这通常指的是对两个具有相同维度的张量或矩阵进行逐元素的聚合操作,例如逐元素相加、相乘等。
因为深度神经网络(DNN)的较低层网络相比于较高层倾向于学习相对更通用的信息,而通用信息是各个本地模型所需信息,所以全局模型中较低层网络中的大部分信息与本地模型中较低层网络所需信息一致。为了降低学习本地聚合权重所需的计算代价,作者引入一个超参数p来控制ALA的作用范围,使得全局模型中较低层网络参数直接覆盖本地模型中的较低层网络,而只在较高层启用ALA。
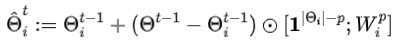
其中,|Θi|表示Θi中的神经网络层数(或神经网络块数),[;]中的前者与Θi的低层网络形状一致,后者与Θi中剩下的p层高层网络形状一致。
Wip 中的值全部初始化为1,且在每一轮本地初始化过程中基于旧的Wip来更新Wip。为了进一步降低计算代价,采用随机采样s%,本地训练数据的方式,在数据集Dis,t上通过基于梯度的学习方法更新Wip。n是更新wip的学习率。在学习wip的过程中,将除wip之外的其他可训练参数冻结。
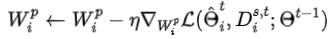
ˆΘt i:t轮clienti的模型参数
Θt−1:t-1轮的全局模型参数
分号通常表示条件,表示在给定条件下的损失函数–类似于条件分布函数
这种形式的损失函数通常用于需要考虑额外条件或先前参数状态的情况
在给定 Θt−1 的情况下,通过使用 ˆΘt i 和 Ds,t i 来计算损失函数 L 的值。
|
|
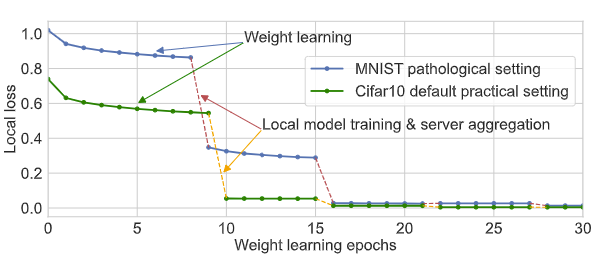
图3 在MNIST和Cifar10数据集上8号客户机的学习曲线,在每次迭代中训练至少六个 epoch 的权重。
一旦我们训练 W pi 在第二次迭代(初始阶段)中收敛,它在随后的迭代中几乎没有变化。换句话说,可以复用 W pi。我们只为 W pi 训练一个 epoch
通过选择较小的p值,在几乎不影响FedALA表现的情况下,大幅度地降低ALA中训练所需的参数。此外,如图3,一旦在第一次训练Wip 将其训练到收敛,即使在后续迭代中训练Wip,其对本地模型质量也没有很大影响。也就是说,每个客户机可以复用旧的Wip实现对其所需信息的捕获。作者采取在后续迭代中微调Wip的方式,降低计算代价。
ala分析???
把在ALA中更新W看成更新Θt i。将更新Wi视为更新Θt i意味着将权重矩阵Wi的更新视为对整体参数Θt中的子参数Θt i的更新。?
实验:
在实际(practical)数据异质环境下的Tiny-ImageNet数据集上用ResNet-18进行了对超参数s和p的对FedALA影响的研究。
对于s来说,采用越多的随机采样的本地训练数据用于ALA模块学习可以使个性化模型表现更好,但也同时增加了计算代价。在使用ALA的过程中,可以根据每个客户机的计算能力调整s的大小。从表中可以得知,即使使用极小的s(如s=5),FedALA依旧具有杰出的表现。
对于p来说,不同的p值对个性化模型的表现几乎没有影响,在计算代价方面却有着巨大的差别。这一现象也从一个侧面展示了FedRep等方法,将模型分割后保留靠近输出的神经网络层在客户机不上传的做法的有效性。使用ALA时,我们可以采用较小且合适的p值,在保证个性化模型表现能力的情况下,进一步降低计算代价。
作者在病态(pathological)数据异质环境和实际(practical)数据异质环境下,将FedALA与11个SOTA方法进行了对比和详细分析。如表2所示,数据显示FedALA在这些情况下的表现都超越了这11个SOTA方法,其中“TINY”表示在Tiny-ImageNet上使用4-layer CNN。例如,FedALA在TINY情况下比最优基线(baseline)(看表是FedRep)高了3.27%。
也在不同异质性环境和客户机总量情况下评估了FedALA的表现。如表3所示,FedALA在这些情况下依旧保持着优异的表现。
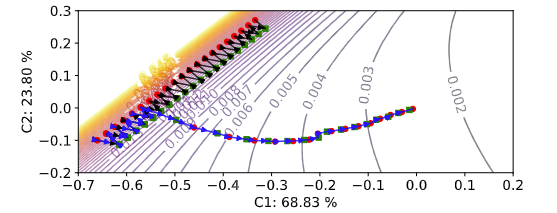
图4 病理异质环境下局部学习轨迹(从迭代140到200)和局部损失面的二维可视化
可视化在MNIST上可视化了ALA模块的加入对原本FL过程中模型训练的影响,如图4所示。不激活ALA时,模型训练轨迹与使用FedAvg一致。一旦ALA被激活,模型便可以通过全局模型中捕获的其训练所需信息径直朝着最优目标优化。
更新方向校正。局部学习轨迹(从迭代 140 到 200)和病理异质环境中 MNIST 局部损失面的 2D 可视化。绿色方圆点和红色圆圈分别表示每次迭代开始和结束时的局部模型。带有箭头的黑色和蓝色轨迹分别代表 FedAvg 和 FedALA。使用 PCA 将局部模型投影到 2D 平面。C1 和 C2 是 PCA 生成的两个主成分。
实验设置:
MNIST Cifar10/100 Tiny-ImageNet 4 层 CNN
Tiny-ImageNet 上使用 ResNet-18->tiny*
局部学习率设置为 0.005
批量大小设置为 10,将局部模型训练 epoch 数设置为 1。我们运行了 2000 次迭代的所有任务,以使所有方法都在经验上收敛。在 pFedMe 之后,我们有 20 个客户端,默认情况下设置 ρ = 1,ρ: client joining ratio。
病理异构设置:
每个客户的10/10/100个类别中抽取了MNIST/Cifar10/Cifar100的2/2/10个类别,数据样本不相交
实际的异质环境:
它由Dirichlet分布控制,表示为Dir(β)。β越小,设置就越异构。我们为默认的异构设置设置β=0.1
