Jupyter
Contents
pip不能使用:
https://blog.csdn.net/hll19950830/article/details/88551506
安装:
https://www.zhihu.com/collection/261855801
https://www.jianshu.com/p/91365f343585
https://blog.csdn.net/liboshi123/article/details/116809849
一劳永逸配置pip源(推荐):只需在windows命令行中输入一行命令,即可永久设置pip下载源为国内源
1pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
帮助:jupyter notebook –help
启动:在cmd命令行中,输入:jupyter notebook
配置默认启动路径:命令行输入命令:jupyter notebook –generate-config,找到“c.NotebookApp.notebook_dir=……”,把路径改成自己的工作目录。
快捷键:https://blog.csdn.net/qq_37294751/article/details/79489910
Jupyter Notebook的基本使用
https://www.jianshu.com/p/91365f343585
File页面:
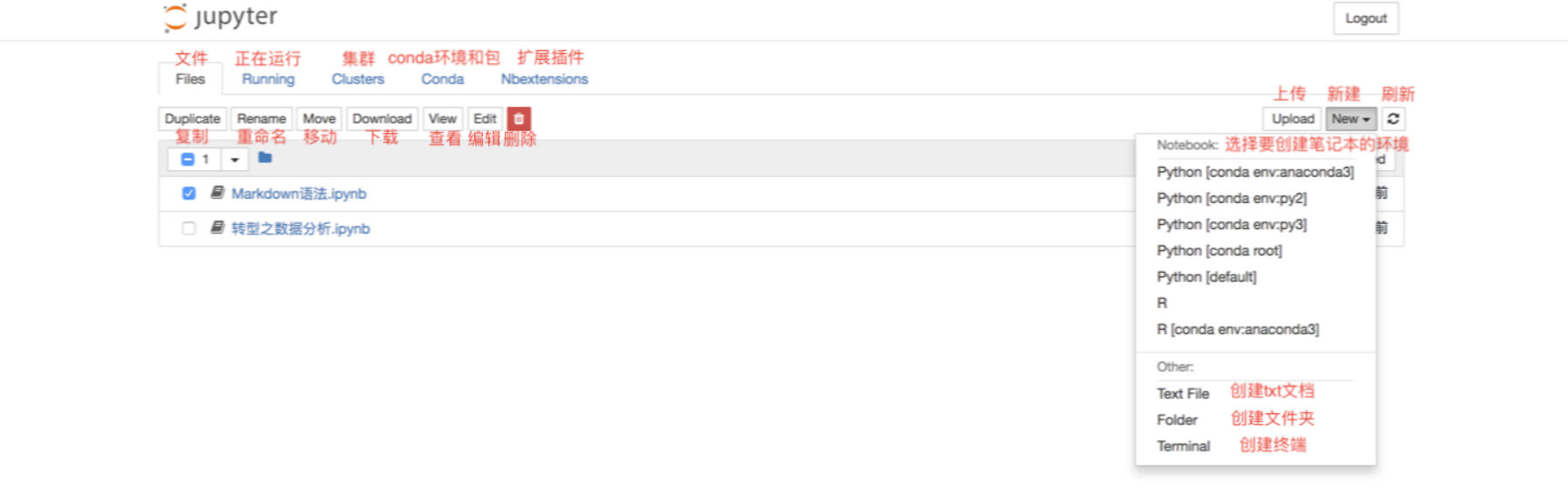
对于现有的文件,可以通过勾选文件的方式,对选中文件进行复制、重命名、移动、下载、查看、编辑和删除的操作。
同时,也可以根据需要,在“New”下拉列表中选择想要创建文件的环境,进行创建“ipynb”格式的笔记本、“txt”格式的文档、终端或文件夹。
笔记本的基本操作
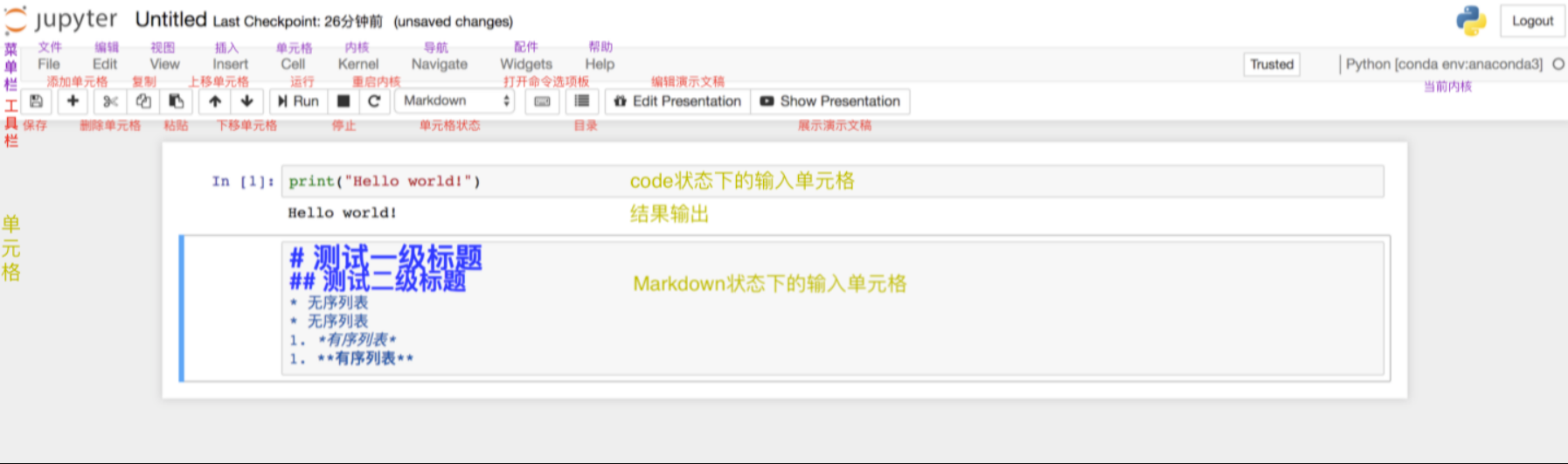
笔记本重命名的两种方式:
⑴ 笔记本内部重命名
在使用笔记本时,可以直接在其内部进行重命名。在左上方“Jupyter”的图标旁有程序默认的标题“Untitled”,点击“Untitled”然后在弹出的对话框中输入自拟的标题,点击“Rename”即完成了重命名。
⑵ 笔记本外部重命名
若在使用笔记本时忘记了重命名,且已经保存并退出至“Files”界面,则在“Files”界面勾选需要重命名的文件,点击“Rename”然后直接输入自拟的标题即可。
Running页面
Running页面主要展示的是当前正在运行当中的终端和“ipynb”格式的笔记本。若想要关闭已经打开的终端和“ipynb”格式的笔记本,仅仅关闭其页面是无法彻底退出程序的,需要在Running页面点击其对应的“Shutdown”。
教程
https://www.zhihu.com/zvideo/1346452501533818881
执行快捷键:shift+回车,运行并到达下一行;ctrl+回车,只运行这一行
自动补全:Tab
Help: np.random.random? np.random.random():光标放在括号里,按住shift双击Tab
魔术命令:
专属于jupyter notebook的方法,带%的
%matplotlib inline
让画出来的图直接显示在web界面内
|
|
|
|
[<matplotlib.lines.Line2D at 0x21f15d5fb08>]
推荐个更简单的方法,直接使用pip下载清华大学的matplotlib镜像,代码是:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib。这个镜像会自己把matplotlib需要的库顺便安装了,这样一行代码就可以搞定。
%pwd
查看当前目录
%timeit [x**3 for x in range(1000)]
执行本行代码所需要的时间
python数据分析神器Jupyter notebook快速入门
