Java-数组
Contents
为什么需要数组
需求分析1:
需要统计某公司50个员工的工资情况,例如计算平均工资、找到最高工资等。用之前知识,首先需要声明50个变量来分别记录每位员工的工资,这样会很麻烦。因此我们可以将所有的数据全部存储到一个容器中统一管理,并使用容器进行计算。
需求分析2:
前端界面的布局item元素相同
容器的概念:
- **生活中的容器:**水杯(装水等液体),衣柜(装衣服等物品),集装箱(装货物等)。
- **程序中的容器:**将多个数据存储到一起,每个数据称为该容器的元素。
数组
-
数组(Array),是多个相同类型数据按一定顺序排列的集合,并使用一个名字命名,并通过编号的方式对这些数据进行统一管理。
-
数组中的概念
- 数组名
- 下标(或索引)-0开始
- 元素
- 数组的长度
数组的特点:
- 数组本身是
引用数据类型,而数组中的元素可以是任何数据类型,包括基本数据类型和引用数据类型。 - 创建数组对象会在内存中开辟一整块
连续的空间。占据的空间的大小,取决于数组的长度和数组中元素的类型。 - 数组中的元素在内存中是依次紧密排列的,有序的。
- 数组,一旦初始化完成,其长度就是确定的。数组的
长度一旦确定,就不能修改。 - 我们可以直接通过下标(或索引)的方式调用指定位置的元素,速度很快。
数组名中引用的是这块连续空间的首地址。
数组的分类
1、按照元素类型分:
-
基本数据类型元素的数组:每个元素位置存储基本数据类型的值
byte \ short \ int \ long ;float \ double ; char \ boolean
-
引用数据类型元素的数组:每个元素位置存储对象(本质是存储对象的首地址)
类、数组、接口、枚举、注解、记录
2、按照维度分:
- 一维数组:存储一组数据
- 二维数组:存储多组数据,相当于二维表,一行代表一组数据,只是这里的二维表每一行长度不要求一样。
一维数组
声明:
|
|
数组的声明,需要明确:
(1)数组的维度:在Java中数组的符号是[],[]表示一维,[][]表示二维。
(2)数组的元素类型:即创建的数组容器可以存储什么数据类型的数据。元素的类型可以是任意的Java的数据类型。例如:int、String、Student等。
(3)数组名:就是代表某个数组的标识符,数组名其实也是变量名,按照变量的命名规范来命名。数组名是个引用数据类型的变量,因为它代表一组数据。
(4)声明数组时不能指定其长度(数组中元素的个数)
初始化
静态初始化
- 如果数组变量的
初始化和数组元素的赋值操作同时进行,那就称为静态初始化。 - 静态初始化,本质是用静态数据(编译时已知)为数组初始化。此时数组的长度由静态数据的个数决定。
- 一维数组声明和静态初始化格式1:
- new:关键字,创建数组使用的关键字。
因为数组本身是引用数据类型,所以要用new创建数组实体。
- new:关键字,创建数组使用的关键字。
|
|
- 一维数组声明和静态初始化格式2:
|
|
动态初始化
- 数组变量的初始化和数组元素的赋值操作分开进行,即为动态初始化。
- 动态初始化中,只确定了元素的个数(即数组的长度),而元素值此时只是默认值,还并未真正赋自己期望的值。真正期望的数据需要后续单独一个一个赋值。
- [长度]:数组的长度,表示数组容器中可以最多存储多少个元素。
- 注意:数组有
定长特性,长度一旦指定,不可更改
|
|
数组的使用
数组的长度
- 数组的元素总个数,即数组的长度
- 每个数组都有一个属性length指明它的长度,例如:arr.length 指明数组arr的长度(即元素个数)
- 每个数组都具有长度,而且一旦初始化,其长度就是确定,且是不可变的。
组元素的引用
如何表示数组中的一个元素?
每一个存储到数组的元素,都会自动的拥有一个编号,从0开始,这个自动编号称为数组索引(index)或下标,可以通过数组的索引/下标访问到数组中的元素。
数组的下标范围?