我们使用与pFedMe相同的评估指标,它报告了传统FL的最佳单个全局模型的测试精度和pFL的最佳局部模型的平均测试精度。为了模拟实际的pFL设置,我们在客户端评估所学习的模型。25%的局部数据形成测试数据集,其余75%的数据用于训练。我们运行所有任务五次,并报告平均值和标准偏差。
FedALA设置为s=80。
通过减小超参数p,我们可以缩小ALA的范围,而精度下降可以忽略不计,如表1所示。当p从6减少到1时,ALA中可训练参数的数量也会减少,特别是从p=2减少到p=1,因为ResNet-18中的最后一个块包含了大部分参数(He等人,2016)。尽管FedALA在这里p=2时表现最好,但我们为ResNet-18设置p=1以减少计算开销。这也表明,全局模型的较低层大多包含客户端所需的通用信息
类别(1)中的pFL方法。个性化方法表现得更好。Per-FedAvg的准确性在这些方法中是最低的,因为它只找到与所有客户的学习趋势相对应的初始共享模型,这可能无法满足单个客户的需求。在FedAvg-C/FedProx-C中微调全局模型会生成特定于客户端的本地模型,从而提高FedAvg/FedProx的准确性。然而,在像FedALA这样的本地训练中,微调只关注本地数据,而不能意识到通用信息。尽管FedRep在每次迭代时也会对头部进行微调,但它在微调时会冻结下载的表示部分,并将大部分通用信息保留在全局模型中,因此表现出色。然而,在客户端之间不共享头部的情况下,头部的通用信息丢失。
下载的表示部分通常指的是在联邦学习(或分布式学习)中,从全局模型中发送到客户端的模型参数或表示权重。这些表示部分可以包括卷积神经网络(CNN)的卷积层权重、循环神经网络(RNN)的循环权重等。即使在每次迭代时对头部进行微调,但在微调过程中冻结了下载的表示部分,这意味着在客户端进行微调时,下载的表示部分权重不会被修改。这种做法旨在保留大部分通用信息在全局模型中,从而提高模型的整体性能。然而,如果客户端之间不共享头部,这种方法可能会导致头部的通用信息丢失。具体来说,在神经网络中,头部通常指的是网络结构的顶部,包括用于特定任务的层或模块,例如分类器。这些层或模块负责将底层表示转换为最终的任务特定输出,比如对图像进行分类或对文本进行情感分析。头部的通用信息表示则指的是这些顶部层中学到的特征或模式,这些特征对于多个任务都是有用的。在联邦学习中,通过冻结表示部分并保留通用信息,可以确保在客户端的微调过程中,保留了全局模型中对多个任务都有用的通用特征表示。
尽管 pFedMe 和 Dititto 都使用近端项来学习它们额外的个性化模型,但 pFedMe 从局部模型中学习所需的信息,而 Dititto 从全局模型中学习它。因此,Ditto 在本地学习更通用的信息,它表现更好。然而,使用近端项学习个性化模型是提取所需信息的隐式方法。
使用基于规则的方法聚合模型是无目标的,无法捕捉全局模型中所需的信息,因此 FedPHP 的性能比 FedRep 和 Ditto 差。FedAMP、FedFomo 和 APPLE 中的模型级个性化聚合以及PartialFed 中的层级和二进制选择不精确,这可能会在全局模型中引入不希望的信息到局部模型。此外,在每次迭代中为每个客户端下载多个模型对于 FedFomo 和 APPLE 提供了额外的通信成本。
在实际异构设置中,由于每个客户端的数据分布复杂,很难衡量客户端之间的相似性。因此,FedAMP 不能通过注意力引导函数精确地为局部模型分配重要性,以生成具有个性化聚合的聚合模型。在下载全局模型/表示后,Ditto 和 FedRep 可以从中捕获通用信息,而不是测量局部模型之间的相似性。这样,在大多数任务中,它们都取得了优异的性能。可训练权重比近似权重信息量更大,因此 APPLE 的性能优于 FedFomo。
尽管 FedPHP 在 TINY 上表现良好,但标准偏差相对较高。由于 FedALA 可以通过 ALA 适应不断变化的环境,因此在实际设置中仍然优于所有基线。如果我们在不适应的情况下重用初始阶段学习到的聚合权重,则 TINY 的准确度下降到 33.81%。由于 ALA 的细粒度特征,它仍然优于 Per-FedAvg、pFedMe、Ditto、FedAMP 和 FedFomo。
code
以 Dir(0.1)为例,在默认的异构设置中上传 mnist 数据集–practical,论文中无对应
|
|
ALA的使用
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
病态(pathological)数据异质环境pat
每个客户机上的数据只包含特定数量的标签
注意实验参数的设置
|
|
|
|
|
|
FedCP -KDD2023
通过条件策略分离个性化联邦学习的特征信息、
大多数现有的 pFL 方法将全局模型视为存储全局信息的容器,并使用全局模型中的参数丰富个性化模型。然而,它们只关注客户端级别的模型参数,即全局/个性化模型来利用全局/个性化信息。具体来说,基于元学习的方法(如Per-FedAvg[8])只微调全局模型参数以适应本地数据,而正则化方法(如pFedMe[42]、FedAMP[15]和Ditto[24])只在局部训练过程中正则化模型参数。尽管基于个性化头的方法(例如 FedPer [2]、FedRep [6] 和 FedRoD [4])明确地将主干拆分为全局部分(特征提取器)和个性化部分(头),但它们仍然专注于利用模型参数中的全局和局部信息,而不是信息来源:数据。
由于模型是在数据上训练的,因此模型参数中的全局/个性化信息是从客户端数据中导出的。换句话说,客户端的异构数据包含全局信息和个性化信息。如图1所示,广泛使用的颜色,如蓝色,以及很少使用的颜色(如紫色和粉色)分别包含图像中的全局信息和个性化信息。𝑾ℎ𝑑 : 冻结的全局头,𝑾ℎ𝑑 𝑖/𝑗 : 个性化的头部。
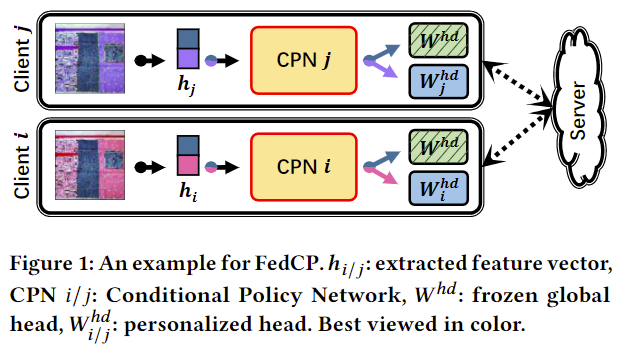