内核是ipython,可以命令行直接输ipython进入
数据分析与可视化案例:学习时间与成绩的关系(线性回归)
数据集csv,用逗号隔开的数据,也可以用excel打开自动转化为单元格

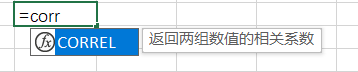
第1步:导入数据分析库pandas,数据可视化库matplotlib
%matplotlib inline是Ipython的魔法函数,其作用是使matplotlib绘制的图像嵌入在juptyer notebook的单元格里
|
|
第2步:导入数据集,查看数据集
|
|
| Hours | Scores | |
|---|---|---|
| 0 | 2.5 | 21 |
| 1 | 5.1 | 47 |
| 2 | 3.2 | 27 |
| 3 | 8.5 | 75 |
| 4 | 3.5 | 30 |
| 5 | 1.5 | 20 |
| 6 | 9.2 | 88 |
| 7 | 5.5 | 60 |
| 8 | 8.3 | 81 |
| 9 | 2.7 | 25 |
|
|
pandas.core.frame.DataFrame
|
|
(25, 2)
|
|
Index(['Hours', 'Scores'], dtype='object')
|
|
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25 entries, 0 to 24
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Hours 25 non-null float64
1 Scores 25 non-null int64
dtypes: float64(1), int64(1)
memory usage: 528.0 bytes
|
|
| Hours | Scores | |
|---|---|---|
| count | 25.000000 | 25.000000 |
| mean | 5.012000 | 51.480000 |
| std | 2.525094 | 25.286887 |
| min | 1.100000 | 17.000000 |
| 25% | 2.700000 | 30.000000 |
| 50% | 4.800000 | 47.000000 |
| 75% | 7.400000 | 75.000000 |
| max | 9.200000 | 95.000000 |
第3步:提取特征
提取特征:学习时间 提取标签:学习成绩
|
|
|
|
|
|
| Hours | |
|---|---|
| 0 | 2.5 |
| 1 | 5.1 |
| 2 | 3.2 |
| 3 | 8.5 |
| 4 | 3.5 |
|
|
pandas.core.frame.DataFrame
|
|
| Scores | |
|---|---|
| 0 | 21 |
| 1 | 47 |
| 2 | 27 |
| 3 | 75 |
| 4 | 30 |
|
|
|
|
array([[2.5],
[5.1],
[3.2],
[8.5],
[3.5],
[1.5],
[9.2],
[5.5],
[8.3],
[2.7],
[7.7],
[5.9],
[4.5],
[3.3],
[1.1],
[8.9],
[2.5],
[1.9],
[6.1],
[7.4],
[2.7],
[4.8],
[3.8],
[6.9],
[7.8]])
|
|
(25, 1)
|
|
第四步:建立模型
拆分数据,四分之三的数据作为训练集,四分之一的数据作为测试集
|
|
用训练集的数据进行训练
|
|
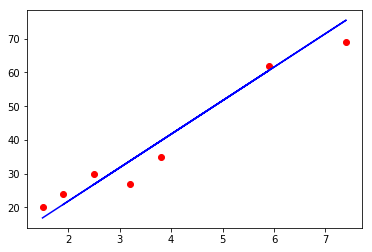
对测试集进行预测
|
|
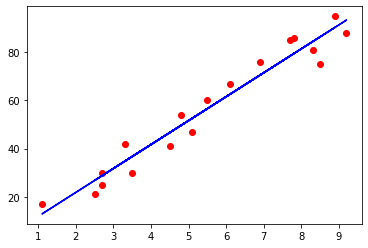
可视化
|
|
|
|
Author kong
LastMod 2021-10-19