MMVFL
Contents
Multi-Participant Multi-Class Vertical Federated Learning
多参与者多类纵向联邦学习
Abstract
联邦学习(FL)是一种使用本地存储的来自多个参与者的数据来训练集体机器学习模型的隐私保护范例。纵向联邦学习(VFL)处理的是参与者共享相同的样本ID空间,但拥有不同的特征空间,而标签信息由一个参与者拥有的情况。目前的VFL研究仅支持两名参与者,且多集中在二元类逻辑回归问题上。在本文中,我们提出了一个多参与者多类纵向联邦学习(MMVFL)框架来解决涉及多方的多类VFL问题,MMVFL扩展了多视图学习(MVL)的思想,以一种隐私保护的方式实现了从其所有者到其他VFL参与者的标签共享。为了验证MMVFL的有效性,在MMVFL中加入了一种特征选择方案,并将其性能与监督特征选择supervised feature selection和MVL-based方法进行了比较。 在真实数据集上的实验结果表明,MMVFL能够有效地在多个VFL参与者之间共享标签信息,并与现有方法的多类分类性能相匹配。
Introduction
传统的机器学习(ML)方法要求所有数据和学习过程都集中在一个中心实体中。 这限制了他们处理真实世界应用程序的能力,在这些应用程序中,数据在不同的组织中被隔离,并且数据隐私受到强调。 联邦学习(FL)是一种分布式的、保护隐私的ML范式,非常适合这种场景,并吸引了越来越多的关注。
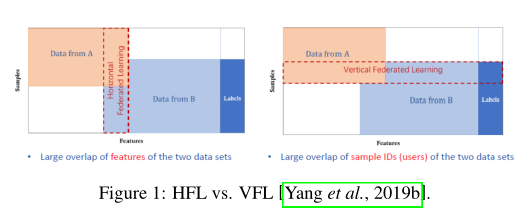
现有的FL方法主要关注横向联邦学习(HFL),该方法假设来自不同参与者的数据集共享相同的特征空间,但可能不共享相同的样本ID空间(图1-Left)。大多数现有的HFL方法旨在为所有参与者培训一个单一的全球模型,而少数方法侧重于为每个参与者学习单独的模型。纵向联合学习(VFL)假设来自不同参与者的数据集不共享相同的特征空间,但可能共享相同的样本ID空间。此外,假设标签信息由一个参与者持有。例如,两家电子商务公司和一家银行都为来自同一城市的用户提供服务,它们可以通过VFL培训一个模型,根据用户的在线购物行为为用户推荐个性化贷款。在这种情况下,只有银行持有预期VFL任务的标签信息。VFL中的一个关键挑战是如何使来自一个参与者的本地标签信息以保护隐私的方式用于训练FL模型。