为了分别利用数据中的全局信息和个性化信息,我们提出了一种基于条件计算技术的联邦条件策略(FedCP)方法[11,35]。由于原始输入数据的维数远大于特征提取器提取的特征向量,因此为了提高效率,我们将重点放在特征向量上。由于全局信息和个性化信息在特征中的比例在样本和客户端之间不同,我们提出了一个辅助条件策略网络(CPN)来生成用于特征信息分离的样本特定策略。然后,我们分别通过全局头和个性化头在不同的路径上处理全局特征信息和个性化特征信息,如图1所示。我们将个性化信息存储在个性化头部中,并通过冻结全局头部来保留全局信息,而无需对其进行本地训练。通过端到端学习,CPN自动学习生成样本特定策略。
贡献:
- 我们是第一个考虑FL中样本特定特征信息的个性化。它比大多数现有FL方法中使用客户端级模型参数更细粒度。
- 我们提出了一种新的FedCP,它生成一个特定于样本的策略,以在每个客户端的特征中分离全局信息和个性化信息。它分别通过每个客户端上的冻结全局头和个性化头来处理这两种特征信息。
- 此外,即使某些客户端意外退出,FedCP也能保持其卓越的性能
个性化联邦
- 在基于元学习的方法中,Per-FedAvg[8]学习初始共享模型作为全局模型,满足每个客户端的学习趋势。
- 在基于正则化的方法中,pFedMe [42] 使用 Moreau 包络为每个客户端在本地学习一个额外的个性化模型。除了只为所有客户端学习一个全局模型外,FedAMP[15]还通过注意诱导函数为一个客户端生成一个服务器模型,以找到相似的客户端。在Ditto[24]中,每个客户端使用近端项在本地学习其个性化模型,以从全局模型参数中获取全局信息。、
- 在基于个性化头部的方法中,FedPer[2] 和 FedRep [6] 学习了一个全局特征提取器和一个特定于客户端的头。前者使用特征提取器在本地训练头部,而后者在每次迭代训练特征提取器之前局部微调头部直到收敛。为了弥合传统的 FL 和 pFL,FedRoD [4] 使用全局特征提取器和两个头显式学习两个预测任务。它使用平衡的 softmax (BSM) 损失 [39] 进行全局预测任务,并通过个性化头部处理个性化任务。
- 在其他 pFL 方法中,FedFomo [56] 使用来自其他客户端的个性化模型计算每个客户端聚合的特定于客户端的权重。FedPHP[27]使用移动平均局部聚合全局模型和旧的个性化模型,以保持历史个性化信息。它还通过广泛使用的最大平均差异 (MMD) 损失 [10, 37] 传递全局特征提取器中的信息。
- 上述 pFL 方法只专注于利用模型参数的全局和个性化信息,但不深入挖掘数据。
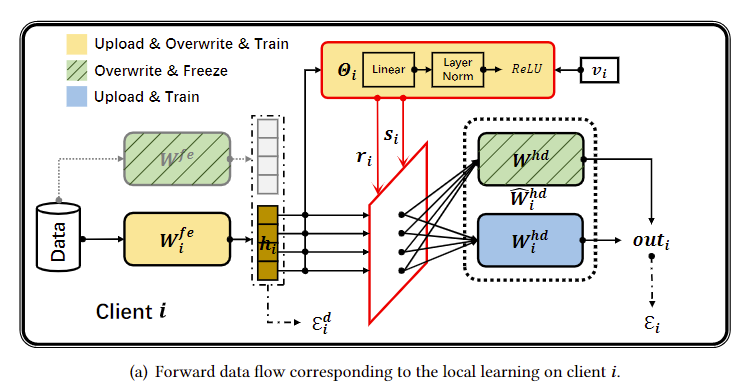
图2(a)CPN模块(红色圆角矩形):样本特征信息𝒉𝑖和客户机信息𝒗𝑖,能输出对应的策略向量(𝒓𝑖和𝒔𝑖)
菱形则表示特征信息分离操作,使用条件策略将信息𝒉𝑖通过红色菱形分离为 𝒓𝑖 ⊙ 𝒉𝑖 和𝒔𝑖 ⊙ 𝒉𝑖 。用策略向量即可提取得到全局特征信息𝒓𝑖 ⊙ 𝒉𝑖 和个性化特征信息𝒔𝑖 ⊙ 𝒉𝑖
然后交由全局头部𝑾ℎ𝑑 和个性化头部𝑾ℎ𝑑𝑖 分别处理。最后将输出合并(即加和),得到最终输出值
除了特征向量和向量𝒗𝑖 , 标准矩形和圆形矩形分别表示层和模块。
带虚线边框的圆角矩形 𝑾^ℎ𝑑𝑖 在等式(6)中
𝑾𝑓𝑒 (灰色边界)不是个性化模型的一部分,数据只在训练过程中向前流动。在训练过程中,数据在所有线中流动,但在推理过程中,数据只在实线中流动。
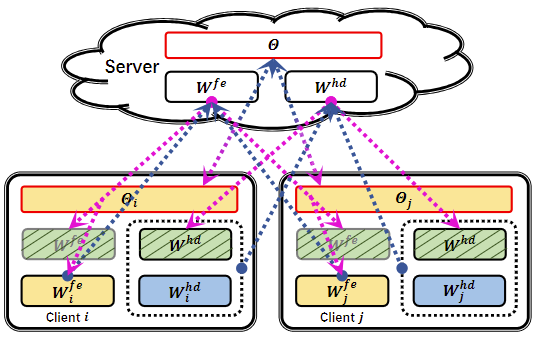
(b)分别显示了特征提取器、头部和CPN的上传和下载流.我们在实践中上传或下载它们作为服务器和每个客户端之间的联合
feature extractors是指用来提取输入数据特征的部分,通常是指卷积神经网络(CNN)中的卷积层和池化层,用来提取输入数据的特征表示。而 “the heads” 通常指的是在深度学习模型中负责执行最终任务(如分类、回归等)的部分,通常是指全连接层(也称为密集层)或输出层。 “the heads” 会接收从"feature extractors"提取的特征,并根据特定的任务进行最终的预测或输出。
条件计算
条件计算是一种根据任务相关的条件输入将动态特性引入模型的技术[11,30,35]。形式上,给定条件输入𝐶 (例如,图像/文本、模型参数矢量或其他辅助信息)和辅助模块𝐴𝑀 (·;𝜃 ), 一个信号𝑆 可以由𝑆 = 𝐴𝑀 (𝐶; 𝜃 ) 生成,并且用于干扰诸如动态路由和特征自适应之类的模型。
该论文提出了一种用于个性化联邦学习的全局和个性化特征信息分离方法FedCP,首次在数据层面实现了全局和个性化信息的分离,为分别处理这两类信息提供了可能。
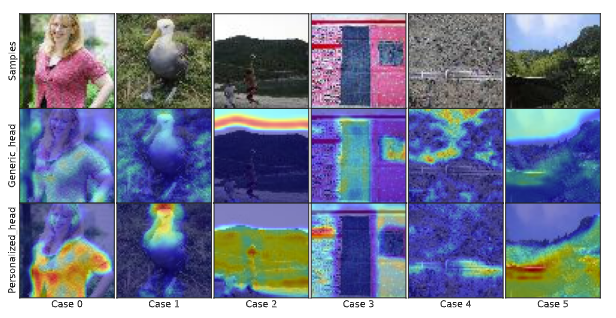
第一行为样本图片,第二行为全局特征信息,第三行为个性化特征信息。
在实际场景下,由于各个客户机上数据的异质性,每一轮上传到服务器上的客户机模型参数之间具有较大差异,聚合得到的全局模型无法在单个客户机上具有良好的表现。于是研究者们提出个性化联邦学习方法,将学习全局模型的目标,转变为通过全局模型辅助个性化本地模型训练。
在数据异质的情况下进行协同训练,既要考虑个性化(用于应对异质性)又要考虑全局性(用于协同训练)。如何把握全局和个性化这两者之间的关系,是设计个性化联邦学习方法的关键。
大多数现有的个性化联邦学习方法,仅仅从模型参数层面对全局信息和个性化信息进行分离和分别利用(见图4,Per-FedAvg,Ditto,FedRep),却忽略了模型参数中的信息是从数据中学到的这个事实。

虽然每个客户机上的数据是异质的,但异质数据也是在同一个世界中产生的,或多或少都具有一部分全局信息和另一部分个性化信息.