为什么数组要从0开始编号,而不是1(中*支付)
数组的索引,表示了数组元素距离首地址的偏离量。因为第1个元素的地址与首地址相同,所以偏移量就是0。所以从0开始。
Java中数组的下标从[0]开始,下标范围是[0, 数组的长度-1],即[0, 数组名.length-1]
数组元素下标可以是整型常量或整型表达式。如a[3] , b[i] , c[6*i];
一维数组的遍历
|
|
数组元素的默认值
数组是引用类型,当我们使用动态初始化方式创建数组时,元素值只是默认值。例如:
|
|
整型数组元素的默认初始化值:0 浮点型数组元素的默认初始化值:0.0 字符型数组元素的默认初始化值:0 (或理解为'\u0000') boolean型数组元素的默认初始化值:false 引用数据类型数组元素的默认初始化值:null
一维数组内存分析
为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
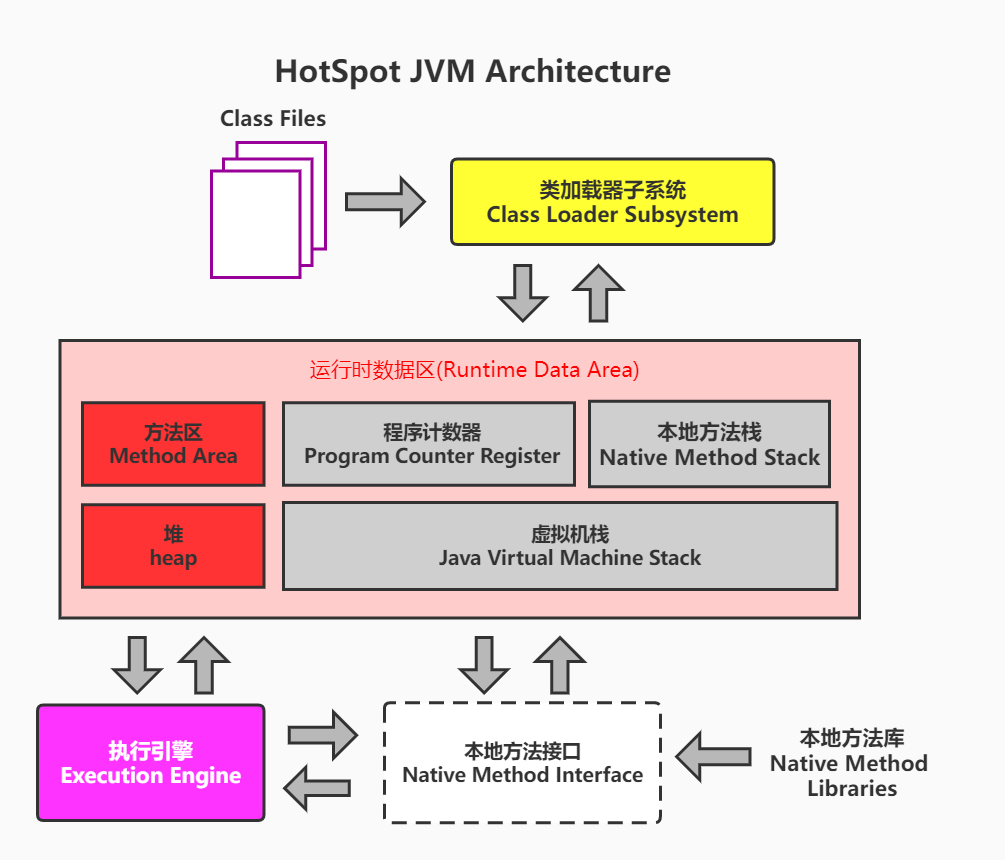
| 区域名称 | 作用 |
|---|---|
虚拟机栈 |
用于存储正在执行的每个Java方法的局部变量表等。局部变量表存放了编译期可知长度的各种基本数据类型、对象引用,方法执行完,自动释放。 |
堆内存 |
存储对象(包括数组对象),new来创建的,都存储在堆内存。 |
方法区 |
存储已被虚拟机加载的类信息、常量、(静态变量)、即时编译器编译后的代码等数据。 |
| 本地方法栈 | 当程序中调用了native的本地方法时,本地方法执行期间的内存区域 |
| 程序计数器 | 程序计数器是CPU中的寄存器,它包含每一个线程下一条要执行的指令的地址 |