现有的VFL方法只能处理两个VFL参与者,并且通常专注于二进制分类任务。这使得它们不适用于涉及多个参与者的VFL应用程序中的复杂分类任务。为了解决这一局限性,本文提出了多参与者多类纵向联邦学习(MMVFL)框架。 它扩展了多视图学习(MVL)的思想,该思想针对同一输入数据的多个独立视图的任务联合学习多个模型,以建立适用于多个参与者的多类问题的VFL框架。与[Smith等人,2017]中提出的多任务FL框架一样,MMVFL为每个参与者学习一个单独的模型,而不是为所有参与者学习一个单一的全局模型,以使学习过程更加个性化。 此外,MMVFL允许标签所有者向其他参与者共享标签,以促进联合模型训练。 值得一提的是,MMVFL保护隐私,这意味着数据和标签在培训过程中不会离开其所有者。
此外,我们还提出了一种基于MMVFL的特征重要性评估方案。它可以量化每个参与者的不同特征对FL模型的贡献。通过在初始训练期间丢弃冗余和有害的特征,VFL系统的通信、计算和存储成本可以在增量学习设置下的后续训练中降低。 据我们所知,MMVFL是第一个针对多个参与者的多类问题的VFL框架。 通过广泛的实验评估,我们证明MMVFL可以有效地在多个VFL参与者之间共享标签信息,并匹配现有方法的多类分类性能。
Related Work
VFL适用于参与者拥有共享相同样本ID空间但具有不同特征空间的数据集的FL场景。 VFL的想法最早是在[Hardy等人,2017]中提出的,其中联邦逻辑回归方案是用加性同态方案加密的消息来设计的。它还提供了实体解析错误对学习影响的正式分析。[Nock等人,2018]然后扩展[Hardy等人,2017],提供了实体解析错误对学习的影响的正式评估,涵盖了一系列广泛的损失。[Yang et al., 2019a]和[Yang et al., 2019d]是[Hardy et al., 2017]的两个扩展,假设样本id已经匹配。前者通过提出一种基于有限内存的BFGS算法的隐私保护优化框架来减少所需的通信次数。后者通过删除第三方协调器来构建并行分布式系统,降低了数据泄漏的风险,降低了系统的复杂性。
在[Wang et al., 2019]中,作者提出了一种在VFL参与者的本地数据集中评估特征重要性的方法。该方法采用基于Shapley值的方法,动态去除不同的特征组,以评估对FL模型性能的影响。它能够在特征组的粒度上评估特征的重要性。此外,Shapley值的计算产生了指数计算复杂度,使其难以扩大。