不同客户机上的异质数据示意图,其中蓝色代表全局信息,紫色和粉色代表个性化信息
从数据中分离和利用全局和个性化信息
由于输入空间的数据维度较高,我们便考虑对转换后的特征向量进行处理。如图6所示,在特征空间中,我们通过设计一个辅助的条件策略网络(CPN)来实现特征信息的分离;随后我们利用全局和个性化头部来分别处理分离出来的两类信息。
圆角矩形上的斜线代表“冻结”(即不参与训练、不作更新)菱形则表示特征信息分离操作。半透明的模块表示只在训练过程中参与。实现特征分离的关键在于CPN模块。
–
个性化特征分离主要通过以下方法和步骤实现:
- 使用联邦条件策略(Federated Conditional Policy,FedCP)方法:FedCP生成一个样本特定的策略,将每个客户端的特征分为全局特征信息和个性化特征信息。这两种特征信息分别由全局头和个性化头处理。
- 分离特征信息:在FedCP中,通过将策略{α, β}与特征向量x相乘,可以分别获得全局特征信息(x⊙α)和个性化特征信息(x⊙β)。由于特征之间存在连接,所以输出{α, β},而不是布尔值,即α∈(0, 1)且β∈(0, 1)。
- 生成样本特定策略:FedCP使用辅助的条件策略网络(Conditional Policy Network, CPN)生成样本特定的策略,以实现特征信息的分离。通过端到端学习,CPN将自动学习生成样本特定策略。
- 保存个性化信息:FedCP通过在每个客户端冻结全局头不进行本地训练,以保留全局信息。同时,它通过个性化头存储个性化信息。
- 实验验证:FedCP在各种数据集上的实验表现优于其他个性化联邦学习方法,证明了其有效性。
总之,通过FedCP方法和CPN模块,个性化特征分离通过为每个样本生成特定策略,实现了全局特征信息和个性化特征信息的有效分离。
论文
https://mp.weixin.qq.com/s/-gBQbo5rUD_h9Mv3hHRzeA iccv
https://mp.weixin.qq.com/s/1XWGZZa5WIsgsuL7BW1Wyg
https://mp.weixin.qq.com/s/N9h16GPTNg08VKbOYAgNuw kdd
医学个性化联邦
Model-Heterogeneous Semi-Supervised Federated Learning for Medical Image Segmentation
HPFL: hyper-network guided personalized federated learning for multi-center
Specificity-Aware Federated Graph Learning for Brain Disorder Analysis with Functional MRI
A Federated Deep Learning Method for Chronic Disease Diagnosis
FedCE:基于客户端贡献估计的公平联邦医学图像分割
FedRH: Federated Learning Based Remote Healthcare
Fine-Tuning Network in Federated Learning for Personalized Skin Diagnosis
GRACE: A Generalized and Personalized Federated Learning Method for Medical Imaging
AP2FL: Auditable Privacy-Preserving Federated Learning Framework for Electronics in Healthcare
Personalized federated learning for the detection of COVID-19
Adaptive channel-modulated personalized federated learning for magnetic resonance image reconstruction
Federated hospital: a multilevel federated learning architecture for dealing with heterogeneous data distribution in the context of smart hospitals services
Feddp: Dual personalization in federated medical image segmentation
FedSoup: Improving Generalization and Personalization in Federated Learning via Selective Model Interpolation
FedDK: Improving Cyclic Knowledge Distillation for Personalized Healthcare Federated Learning
Medical Federated Model with Mixture of Personalized and Sharing Components
Performance Analysis of Personalized Federated Learning Algorithms for Image Classification
–
FedFTN: Personalized federated learning with deep feature transformation network for multi-institutional low-count PET denoising.
Personalized Federated Learning for Medical Segmentation using Hypernetworks. iclr
GRACE: A Generalized and Personalized Federated Learning Method for Medical Imaging.
Personalized Retrogress-Resilient Federated Learning Toward Imbalanced Medical Data.
Personalized Retrogress-Resilient Framework for Real-World Medical Federated Learning.
Personalized Retrogress-Resilient Framework for Real-World Medical Federated Learning**.**
Data-Free Federated Learning blog
以下是一些近期在医疗数据分析领域的联邦学习相关论文推荐:
- FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy 该论文提出了一种名为FedCP的方法,通过条件策略分离特征信息,实现个性化联邦学习。FedCP在多个数据集和场景下的实验表现优于现有的11种先进方法。
- Practical Challenges in Differentially-Private Federated Survival Analysis of Medical Data 这篇论文探讨了在医疗数据分析中进行联邦生存分析的实际挑战,并提出了一种名为DPFed-post的方法,通过在联邦学习过程中加入后处理阶段,提高模型的收敛速度和性能。
- Open problems in medical federated learning 这篇论文讨论了医疗联邦学习中的一些开放性问题,包括隐私保护、数据异质性、模型压缩和鲁棒性等方面。
医学联邦
FedA3 I: Annotation Quality-Aware Aggregation for Federated Medical Image Segmentation Against Heterogeneous Annotation Noise
blog 无代码 客户端标注噪声 每个客户端的噪声估计是通过高斯混合模型完成的,然后以层状方式纳入模型聚合中,以增加高质量客户端的权重
FedSODA 无代码 用于组织病理学细胞核和组织分割
https://conferences.miccai.org/2022/papers/
https://conferences.miccai.org/2023/papers/
FedContrast-GPA: Heterogeneous Federated Optimization via Local Contrastive Learning and Global Process-aware Aggregation
无代码 基于中心内部和跨中心的局部原型特征的对比学习框架来增强本地模型更新过程中的特征表达一种简单但十分有效的进程感知模型融合算法,可以有效缓解系统异质导致的落后
Federated Condition Generalization on Low-dose CT Reconstruction via Cross-domain Learning跨域
Federated Uncertainty-Aware Aggregation for Fundus Diabetic Retinopathy Staging 我们开发了一种新的不确定性感知加权模块(UAW),可以根据每个客户端的不确定性评分分布动态调整模型聚合的权重。无代码