将内存区域划分为5个部分:程序计数器、虚拟机栈、本地方法栈、堆、方法区
与目前数组相关的内存结构: 比如:int[] arr = new int[]{1,2,3}; 虚拟机栈:用于存放方法中声明的变量。比如:arr 堆:用于存放数组的实体(即数组中的所有元素)。比如:1,2,3
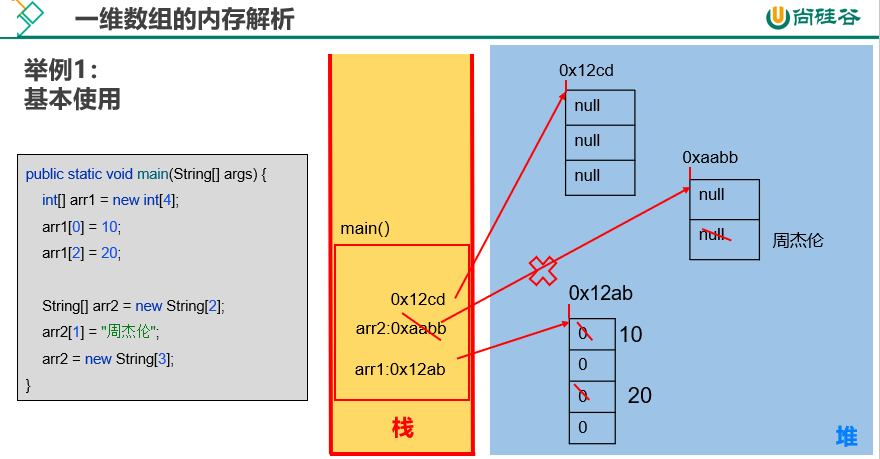
栈中保存了数组变量,标记了堆中对象的首位的虚拟地址
堆中保存了数组对象,new才会开辟新的内存空间
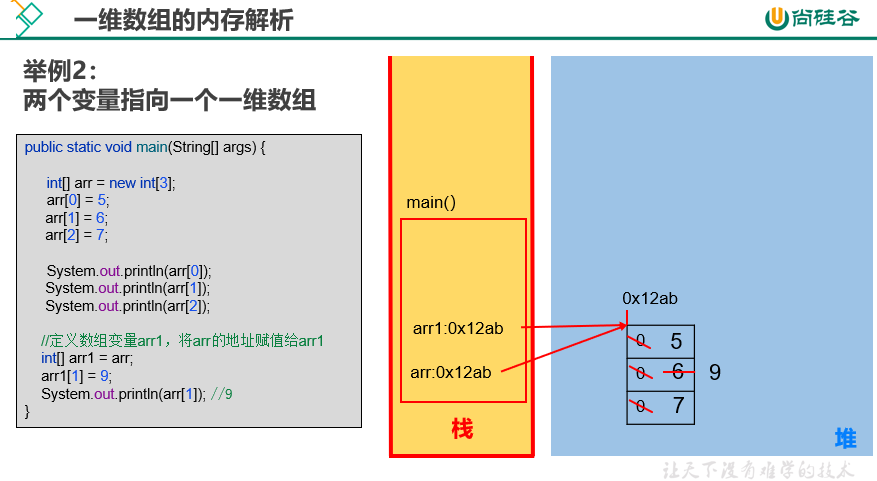
|
|
多维数组
|
|
- 对于二维数组的理解,可以看成是一维数组array1又作为另一个一维数组array2的元素而存在。
- 其实,从数组底层的运行机制来看,其实没有多维数组。
声明
|
|
初始化
静态
|
|
定义一个名称为arr的二维数组,二维数组中有三个一维数组
- 每一个一维数组中具体元素也都已初始化
- 第一个一维数组 arr[0] = {3,8,2};
- 第二个一维数组 arr[1] = {2,7};
- 第三个一维数组 arr[2] = {9,0,1,6};
- 第三个一维数组的长度表示方式:arr[2].length;
|
|
动态初始化
如果二维数组的每一个数据,甚至是每一行的列数,需要后期单独确定,那么就只能使用动态初始化方式了。动态初始化方式分为两种格式:
格式1:规则二维表:每一行的列数是相同的
|
|
-
定义了名称为arr的二维数组
-
二维数组中有3个一维数组
-
每一个一维数组中有2个元素
-
一维数组的名称分别为arr[0], arr[1], arr[2]