然而,这些方法只能处理两个VFL参与者,并且通常侧重于二元分类任务。这限制了这些方法在实际应用场景中的适用性。提议的MMVFL比这些最先进的方法更有优势,因为它被设计为支持多类多参与者的VFL设置,这使得通过VFL出现更复杂的业务协作成为可能。
Preliminaries
正文前书页
Multi-View Learning
多视图学习
MVL方法的目标是学习一个函数对每个视图建模,并联合优化所有函数以提高泛化性能。假设来自每个视图的数据共享相同的示例ID空间,但具有不同的特征,这使得MVL非常适合VFL场景。遗憾的是,现有的MVL方法在学习过程中需要来自不同视图的原始数据进行交互,由于违反了隐私保护的要求,不适合直接应用到FL中。
多视图用于表示数据的不同特征集,多视图还可以用于表示数据的不同来源;例如对于同一个数据源,用不同的采集装置进行采集,这多个采集结果构成了数据的不同视图;另外,多视图还可以用于表示数据间的不同关系;例如,学术论文的分类问题中,论文间既有参考文献的引用关系,也有作者的合作关系。
用视图X(l)训练的分类器可以把它对未标记数据的分类结果中比较置信那些的未标记数据,连同它对那些未标记数据的分类结果,一起提供给视图X(2)上的分类器,然后,用视图x(2)训练的分类器能够利用从视图X(l)上得到的信息,排除自身的不确定性,从而提高用视图X(2)训练的分类器性能,反之亦然,多视图学习正是利用数据在不同的视图学习的难易程度不同,来发挥视图之间的相互作用,,优势互补,协同学习。
Feature Selection
特征选择
特征选择是一组常用的降维方法,用于从给定学习任务的数据集中选择有用的特征子集。根据特征的重要性对数据进行压缩,可以节省通信成本。特征选择的一种常见做法是首先测量每个特征对学习任务的重要性,并丢弃不太重要的特征。
Feature Selection:特征选择想要做的是:选择尽可能少的子特征,模型的效果不会显著下降,并且结果的类别分布尽可能的接近真实的类别分别。对于一个有N个特征的对象,可以产生2^N个特征子集,特征选择就是从这些子集中选出对于特定任务最好的子集。特征选择主要包括四个过程:
- 生成过程:生成候选的特征子集;
- 评价函数:评价特征子集的好坏;
- 停止条件:决定什么时候该停止;
- 验证过程:特征子集是否有效;
将属性称为特征,对当前学习有用的属性称为相关特征。从给定的特征集合中选择出相关子集特征的过程,称为特征选择。
子集搜索:前向-逐渐增加相关特征的策略,后向-逐渐减少,双向。