FedGrav: An Adaptive Federated Aggregation Algorithm for Multi-institutional Medical Image Segmentation通过计算局部模型之间的亲和度,探索局部模型之间的内在关联,从而提高聚合权值。模型聚合 无代码
FedIIC: Towards Robust Federated Learning for Class-Imbalanced Medical Image Classification code在特征学习中,设计了两个层次的对比学习,以便在FL中对不平衡数据提取更好的类特定特征。在分类器学习中,根据实时难度和类先验动态设置每类边际,帮助模型平等地学习类
FedSoup: Improving Generalization and Personalization in Federated Learning via Selective Model Interpolation code 我们提出了一种新的联邦模型汤方法(即模型参数的选择性插值)来优化局部和全局性能之间的权衡。具体来说,在联邦训练阶段,每个客户机通过监视局部模型和全局模型之间的内插模型的性能来维护自己的全局模型池。这使我们能够缓解过拟合并寻求平坦最小值,这可以显着提高模型的泛化性能
FeSViBS: Federated Split Learning of Vision Transformer with Block Sampling code联邦分离学习 ,并引入了一个块采样模块,该模块利用了服务器上VisionTransformer (ViT)提取的中间特征
Fine-Tuning Network in Federated Learning for Personalized Skin Diagnosis 无代码
GRACE: A Generalized and Personalized Federated Learning Method for Medical Imaging泛化和个性化联邦学习 codeGRACE在客户端的元学习框架下结合了特征对齐正则化,以纠正过度拟合的个性化梯度。同时,GRACE采用一致性增强的重加权聚合在服务器端校准上传的梯度,以实现更好的泛化。
One-shot Federated Learning on Medical Data using Knowledge Distillation with Image Synthesis and Client Model Adaptation code客户端模型自适应知识提取的医学数据一次联邦学习
Rethinking Semi-Supervised Federated Learning: How to co-train fully-labeled and fully-unlabeled client imaging data 无代码 半监督联邦学习
Scale Federated Learning for Label Set Mismatch in Medical Image Classification code 解决标签集不匹配 不同不确定程度的数据采用不同的训练策略,有效利用未标记或部分标记的数据,并在分类层采用分类自适应聚合,避免客户端缺少标签时的不准确聚合
fedsoup
|
|
表1 :FedSoup 85.71(0.37) 92.47(0.31) 72.87(1.35) 81.45(1.40)
对应result-tiny-came-4-npz.out hold0
Local Performance: Local Client-Equally Test Accurancy: 0.8777 Local Client-Equally Test AUC: 0.9438 Global Performance: Glocal Client-Equally Test Accurancy: 0.7325 Glocal Client-Equally Test AUC: 0.8042
表2 tta微调
FedSoup 72.87(1.35) 81.45(1.40) 85.36(0.86) 88.86(1.07)
没有
表3 (DG) 的其他结果–OOF
71.97 79.63
OOF Client Test Accurancy: 0.5234 OOF Client Test AUC: 0.6048
表4 no hoid on
FedSoup 89.20(0.53) 95.08(0.61) 86.44(1.12) 93.46(0.74)
对应result-tiny-came-npz.out和result-tiny-came-2-npz.out
Local Performance: Local Client-Equally Test Accurancy: 0.8964 Local Client-Equally Test AUC: 0.9482 Global Performance: Glocal Client-Equally Test Accurancy: 0.8628 Glocal Client-Equally Test AUC: 0.9311
Performance Summarizing… Local Performance: Local Client-Equally Test Accurancy: 0.9050 Local Client-Equally Test AUC: 0.9613 Global Performance: Glocal Client-Equally Test Accurancy: 0.8681 Glocal Client-Equally Test AUC: 0.9387
研究实验超参数和结果
第一项任务涉及使用Camelyon17数据集[1]对来自五个不同来源的病理学图像进行分类,每个来源都被视为客户端。病理学实验共包括4600张图像张,每张图像的分辨率为96×96。我们从原始的 Camelyon17 数据集中取一个随机子集来匹配 FL[18] 中的小数据设置。
Tiny Camelyon 17(TUPAC-2)数据集是一种用于乳腺组织分类的医学影像数据集。该数据集是从肿瘤组织切片图像中提取的,用于研究和开发计算机辅助诊断(CAD)系统和深度学习模型。这个数据集主要用于乳腺癌研究领域,可用于训练和测试医学图像分析算法,以辅助医生诊断乳腺癌。data
第二项任务涉及来自四个不同机构的视网膜眼底图像[9,26,21],每个机构都被视为客户。视网膜眼底实验共包括1264张图像,每张图像的分辨率为128×128。这两个数据集的目标是从正常图像中识别异常图像。
Retinal Fundus-RFMiD
对于每个客户端,我们将75%的数据作为训练集。为了评估我们模型的泛化能力和个性化,我们构建了局部和全局测试集。
在[28]之后,在我们的实验环境中,我们首先通过每个来源/研究所随机采样相同数量的图像来创建一个保持的全局测试集,因此其分布与任何一个客户端都不同。
每个FL客户端的本地测试数据集是来自与其训练集相同来源的剩余样本。每个客户端的本地测试集数量与保留的全局测试集数量大致相同。对于病理学数据集,由于每个受试者可以有多个样本,我们已经确保来自同一受试者的数据只出现在训练或测试集中。
为了与交叉验证设置保持一致,用于后续的域外评估,我们进行了五折留一客户端数据交叉验证,每个折叠中使用不同的随机种子进行三次重复。每次使用不同的随机种子重复三次。
这句话意思是"我们进行了一次五折留一客户数据交叉验证”。这种交叉验证方法将数据集分成五个部分,在每次验证中,将其中一个客户的数据作为验证集,其余客户的数据作为训练集,以此来评估模型的性能。
附录中提供了没有保留客户数据的重复实验的结果。对于PFL方法,我们通过平均每个个性化模型的结果来报告性能。
模型和训练超参数。我们采用ResNet-18体系结构作为主干模型。我们的方法在75%的训练阶段启动局部全局插值,与SWA的默认超参数设置一致。我们使用Adam优化器,学习率为1e−3,动量系数为0.9和0.99,并将批量大小设置为16。我们将本地训练epoch设置为1,并执行总共1000轮通信。
compute_hessian_eigenthings 是一个包含计算Hessian矩阵特征值和特征向量的函数的库。主要作用是在优化算法中用于评估损失函数的二阶导数信息。通过计算Hessian矩阵的特征值和特征向量,可以更好地理解优化空间的形状,并为优化算法提供更准确的方向信息,从而加快模型收敛速度。blog code
pip install –upgrade git+https://github.com/noahgolmant/pytorch-hessian-eigenthings.git@master
pip install –upgrade git+https://github.com/noahgolmant/pytorch-hessian-eigenthings.git@dce2e54a19963b0dfa41b93f531fb7742d46ea04
gpytorch 是一个基于 PyTorch 的高斯过程库,用于概率编程和高斯过程模型的构建。它提供了在 PyTorch 框架下构建、训练和推断高斯过程模型所需的工具和功能。
AttributeError: module ‘argparse’ has no attribute ‘BooleanOptionalAction’–python3.9以上
windows下
|
|
|
|
paper
abstract