-
给第一个一维数组1脚标位赋值为78写法是:
arr[0][1] = 78;
格式2:不规则:每一行的列数不一样
|
|
- 二维数组中有3个一维数组。
- 每个一维数组都是默认初始化值null (注意:区别于格式1)
- 可以对这个三个一维数组分别进行初始化:arr[0] = new int[3]; arr[1] = new int[1]; arr[2] = new int[2];
- 注:
int[][]arr = new int[][3];//非法
数组的长度和角标
- 二维数组的长度/行数:二维数组名.length
- 二维数组的某一行:二维数组名[行下标],此时相当于获取其中一组数据。它本质上是一个一维数组。行下标的范围:[0, 二维数组名.length-1]。此时把二维数组看成一维数组的话,元素是行对象。
- 某一行的列数:二维数组名[行下标].length,因为二维数组的每一行是一个一维数组。
- 某一个元素:二维数组名[行下标][列下标],即先确定行/组,再确定列。
|
|
int[][] scores = { {85,96,85,75}, {99,96,74,72,75}, {52,42,56,75} };
//[:代表二维数组,I代表元素类型是int System.out.println(scores[0]);//[I@6d06d69c
遍历
|
|
默认初始化值
|
|
内存解析
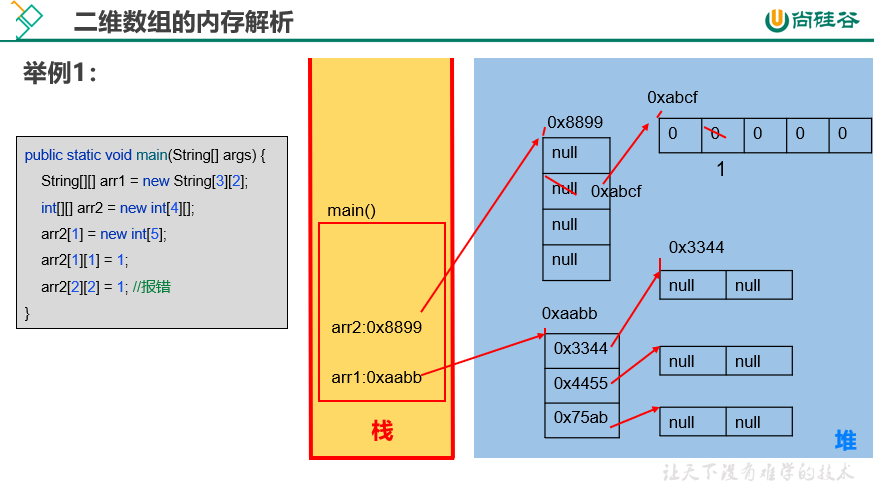
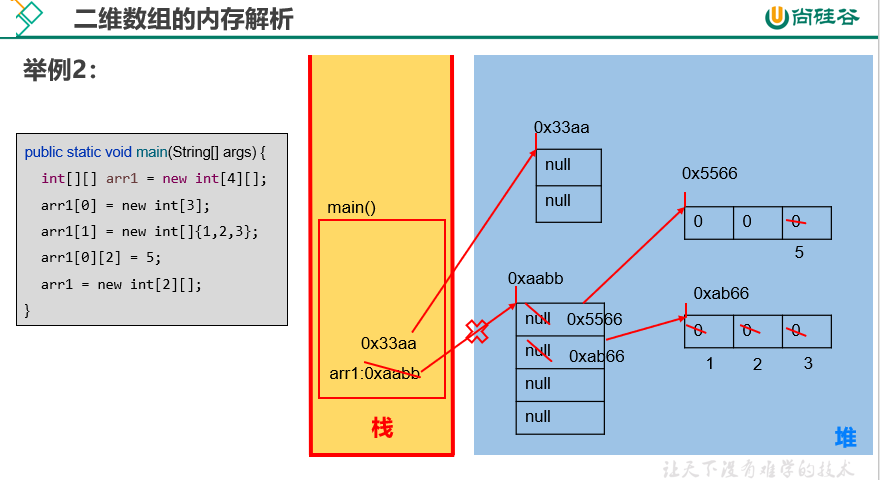
|
|
数组常见算法
|
|
|
|
最大子数组?