子集评价:信息增益Gain(A)越大,意味着特征子集A包含的有助于分类的信息越多。信息熵是度量样本集合纯度的一种指标(按某种属性划分)。Ent(D)的值越小,则D的纯度越高。
例:首先由整体D的正反例也计算信息熵,然后计算每个属性的信息增益。以一个属性对应的取值对数据集进行分类为D1,D2,D3;进而计算Di的信息熵。进而得到该属性对应的信息增益。信息增益越大,意味着使用属性a来进行划分来获得纯度提升越大。
常用特征选择的方式:过滤式,包裹式,嵌入式。
The Proposed MMVFL Framework
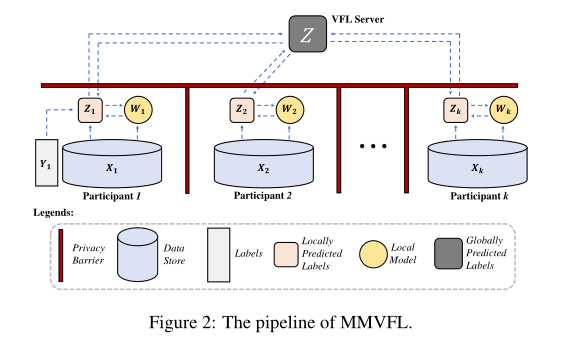
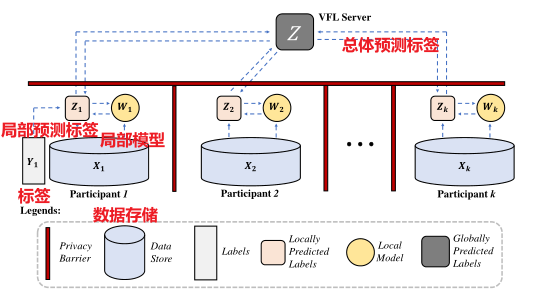
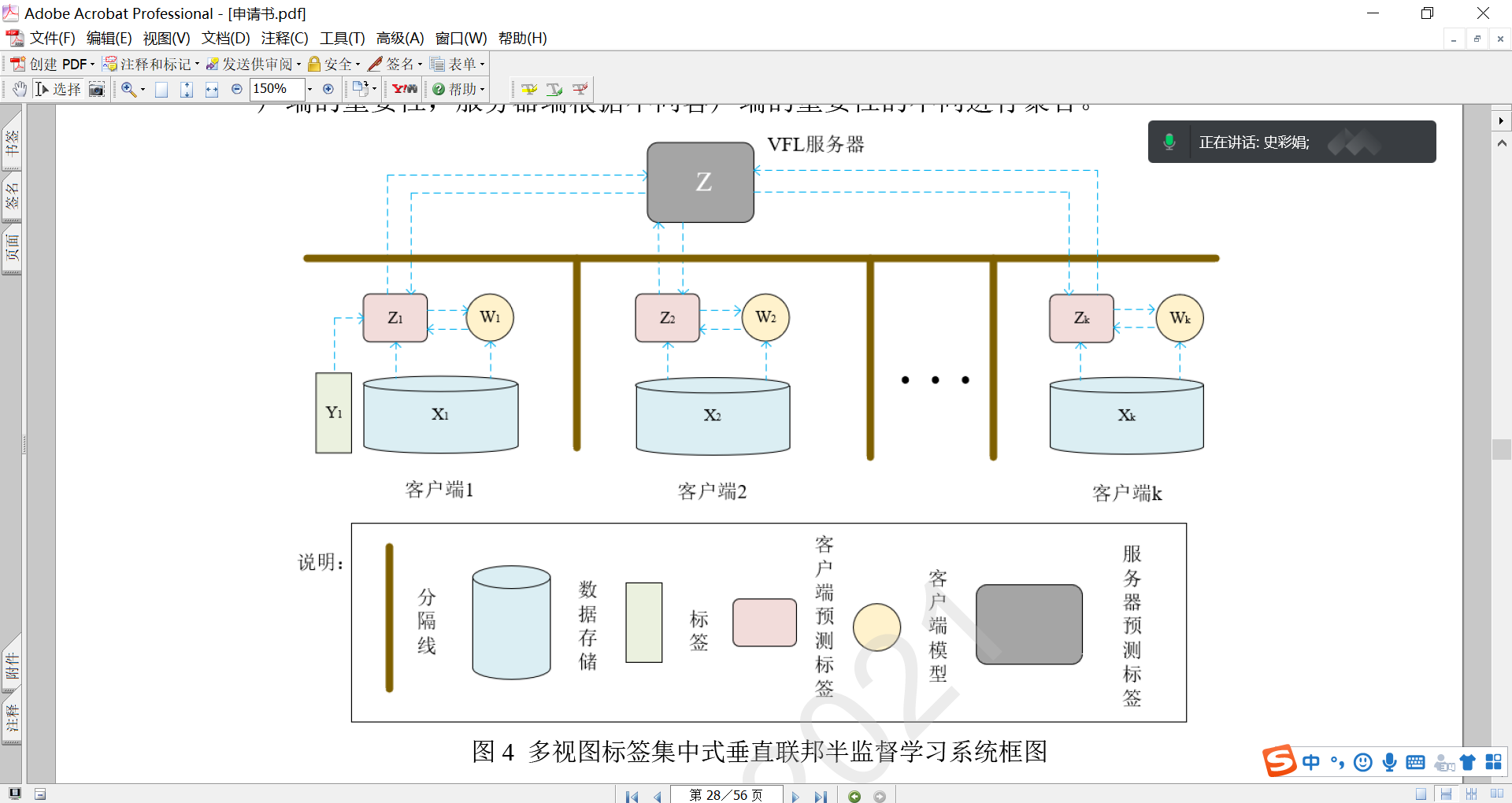
MMVFL的传递途径如图2所示。根据设计,只有本地预测的标签才能跨越隐私壁垒到达VFL服务器。 在训练全局FL模型时,无需原始数据、标签或本地模型离开其所有者的机器。在本节中,我们将介绍MMVFL的问题定义和细节。
Notations and Problem Definition
符号和问题定义

对于一个涉及K个参与者的Nc类问题的VFL任务,每个参与者都拥有一个本地存储的数据集Xk ∈ R N×dk,用于FL模型训练。dk为数据集的维数,N为数据集中的样本个数。假设标签信息为一个参与者所有。在不丧失一般性的情况下,我们假设第一个参与者拥有这些标签。 这里的研究问题是如何将标签信息从第一个参与者转移到其他参与者进行VFL模型训练,同时对每个参与者进行特征重要性评估。 本文假设样本ID已经匹配。
Sparse Learning-based Unsupervised Feature Selection
基于稀疏学习的无监督特征选择
对于无法访问标签信息的参与者,采用无监督特征选择来选择代表数据底层子空间结构的特征。设计了一个变换矩阵,将数据投影到一个新的空间,并根据变换矩阵的稀疏性指导特征选择。
MMVFL通过优化以下目标函数对第k个参与者进行特征选择:
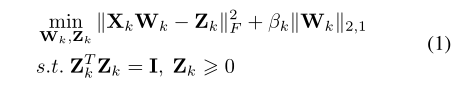
其中βk是一个平衡参数,Wk∈ R dk×Nc是变换矩阵,Zk∈ RN×Nc是一个嵌入矩阵,其中每一行表示对应数据点的表示。第二项作为正则化函数用于增强特征重要性度量,这两个约束使Zk能够充当Xk的伪标签矩阵。