跨孤岛fl,当面对分布变化时,当前的FL算法面临着局部和全局性能之间的权衡。具体来说,个性化FL方法有过度拟合局部数据的倾向,导致局部模型出现陡谷,抑制了其推广到分布外数据的能力。我们提出了一种新的联邦模型汤方法(即模型参数的选择性插值)来优化局部和全局性能之间的权衡。具体来说,在联邦训练阶段,每个客户机通过监视局部模型和全局模型之间的内插模型的性能来维护自己的全局模型池。这使我们能够缓解过拟合并寻求平坦最小值,这可以显着提高模型的泛化性能。视网膜和病理图像分类
introduction
最近的研究[28]发现了当前FL算法的一个重要问题,即当遇到分布变化时,局部和全局性能之间的权衡。个性化FL (PFL)技术通常通过对每个客户机的分布内(ID)数据施加更多权重来解决数据异构问题。例如,FedRep[5]在本地更新期间学习整个网络,并使部分网络免于全局同步。然而,它们有过拟合本地数据的风险[23],特别是当客户端本地数据有限时,并且对out- distribution (OOD)数据的泛化性较差。另一项工作是通过规范局部模型的更新来研究异构性问题。例如,FedProx[15]约束本地更新更接近全局模型。评估FL泛化性的一种有效方法是研究其在联合全局分布上的性能[28],这是指在⋃{Di}上测试FL模型,其中Di表示客户端i的分布4。遗憾的是,现有的研究还没有找到个性化(局部)和共识(全局)模型之间的平衡点
Dj is viewed as the OOD data for client i.
为此,我们的目标是解决 FL 中的以下两个问题:可能导致局部和全局权衡的原因是什么。以及如何实现更好的局部和全局权衡。我们发现 FL 中的过度个性化会导致对本地数据的过度拟合,并将模型捕获到损失景观的尖锐山谷中(对参数扰动高度敏感,参见第 2.2 节中的详细定义),从而限制了其泛化性。避免损失景观中尖锐山谷的有效策略是强制模型获得平坦的最小值。在集中式领域,权重插值weight interpolation已被探索为寻找平坦最小值的一种手段,因为它的解决方案更接近高性能模型的质心,这对应于更平坦的最小值 [11,3,6,24]。然而,对这些插值方法的研究在FL中被忽略了。
在此基础上,我们建议在联合训练过程中跟踪局部模型和全局模型,并执行模型插值来寻求最优平衡。我们的见解是从模型汤方法[27]中提取的,这表明具有相同初始参数的多个训练模型的平均权重可以增强模型的泛化能力。然而,原始模型汤方法需要训练具有不同超参数的大量模型,这在 FL 期间的通信方面可能非常耗时且成本高昂。鉴于 FL 中的通信成本高且无法从头开始训练,我们利用单个训练会话中不同时间点的全局模型作为使模型汤方法 [27] 适应 FL 的成分。
在本文中,我们提出了一种新的联邦模型汤方法(FedSoup),以从局部和全局模型中生成集成模型,从而实现更好的局部-全局权衡。我们将“soup”称为不同联邦模型的组合。我们提出的FedSoup包括两个关键模块。第一种是时间模型选择,旨在选择合适的模型组合成一个模型。第二个模块是联邦模型修补[10],它指的是一种微调技术,旨在增强个性化,而不影响已经令人满意的全局性能
“temporal model selection” 意味着在时间序列数据或其他时间相关数据集上进行模型选择。这可能涉及在不同的时间点上选择不同的模型或参数配置,以适应数据随时间变化的特性。这种方法有助于构建更具有适应性和泛化能力的模型,以更好地应对时间序列数据的特点。
对于第一个模块,时间模型选择,我们使用了基于局部验证性能的贪婪模型选择策略。避免将可能位于不同误差景观盆地的模型合并到本地的损失景观中(如图1所示)。因此,每个客户都拥有他们的个性化全局模型汤,由基于其本地验证集选择的历史全局模型的子集组成。
“景观"在这里指的是指代模型参数空间中的拓扑结构或形状。在机器学习领域,误差景观通常用来描述损失函数在参数空间中的形状,以及模型在该空间中移动时损失值的变化情况。
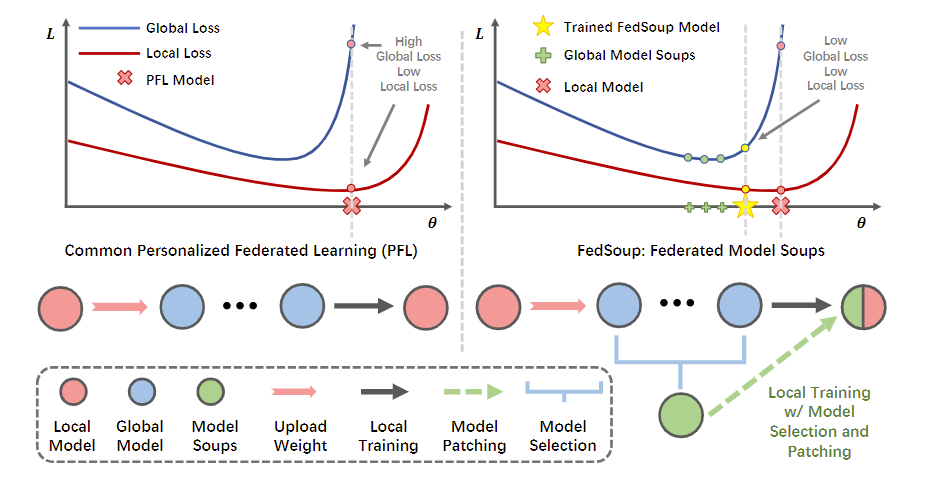
图1:PFL方法通常最小化局部损失,但存在较高的全局损失。而我们的联邦模型汤方法通过寻求平坦极小值来平衡局部和全局损失。图中的黑点表示省略号,表示其间的多轮模型上传和模型训练。与以前的pFL方法相比,我们的方法引入了全局模型选择模块和全局模型与局部模型进行插值(称为模型修补)。
“seeking flat minima” 意味着在机器学习中寻找“平坦的最小值”。在训练神经网络时,有时候希望模型收敛到一个平坦的局部最小值,而不是一个非常陡峭的局部最小值。这是因为平坦的最小值可能对噪声更具鲁棒性,有助于提高模型的泛化能力。
“local model interpolation with the global model” 意味着在机器学习中,将局部模型与全局模型进行插值。这可能涉及将局部训练的模型与全局模型进行融合或插值,以获得更具泛化能力的模型。这种方法有助于平衡全局和局部模型的性能,以获得更好的整体性能。
第二个模块,联邦模型修补,它通过将局部模型和全局模型汤插入到新的局部模型中,在局部客户端训练中引入模型修补,弥合局部域和全局域之间的差距。它促进了ID测试模型的个性化,并为OOD泛化保持了良好的全局性能。
(i)提出了一种新的FL方法,称为联邦模型流(FedSoup),通过提高平滑度和寻求平坦极小值来提高泛化和个性化。(ii)为FL设计了一种新的时间模型选择机制,该机制维护了具有时间历史全局模型的客户特定模型汤,以满足个性化要求,同时不产生额外的训练成本。(iii)在联合客户端训练中引入了一种创新的局部和全局模型之间的联合模型修补方法,以缓解局部有限数据的过拟合。
method
个性化的目的是最小化本地客户端训练集 Di 上的经验loss,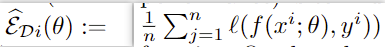
泛化(全局性能)的目标是通过所有训练客户的训练集 D 上的经验loss最小化 (ERM) 来最小化多both population损失 ED (θ) 和 ET (θ)–(定义了一组看不见的目标域 T)
我们评估了 Di 的局部测试样本的局部性能,并从联合全局分布 D := {Di}N i=1 评估测试样本的全局性能
“minimize both population loss” 意味着在机器学习中,不仅要最小化经验损失(在训练数据上的损失),还要尽量减小整体(或总体)损失。这表示模型不仅要在训练数据上表现良好,还要在整体总体上具有良好的泛化能力。
泛化和平坦最小值
在实践中,深度神经网络中的ERM,即arg-minθõED(θ),可以产生多个解决方案,这些解决方案提供可比较的训练损失,但可推广性水平截然不同[3]。然而,如果没有适当的正则化,模型容易对训练数据进行过度拟合,并且训练模型将陷入损失面的陡峭山谷,这是不太可推广的[4]。ERM失败的一个常见原因是数据分布存在变化,这可能会导致损失景观的变化。如图 1 所示,优化的最小值越尖锐,它对损失景观的变化就越敏感。这导致泛化误差增加。在跨设备 FL 中,每个客户端可能会过度拟合其本地训练数据,导致全局性能较差。这是由于分布偏移问题,它在局部模型[23]中造成了相互冲突的目标。因此,当局部模型收敛到一个尖锐的最小值时,模型的个性化程度(局部性能)越高,泛化能力较差(全局性能)的可能性就越大。
fedsoup
Temporal Model Selection
随机加权平均 (SWA) 是一种更简洁和有效的方法,通过平均权重隐式偏爱平坦最小值。SWA 算法的动机是观察到 SGD 通常在权重空间中找到高性能模型,但很少达到最优集的中心点。通过对迭代上的参数值进行平均,SWA 算法将解移动到更接近该点空间的质心。
引入了一种称为模型汤[27]的选择性加权平均方法来增强微调模型的泛化能力。我们通过利用在FL训练的一次传递中不同时间点训练的全局模型,使这个想法适应新的方法。我们提出了一种模型选择策略,其中每个客户端利用其本地验证集的性能作为监控指标
Federated Model Patching
根据之前关于损失景观的分析,由于不同FL客户端的域差异,不同FL客户端之间存在损失景观偏移。因此,简单地集成全局模型会损害模型的个性化。我们在 FL 的客户端局部训练期间引入了模型修补 [10](即局部和全局模型插值),旨在提高模型个性化并保持良好的全局性能。具体来说,模型修补方法迫使本地客户端不会严重扭曲全局模型,并在局部和全局之间寻求低损失插值模型,鼓励局部和全局模型位于同一个盆地,没有较大的线性连通性障碍。[19]。我们称这个模块为联邦模型修补。
我们提出的 FedSoup 算法只需要一个仔细调整的超参数,即插值开始 epoch。为了减轻当起始 epoch 太晚并且当起始 epoch 太早时防止潜在性能下降的风险,我们将默认插值起始 epoch 设置为总训练时期的 75%,与 SWA 的默认设置对齐。此外,值得一提的是,我们提出的 FedSoup 框架中修改后的模型汤和模型修补模块是相互依赖的。模型修补是一种基于我们修改后的模型汤算法的技术,提供了丰富的模型来探索更平坦的最小值并提高性能。
Experiments
|
|
|
|
|
|
|
|
|
|
|
|
|
|
out-of-distribution (OOD):在不同客户端数据上进行测试,未知分布。
out-of-federated performance(oof):指的是在联邦学习环境之外的性能表现。这个术语通常用于描述模型在非联邦学习设置下的性能,例如在集中式学习或单个数据源的情况下的性能表现。
|
|
|
|
|
|
fedsoup