输入一个整形数组,数组里有正数也有负数。数组中连续的一个或多个整数组成一个子数组,每个子数组都有一个和。求所有子数组的和的最大值。要求时间复杂度为O(n)。 例如:输入的数组为1, -2, 3, -10, -4, 7, 2, -5,和最大的子数组为3, 10, -4, 7, 2,因此输出为该子数组的和18。
|
|
回形数?
从键盘输入一个整数(1~20) ,则以该数字为矩阵的大小,把1,2,3…n*n 的数字按照顺时针螺旋的形式填入其中。
例如: 输入数字2,则程序输出: 1 2 4 3
输入数字3,则程序输出: 1 2 3 8 9 4 7 6 5
|
|
数组元素的赋值与数组复制
|
|
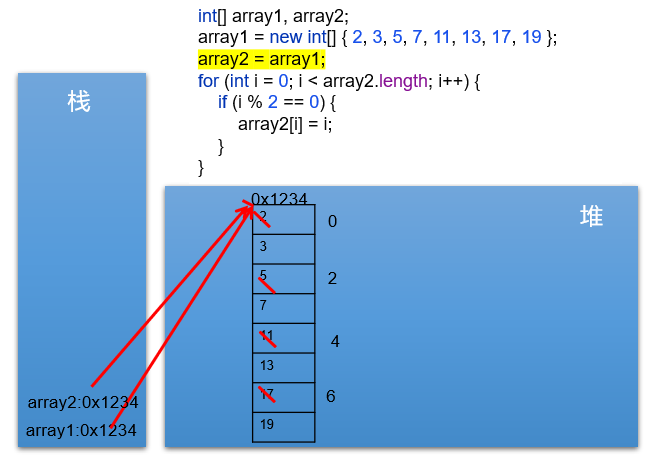
赋值array2变量等于array1
array2 = array1;
array2 = array1=[I@58372a00
arr2,arr1同时指向arr1创建的数组。即arr1,arr2为同一个数组
|
|
数组元素反转
|
|
|
|
数组的扩容与缩容
数组的扩容
题目:现有数组 int[] arr = new int[]{1,2,3,4,5}; ,现将数组长度扩容1倍,并将10,20,30三个数据添加到arr数组中,如何操作?
|
|
数组的缩容
题目:现有数组 int[] arr={1,2,3,4,5,6,7}。现需删除数组中索引为4的元素。
4之后迁移一位,最后一个设为默认初始值0
或者新建数组长度-1
|
|
数组的元素查找
1、顺序查找
顺序查找:挨个查看
要求:对数组元素的顺序没要求
|
|
2、二分查找
要求此数组必须是有序的
|
|
顺序查找: > 优点:算法简单; > 缺点:执行效率低。执行的时间复杂度O(N)
二分法查找: > 优点:执行效率高。执行的时间复杂度O(logN) > 缺点:算法相较于顺序查找难一点;前提:数组必须有序
数组元素排序
算法概述
-
定义
- 排序:假设含有n个记录的序列为{R1,R2,…,Rn},其相应的关键字序列为{K1,K2,…,Kn}。将这些记录重新排序为{Ri1,Ri2,…,Rin},使得相应的关键字值满足条Ki1<=Ki2<=…<=Kin,这样的一种操作称为排序。
- 通常来说,排序的目的是快速查找。
-
衡量排序算法的优劣:
-
时间复杂度:分析关键字的比较次数和记录的移动次数 -
常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)<…<Ο(2n)<Ο(n!)<O(nn)
-
空间复杂度:分析排序算法中需要多少辅助内存1一个算法的空间复杂度S(n)定义为该算法所耗费的存储空间,它也是问题规模n的函数。 -