嵌入式特征选择,在学习器训练的过程中自动地进行了特征选择。
一旦产生Wk,则每个特征的重要度得分由Wk对应行的2-1范数值来计算。尽管近年来提出了复杂的基于稀疏学习的无监督特征选择算法,但由于其简单性,我们采用了线性变换方法,因为我们的重点是提供概念证明,而不是穷尽所有可能的特征选择方案。
Privacy-Preserving Label Sharing
保护隐私的标签共享
由于大多数的MVL方法都假设所有的视图共享相同的标签空间,并且通过标签空间相互关联,所以式(1)中的局部特征选择方案可以适应于MVL,如下所示:
(理解:一个视图相当于一个VFL的一个参与者)
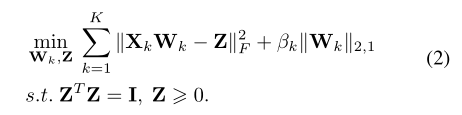
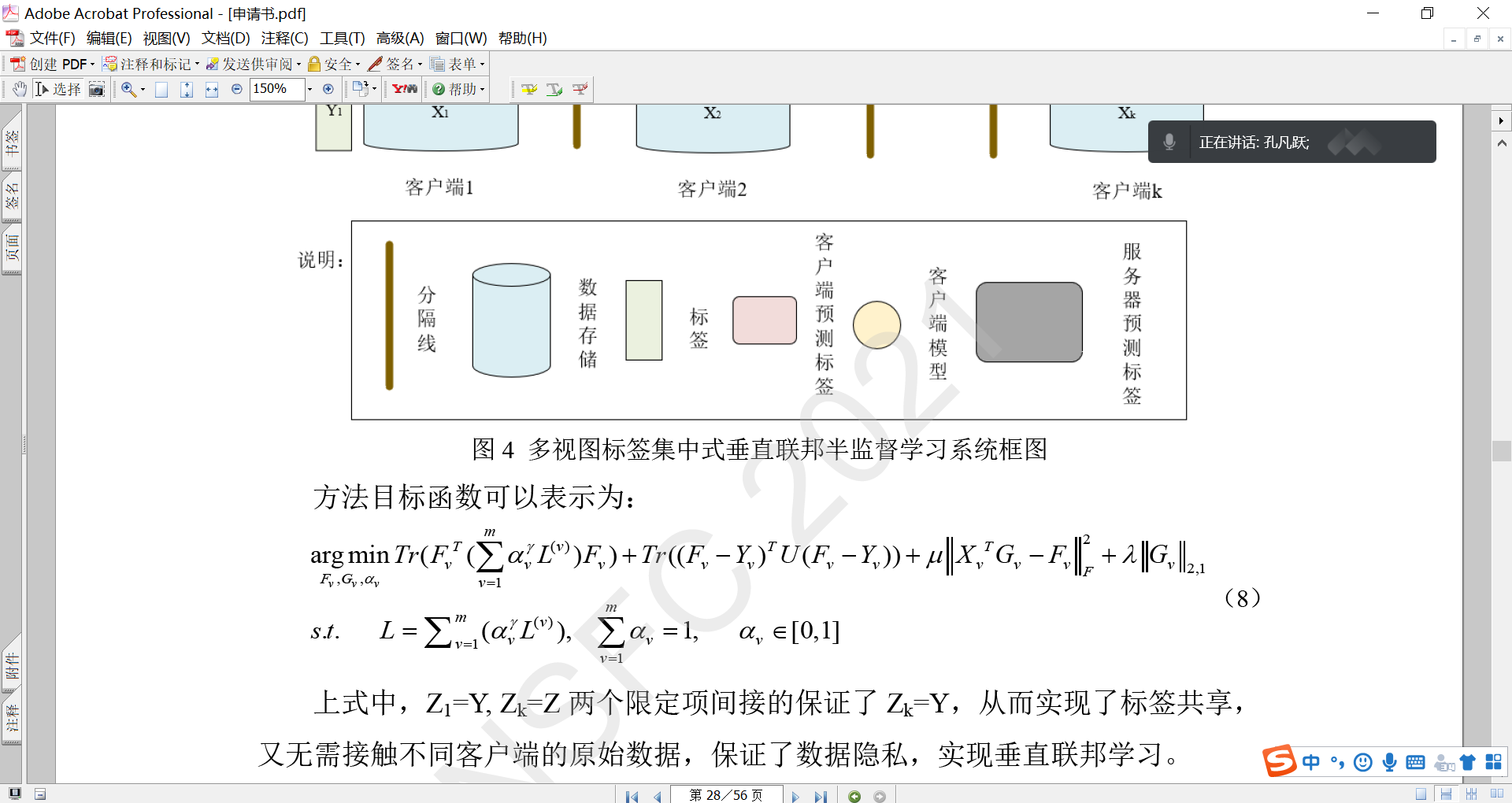
然而,Z的优化需要从不同的视图访问原始数据。因此,它不能直接应用于VFL。为了使等式(2)适应VFL,我们提出以下目标函数:
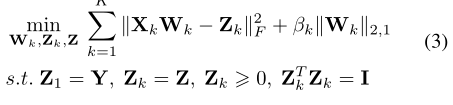
其中,Y∈{0,1}N ×N c是包含第一个参与者拥有的标签信息的一个独热one-hot 矩阵。
根据等式(3),每个参与者在本地训练伪标签矩阵Zk。
约束条件ZK=Z确保这些本地学习的矩阵相等(Z是来自所有参与者的数据共享相同标签空间的实现)。
约束条件Z1=Y确保第一个参与者学习的伪标签与真实标签相等。Y是one-hot矩阵,所以是一组代表标签的数字
请注意,两个约束条件Zk=Z和Z1=Y的组合间接确保了Zk等于Y。 这实现了标签共享,而无需直接访问来自不同参与者的原始数据,因此适合VFL操作。
理解:第一个参与者拥有真实的标签信息,通过本地模型的预测标签,并保证Z1=Y保证预测标签的真实性,再由Z=Z1,得出公共模型的标签。其余参与者不具备本地标签,通过无监督学习得到伪标签Zk,而约束条件使得Zk=Z,便实现的标签的共享,无需访问原始数据。
每个参与者的特征空间是不同的。即使进行了特征选择,应该也是不同的。但是通过模型进行预测标签的结果是相同的。
Optimization
最优化
我们通过分别向其添加足够大的惩罚项ζk和η来放松Zk=Z和Z1=Y的约束。等式(3)可以改写为:
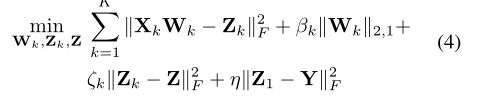