选择性模型混合(Selective Model Interpolation):FedSoup引入了一种新的模型混合策略,它允许在全局模型和个性化模型之间进行选择性的插值。这种方法不仅考虑了全局模型的泛化能力,还考虑了个性化模型对本地数据的适应性。- 个性化和泛化的平衡:FedSoup通过
调整全局模型和个性化模型的插值比例,动态地平衡了模型的泛化和个性化。这种平衡使得模型既能捕捉到跨用户的共同特征,又能适应每个用户的特定数据分布。 自适应插值权重:FedSoup算法中的选择性模型混合不是静态的,而是基于每个用户的数据和模型性能自适应地调整插值权重。这种自适应机制使得算法能够根据不同用户的数据多样性和模型性能需求灵活调整模型结构。- 降低通信开销:在联邦学习中,模型参数的同步是一个通信密集型的过程。FedSoup通过减少需要传输的参数数量,从而降低了通信开销。这是通过只传输那些在全局模型和个性化模型插值中起到关键作用的参数来实现的。
- 实验验证:论文中对FedSoup算法进行了广泛的实验验证,证明了它在多个数据集和不同的联邦学习设置下,相较于现有方法,能够显著提高模型的泛化和个性化性能。
总之,FedSoup算法通过选择性模型混合和自适应插值权重,提供了一种有效的机制来同时增强联邦学习中的泛化和个性化性能,并且降低了通信开销。
–
FedSoup算法在提升模型泛化能力方面的创新体现在以下几个方面:
- 全局与个性化模型的融合:FedSoup算法通过结合全局模型和本地个性化模型来提升泛化能力。
全局模型能够捕捉到所有用户数据的共同特征,从而提高模型对于未见数据的泛化能力。个性化模型则针对每个用户的本地数据进行优化,提高模型对特定用户数据的适应性。 - 自适应插值权重:算法根据每个用户的数据特性和模型性能动态调整全局模型和个性化模型的插值权重。这种自适应机制使得算法能够在保证模型个性化的同时,确保模型在全局范围内的泛化性能。
- 模型更新的选择性同步:在联邦学习的过程中,
并不是每次都需要将整个模型更新同步给所有用户。FedSoup算法通过选择性地同步模型更新,减少了通信开销,并可能只同步那些对提升泛化能力最为关键的部分,这样可以更加高效地利用带宽和计算资源,从而间接提升模型的泛化能力。 - 避免过度拟合:由于联邦学习的数据分散在多个用户手中,局部模型可能会过度拟合到本地数据,从而降低泛化能力。FedSoup通过
全局模型的引导,帮助局部模型避免这种过度拟合现象,增强模型对新数据的泛化能力。 - 实验验证:论文中提供了详细的实验结果,展示了FedSoup算法在不同的数据集和联邦学习场景下,相较于传统的联邦学习方法,在提升模型泛化能力方面的优势。
综上所述,FedSoup算法通过全局和个性化模型的融合、自适应插值权重、选择性模型同步、避免过度拟合以及实验验证等创新手段,有效地提升了模型的泛化能力。
插值权重,在插值方法的上下文中,是指每个已知数据点对未知位置或值的影响权重。这些权重通常是根据已知数据点之间的距离或其他相关性来计算的。简而言之,插值权重用于确定在插值过程中,各个已知数据点应如何贡献于未知点的估计值。通过适当地调整这些权重,可以更准确地逼近未知点的真实值。
–
在论文《FedSoup: Improving Generalization and Personalization in Federated Learning via Selective Model Interpolation》中,选择性模型混合(Selective Model Interpolation)是通过以下步骤实现的:—类似于fedala
- 模型训练:在联邦学习的框架中,每个客户端都会根据自己的本地数据训练一个个性化模型。同时,所有客户端还会训练一个全局模型,该模型旨在捕捉所有客户端数据的共同特征。
- 模型融合策略:在模型训练完成后,
FedSoup采用一种融合策略,该策略基于每个客户端的个性化模型和全局模型之间的相似性来选择性地进行模型混合。具体来说,FedSoup计算每个个性化模型与其对应客户端的全局模型的差异度量(例如,KL散度或余弦相似性)。 - 插值系数计算:接着,FedSoup为每个客户端计算一个
插值系数,该系数表示个性化模型在最终模型中的权重。插值系数的计算基于差异度量和一个预设的温度参数(temperature parameter),后者用于控制插值的平滑程度。 - 模型更新:最后,每个客户端根据计算出的插值系数更新自己的模型,即将全局模型与个性化模型按照插值系数融合成一个新的模型。这个新模型既包含了全局模型的泛化能力,又保留了个性化模型对本地数据的适应性。
通过这种选择性模型混合,FedSoup旨在实现更好的模型泛化和个性化。模型泛化指的是模型对新数据的适用性,而个性化则是模型对特定用户数据的适应性。通过这种方式,FedSoup旨在平衡这两个目标,使得模型既能够泛化到新用户,也能够很好地服务于每个参与联邦学习的客户端。
在《FedSoup: Improving Generalization and Personalization in Federated Learning via Selective Model Interpolation》论文中,通过全局模型引导局部模型的方式来避免过度拟合主要体现在模型融合策略上。具体而言,FedSoup算法采用了一种选择性模型混合(selective model interpolation)的策略,该策略结合了全局模型和局部模型的优点,以提高模型在联邦学习环境中的泛化能力和个性化能力。
在这个过程中,每个客户端都会根据自己的本地数据训练一个个性化模型,同时也会从服务器那里接收到一个全局模型。然后,客户端利用全局模型来引导本地模型的训练。这种引导通常是通过在训练过程中将全局模型的参数作为一种先验知识加入到本地模型的训练中,或者在训练结束后,通过模型混合的方式来实现的。
在模型混合阶段,客户端会计算本地模型和全局模型之间的差异,并根据这个差异以及其他因素(比如模型性能、数据分布等)来决定如何混合这两个模型。如果本地模型在本地数据上过度拟合,那么它可能会与全局模型有较大的差异。此时,通过选择性地混合全局模型和本地模型,可以帮助本地模型“解拟合”,即减少模型对本地数据的过拟合现象,从而提高模型对新数据的泛化能力。
通过这种方式,FedSoup算法能够在保持模型个性化的同时,确保模型不会仅仅适应本地数据,而是能够泛化到更广泛的数据分布上。这样的策略对于联邦学习中的模型训练尤为重要,因为联邦学习涉及多个客户端,每个客户端的数据分布可能都不尽相同,因此需要模型既要有良好的泛化能力,又要能适应不同客户端的个性化需求。
–
在论文《FedSoup: Improving Generalization and Personalization in Federated Learning via Selective Model Interpolation》中,模型更新的选择性同步是通过以下步骤实现的:
- 每个参与联邦学习的客户端在本地训练自己的个性化模型,同时也训练一个全局模型。
- 在每次联邦学习轮次结束时,客户端计算自己的个性化模型与全局模型之间的差异度量,并据此确定是否需要同步更新。
- 客户端根据差异度量和一个预设的阈值来决定
是否将模型更新发送给服务器。只有当差异超过这个阈值时,客户端才会同步其模型更新。 - 服务器收到来自不同客户端的更新后,会根据一定的策略(比如加权平均)来聚合这些更新,生成新的全局模型。
- 服务器将新的全局模型发送回所有客户端,客户端再根据自己的插值系数将新的全局模型与本地个性化模型融合,形成新的本地模型。
通过这种方式,只有当客户端的模型更新相对于全局模型有显著差异时,更新才会被同步,这样可以减少不必要的通信开销,并且使得全局模型更快地收敛到一个对所有客户端都有用的状态。同时,选择性同步也有助于保护客户端的隐私,因为它减少了需要传输的信息量。
论文《FedSoup: Improving Generalization and Personalization in Federated Learning via Selective Model Interpolation》中,判断是否需要上传模型更新的机制是基于模型间的差异性。具体来说,客户端会计算本地模型更新与全局模型更新之间的差异度量,例如使用欧氏距离或者其他相似度指标。如果差异超过某个设定的阈值,表明本地模型与全局模型存在较大差异,这时候才需要上传模型更新。
这样做的目的主要有两个:
- 减少通信成本:通过只上传那些真正有差异、能够为全局模型带来新信息的模型更新,可以减少网络带宽的使用和通信开销,特别是在大规模分布式系统中,这一点尤为重要。
- 提高模型效率:只上传重要的更新有助于加快全局模型收敛速度,因为它避免了冗余的、相似的或者不太有用的更新,从而使得全局模型能够更快地整合所有客户端的有用信息,提高整体模型的性能。
|
|
self.per_global_model_num * global_param.data.clone():这部分计算global_param的当前值与其对应权重的乘积。权重是self.per_global_model_num。last_global_model.data.clone():这部分直接使用last_global_model的当前值,没有乘以任何权重。- 将上述两部分相加,得到
global_param和last_global_model的加权和。 - 最后,这个加权和乘以一个归一化因子
1.0 / (self.per_global_model_num + 1.0),以确保更新后的last_global_model值在合理的范围内。 global_param的权重随着self.per_global_model_num的增加而增加。last_global_model的实际影响会随着self.per_global_model_num的增加而相对减小。