稳定性:若两个记录A和B的关键字值相等,但排序后A、B的先后次序保持不变,则称这种排序算法是稳定的。
-
排序算法概述
-
排序算法分类:内部排序和外部排序
内部排序:整个排序过程不需要借助于外部存储器(如磁盘等),所有排序操作都在内存中完成。外部排序:参与排序的数据非常多,数据量非常大,计算机无法把整个排序过程放在内存中完成,必须借助于外部存储器(如磁盘)。外部排序最常见的是多路归并排序。可以认为外部排序是由多次内部排序组成。
-
十大内部排序算法 图解
- 数组的排序算法很多,实现方式各不相同,时间复杂度、空间复杂度、稳定性也各不相同:
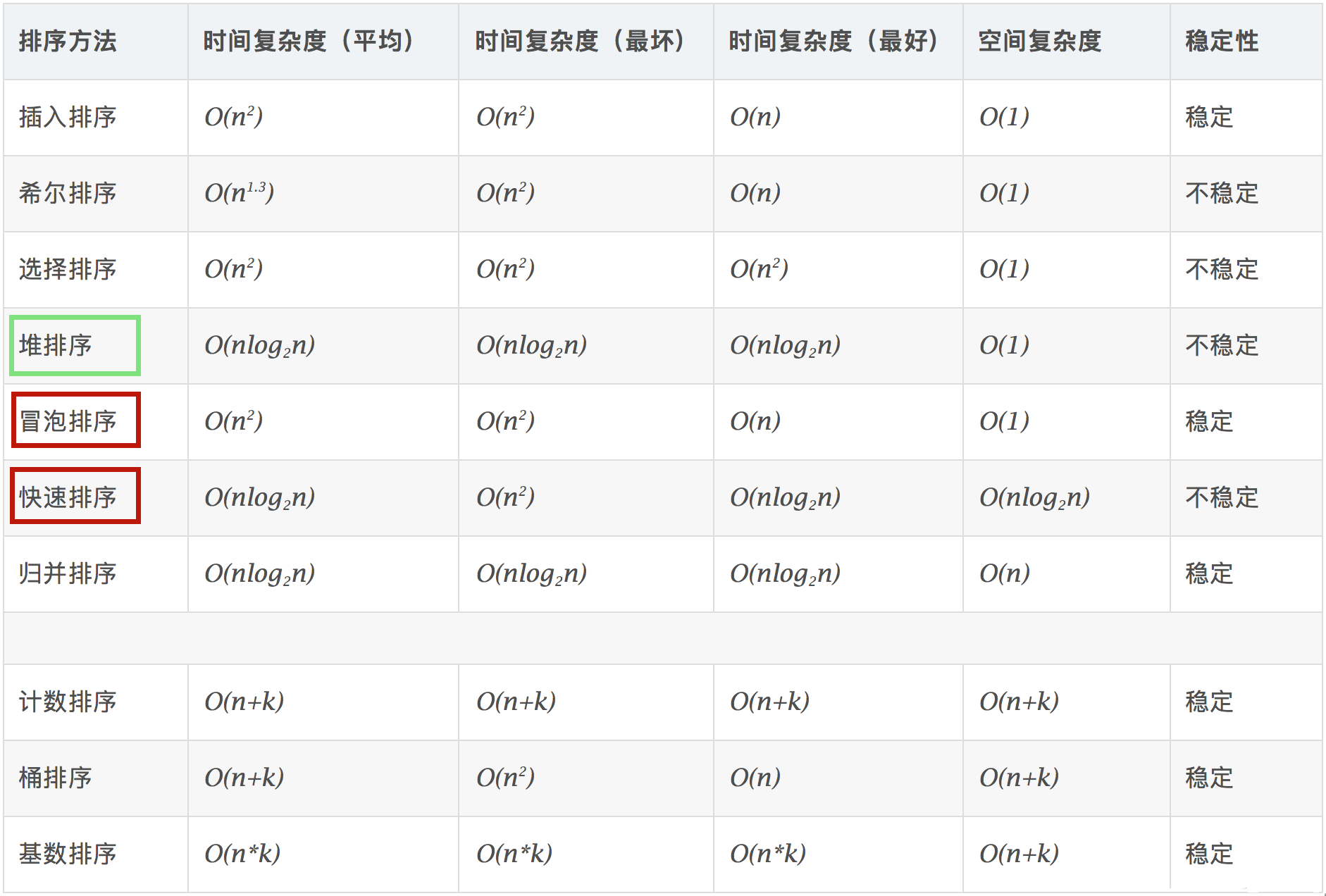
常见时间复杂度所消耗的时间从小到大排序:
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
注意,经常将以2为底n的对数简写成logn。
冒泡排序
时间复杂度O(n^2),第一轮比较n次,共n-1轮–O(n^2)
排序思想:
-
比较相邻的元素。如果第一个比第二个大(升序),就交换他们两个。
-
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
-
针对所有的元素重复以上的步骤,除了最后一个。
-
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较为止。
**动态演示:**https://visualgo.net/zh/sorting
|
|
|
|
|
|
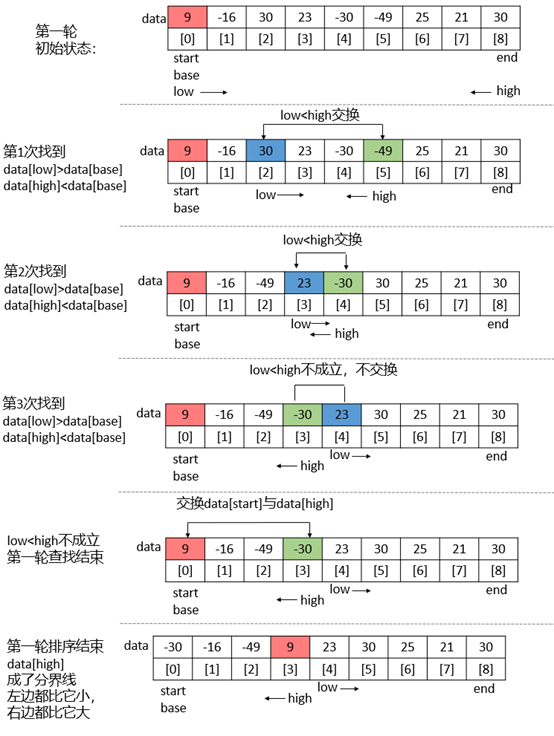
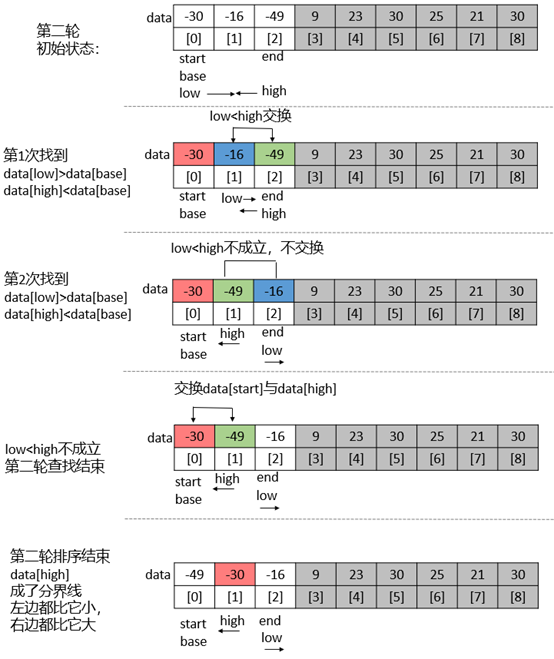
快速排序
时间复杂度为O(nlog(n))–第一轮比较n次,
最好时间复杂度:当每次划分时,算法若都能分成两个等长的子序列时,分治算法效率达到最大
最坏时间复杂度:待排序列有序时,相当于冒泡排序,递归实现会出现栈溢出的现象,时间复杂度为O(N^2)
最好空间复杂度:每次都把待排序列分为相等的两部分,2^x=n (分割x次,保存x个par) ,x = logn,即轮次
快速排序(Quick Sort)由图灵奖获得者Tony Hoare发明,被列为20世纪十大算法之一,是迄今为止所有内排序算法中速度最快的一种,快速排序的时间复杂度为O(nlog(n))。
快速排序通常明显比同为O(nlogn)的其他算法更快,因此常被采用,而且快排采用了分治法的思想,所以在很多笔试面试中能经常看到快排的影子。