注意,ZT_k Zk=I和Zk>0的约束被忽略,因为ζk和η的大值确保Zk接近Y。Y满足Y^TY=I和Y>=0这一事实使得这两个约束是多余的。
由于“2,1-范数正则化项”,等式(4)中优化问题的闭式解很难获得。 为了解决这个问题,我们设计了一种替代的优化方法,所有参数迭代更新,直到(4)中的目标函数值收敛或达到最大迭代次数。
。。。。。。

Analysis
Convergence
聚合
Z1,Zk(k=1,2,···,k)和Z的优化问题,在其他参数不变的情况下,都是具有全局极小值的简单凸优化问题。根据[Hou等人,2014]中的相同分析,可以很容易地证明Wk的优化方案能够使等式(5)持续下降,直到收敛。 这样,目标函数在优化过程中始终保持不变。
Time Complexity
对于VFL的第k个参与者,MMVFL下本地培训期间最耗时的部分是按照式(8)优化工作。 时间复杂度为O(d^3_k)。 由于所提出的优化方案需要所有参与者之间的每次迭代通信,联邦学习的每次迭代的时间复杂度为O((maxk(dk))3,这意味着在MMVFL下进行FL训练所需的时间取决于每轮中最慢的参与者(称为掉队者)。
Privacy Preservation
MMVFL的主要思想是,每个参与者在本地学习自己的模型参数Wk和Zk,而Z以联合方式更新,如等式(14)所示。在此过程中,只需要将来自所有参与者的Zk值传输到FL服务器,而Xk和Y值由其所有者本地存储。 因此,MMVFL提供了一种隐私保护标签共享,因为转换矩阵不足以用于派生原始数据,即使它们在多轮中被恶意实体截获。
Conclusions and Future Work
在本文中,我们提出了一个多参与者多类纵向联邦学习(MMVFL)框架,该框架将其所有者的标签信息共享给所有其他参与者,而不会造成数据泄漏。 与现有的只能支持两个参与者的类似技术不同,MMVFL可以在更复杂的场景中工作,因此适合更广泛的应用。据我们所知,这是第一次尝试将多视角学习方法转移到VFL环境中。 实验结果表明,该算法在特征选择方面的性能可以与有监督的算法相媲美。
在后续的研究中,我们将重点关注三个主要方向来进一步提高MMVFL。首先,我们计划探索如何将更复杂的分类技术纳入这个框架,以扩大其适用性。其次,我们将提高MMVFL的通信效率,并探索其更有效地处理掉队者的方法。最后,我们将探讨VFL中不同参与者在任务间的关系对整体FL模型表现的影响。
Author kong
LastMod 2022-01-11