FedSoupALA
|
|
|
|
cifar -- client-20 gr 50
|
|
|
|
|
|
加上-eg 10
camelyon17–hold client 0
| method | local_acc | loacl_auc | global_acc | global_auc |
|---|---|---|---|---|
| FedAvg | 82.41 | 90.44 | 70.18 | 78.74 |
| FedProx | 86.34 | 92.78 | 67.42 | 77.18 |
| MOON | 85.71 | 91.98 | 70.61 | 79.27 |
| FedBN | 82.32 | 90.07 | 65.16 | 71.61 |
| FedFomo | 80.99 | 86.51 | 61.00 | 61.69 |
| FedRep | 82.50 | 89.77 | 66.87 | 72.34 |
| FedBABU | 85.18 | 92.39 | 69.56 | 77.26 |
| FedSoup | 85.71 | 92.47 | 72.87 | 81.45 |
| Fedsoup-4 | 87.68、87.90 | 94.23、94.34 | 73.31、73.18 | 80.37、80.86 |
| Fedsoup-4-tune | 87.77 | 94.38 | 73.25 | 80.42 |
| FedSoupALA本地 | 67.77、76.85 | 75.69、85.63 | 58.63、63.95 | 67.44、71.08 |
| FedSoupALA-tune | 90.54 | 95.01 | 71.82 | 78.43 |
| method | local_acc | loacl_auc | global_acc | global_auc |
|---|---|---|---|---|
| fedasoupala p2 | 88.93/89.20/89.02 | 94.48/94.90/94.88 | 73.01/73.21/72.92 | 80.21/80.38/80.20 |
| 同上_1 | 80.09/88.04/87.95 | 88.91/94.68/94.55 | 71.04/73.28/72.61 | 78.06/81.08/80.16 |
| gr20 | 83.04/84.02/89.20 | 90.31/92.56/95.45 | 66.23/65.28/71.29 | 75.01/75.88/81.18 |
| p4 | 86.52/86.16/86.96 | 93.60/93.73/93.94 | 72.05/72.32/72.52 | 78.35/78.64/78.94 |
p6 |
88.93/88.75/89.02 | 94.62/94.55/94.64 | 74.57/74.30/74.51 | 81.92/81.54/81.89 |
| p8 | 87.50/87.54/87.86 | 94.20/94.09/94.19 | 72.95/72.88/73.11 | 79.04/78.66/78.95 |
| p10 | 88.66/87.86/88.48 | 94.04/93.34/93.68 | 73.16/72.39/73.01 | 79.84/78.61/79.74 |
| p2_prun | 86.07/86.52/86.16 | 93.15/93.23/93.01 | 72.41/72.31/73.32 | 78.75/78.75/78.74 |
新的评价方式
nohup python -u main.py -data tiny_camelyon17 -m resnet -algo FedSoupALA -gr 1000 -did 0 -eg 100 -go fedsoup_debug -nc 4 -hoid 0 -lr 1e-3 -wa_alpha 0.75 -et 1 -pala 6 -s 80 > result-tiny-came-npz-ala-neweval-p6.out 2>&1; shutdown
先单独跑FedALA
nohup python -u main.py -lbs 16 -nc 4 -hoid 0 -lr 1e-3-data tiny_camelyon17 -m resnet -algo FedALA -gr 1000 -did 0 -eg 100 -et 1 -pala 6 -s 80 -go fedala > tiny_fedala.out 2>&1
nohup python -u main.py -data tiny_camelyon17 -m resnet -algo FedALA -gr 1000 -did 0 -eg 100 -go fedala -nc 4 -hoid 0 -lr 1e-3 -wa_alpha 0.75 -et 1 -pala 6 -s 80 > tiny-came-fedala-neweval-p6.out 2>&1
fedsoup
nohup python -u main.py -data tiny_camelyon17 -m resnet -algo FedSoup -gr 1000 -did 0 -eg 100 -go fedsoup_debug -nc 4 -hoid 0 -lr 1e-3 -wa_alpha 0.75 -et 1 -pala 6 -s 80 >tiny-came-npz-soup-neweval-p6.out 2>&1;
| method | local_acc | loacl_auc | global_acc | global_auc |
|---|---|---|---|---|
| fedasoupala p6 | 86.96//87.32 | 99.27/// | 71.32//71.29 | 95.78//97.58 |
| fedala p6 | 84.91//84.38 | 99.17//99.11 | 71.24//71.32 | 97.37//97.47 |
| fedsoup | 84.46//85.18 | 98.88//99.08 | 73.03/73.07/ | 97.85//97.88 |
cifar 10 -nohold
50轮次
| method | local_acc | loacl_auc | global_acc | global_auc |
|---|---|---|---|---|
| FedAvg | 28.70/90.14/91.10 | 71.77/99.03/99.19 | 38.22/20.79/21.04 | 81.09/72.88/73.11 |
| fedavg_1 | 89.63///90.90 | 98.91///99.14 | 29.74/20.73//20.93 | 72.42/72.63//73.04 |
| FedProx | 27.18/89.78/90.74 | 69.68/98.96/99.13 | 37.07/20.88/20.99 | 80.58/72.66/72.88 |
| FedProx_1 | 89.98///90.85 | 99.01///99.17 | 30.52/20.58//20.94 | 72.93/72.66//72.86 |
MOON |
91.07/91.07/92.10 | 70.10/70.10/77.00 | 20.99/20.99/23.30 | 52.97/52.97/54.69 |
| FedBN | 90.82/89.23/91.92 | 88.15/86.94/94.39 | 21.33/20.60/22.61 | 55.27/54.27/57.01 |
| FedFomo | 88.93/89.41/89.74 | 98.83/98.87/98.97 | 1/19.45/19.90 | 1/53.94/54.22 |
| FedRep | 86.59/88.51/91.09 | 98.61/98.44/99.14 | 1/19.82/22.28 | 1/54.27/56.17 |
| FedBABU | 58.46/90.92//92.46 | 88.67/98.89//99.03 | //22.03/23.51 | //62.16/64.04 |
| FedALA | 89.56///90.58 | 93.35///94.93 | /20.83//20.89 | //64.11//64.47 |
| FEDALA_1 | 89.04/90.77 | 92.58/94.80/ | 20.65/20.79/ | /64.04/64.78 |
| FedSoup | 26.31/89.65/91.35 | 57.78/66.91/64.49 | 18.58/22.18/25.86 | 53.02/53.18/53.38 |
| Fedsoupala | 88.37/91.37/92.44 | 85.29/87.80/82.10 | 21.22/21.44/23.85 | 58.35/57.33/58.35 |
| Fedsoupala_1 | 90.57/ | 86.59/92.48 | 21.66/24.09 | 56.94/57.82 |
Author kong
LastMod 2023-11-28