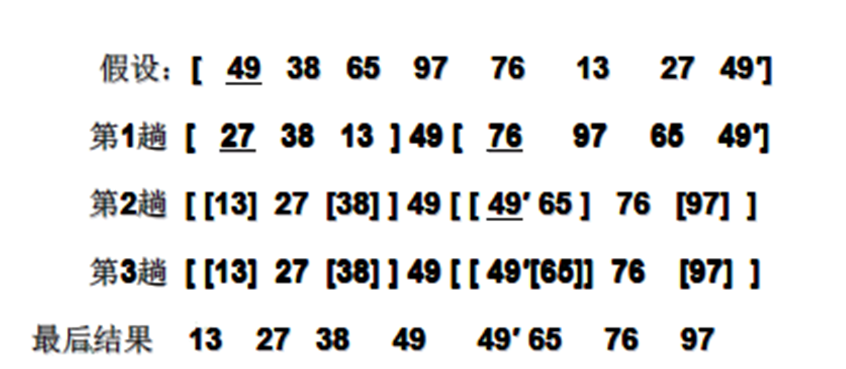
排序思想:
-
从数列中挑出一个元素,称为"基准"(pivot),
-
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
-
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
-
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
**动态演示:**https://visualgo.net/zh/sorting
|
|
|
|
Arrays工具类的使用
java.util.Arrays类即为操作数组的工具类,包含了用来操作数组(比如排序和搜索)的各种方法。 比如:
数组元素拼接- static String toString(int[] a) :字符串表示形式由数组的元素列表组成,括在方括号("[]")中。相邻元素用字符 “, “(逗号加空格)分隔。形式为:[元素1,元素2,元素3。。。]
- static String toString(Object[] a) :字符串表示形式由数组的元素列表组成,括在方括号("[]")中。相邻元素用字符 “, “(逗号加空格)分隔。元素将自动调用自己从Object继承的toString方法将对象转为字符串进行拼接,如果没有重写,则返回类型@hash值,如果重写则按重写返回的字符串进行拼接。
数组排序- static void sort(int[] a) :将a数组按照从小到大进行排序
- static void sort(int[] a, int fromIndex, int toIndex) :将a数组的[fromIndex, toIndex)部分按照升序排列
- static void sort(Object[] a) :根据元素的自然顺序对指定对象数组按升序进行排序。
- static
void sort(T[] a, Comparator<? super T> c) :根据指定比较器产生的顺序对指定对象数组进行排序。
数组元素的二分查找- static int binarySearch(int[] a, int key) 、static int binarySearch(Object[] a, Object key) :要求数组有序,在数组中查找key是否存在,如果存在返回第一次找到的下标,不存在返回负数。
数组的复制- static int[] copyOf(int[] original, int newLength) :根据original原数组复制一个长度为newLength的新数组,并返回新数组
- static
T[] copyOf(T[] original,int newLength):根据original原数组复制一个长度为newLength的新数组,并返回新数组 - static int[] copyOfRange(int[] original, int from, int to) :复制original原数组的[from,to)构成新数组,并返回新数组
- static
T[] copyOfRange(T[] original,int from,int to):复制original原数组的[from,to)构成新数组,并返回新数组
比较两个数组是否相等- static boolean equals(int[] a, int[] a2) :比较两个数组的长度、元素是否完全相同
- static boolean equals(Object[] a,Object[] a2):比较两个数组的长度、元素是否完全相同
填充数组- static void fill(int[] a, int val) :用val值填充整个a数组
- static void fill(Object[] a,Object val):用val对象填充整个a数组
- static void fill(int[] a, int fromIndex, int toIndex, int val):将a数组[fromIndex,toIndex)部分填充为val值
- static void fill(Object[] a, int fromIndex, int toIndex, Object val) :将a数组[fromIndex,toIndex)部分填充为val对象
|
|
|
|
数组中的常见异常
数组角标越界异常
当访问数组元素时,下标指定超出[0, 数组名.length-1]的范围时,就会报数组下标越界异常:ArrayIndexOutOfBoundsException。
创建数组,赋值3个元素,数组的索引就是0,1,2,没有3索引,因此我们不能访问数组中不存在的索引,程序运行后,将会抛出 ArrayIndexOutOfBoundsException 数组越界异常。在开发中,数组的越界异常是不能出现的,一旦出现了,就必须要修改我们编写的代码。
空指针异常
|
|
因为此时数组的每一行还未分配具体存储元素的空间,此时arr[0]是null,此时访问arr[0][0]会抛出NullPointerException 空指针异常。
Author kong
LastMod 2024-01-23