函数和模块
Contents
函数的作用
“代码有很多种坏味道,重复是最坏的一种!”。要写出高质量的代码首先要解决的就是重复代码的问题。我们可以将计算阶乘的功能封装到一个称为“函数”的代码块中,在需要计算阶乘的地方,我们只需要“调用函数”就可以了。
函数是功能相对独立且会重复使用的代码的封装
定义函数
我们通常把Python中函数的自变量称为函数的参数,而因变量称为函数的返回值。
在Python中可以使用def关键字来定义函数,和变量一样每个函数也应该有一个漂亮的名字,命名规则跟变量的命名规则是一致的。在函数名后面的圆括号中可以放置传递给函数的参数,就是我们刚才说到的函数的自变量,而函数执行完成后我们会通过return关键字来返回函数的执行结果,就是我们刚才说的函数的因变量。一个函数要执行的代码块(要做的事情)也是通过缩进的方式来表示的,跟之前分支和循环结构的代码块是一样的。def那一行的最后面还有一个:!
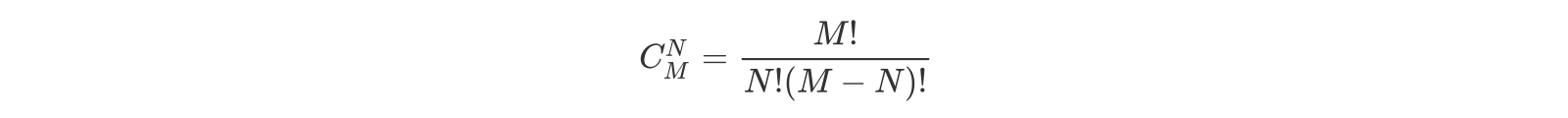
|
|
说明: Python的
math模块中其实已经有一个名为factorial函数实现了阶乘运算,事实上求阶乘并不用自己定义函数。我们讲的函数在Python标准库已经实现过了,我们这里是为了讲解函数的定义和使用才把它们又实现了一遍,实际开发中并不建议做这种低级的重复劳动。
函数的参数
函数是绝大多数编程语言中都支持的一个代码的"构建块",但是Python中的函数与其他语言中的函数还是有很多不太相同的地方,其中一个显著的区别就是Python对函数参数的处理。在Python中,函数的参数
可以有默认值,也支持使用可变参数,所以Python并不需要像其他语言一样支持函数的重载
参数的默认值
如果函数中没有return语句,那么函数默认返回代表空值的None。另外,在定义函数时,函数也可以没有自变量,但是函数名后面的圆括号是必须有的。Python中还允许函数的参数拥有默认值。调用的时候如果没指定参数,就使用默认参数。如果指定了,就是指定的参数。
|
|
注意:带默认值的参数必须放在不带默认值的参数之后,否则将产生
SyntaxError错误,错误消息是:non-default argument follows default argument,翻译成中文的意思是“没有默认值的参数放在了带默认值的参数后面”。
可变参数
我们还可以实现一个对任意多个数求和的add函数,因为Python语言中的函数可以通过星号表达式语法来支持可变参数。所谓可变参数指的是在调用函数时,可以向函数传入0个或任意多个参数。
|
|
用模块管理函数
Python中每个文件就代表了一个模块(module),我们在不同的模块中可以有同名的函数,在使用函数的时候我们通过import关键字导入指定的模块再使用完全限定名的调用方式就可以区分到底要使用的是哪个模块中的foo函数,代码如下所示。
module1.py
|
|
module2.py
|
|
test.py
|
|
在导入模块时,还可以使用as关键字对模块进行别名,这样我们可以使用更为简短的完全限定名。
test.py
|
|
上面的代码我们导入了定义函数的模块,我们也可以使用from...import...语法从模块中直接导入需要使用的函数,代码如下所示。
test.py
|
|
但是,如果我们如果从两个不同的模块中导入了同名的函数,后导入的函数会覆盖掉先前的导入,就像下面的代码中,调用foo会输出hello, world!,因为我们先导入了module2的foo,后导入了module1的foo 。如果两个from...import...反过来写,就是另外一番光景了。
test.py
|
|
如果想在上面的代码中同时使用来自两个模块中的foo函数也是有办法的,还是用as关键字对导入的函数进行别名,代码如下所示。
test.py
|
|
需要说明的是,如果我们导入的模块除了定义函数之外还中有可以执行代码,那么Python解释器在导入这个模块时就会执行这些代码,事实上我们可能并不希望如此,
因此如果我们在模块中编写了执行代码,最好是将这些执行代码放入如下所示的条件中,这样的话除非直接运行该模块,if条件下的这些代码是不会执行的,因为只有直接执行的模块的名字才是"__main__"。
module3.py
|
|
Python定义函数,必须有函数体,否则编译就会报错。函数体用一句
pass占位是防止报错,并且不会有任何动作。这种只有pass的函数一般有以下几种可能:1、父类中声明函数,但不声明实现,由继承的子类进行实现,也就是说这就是一个空方法;
2、这个函数的具体实现不用Python编写,而是由例如C这种高效语法编写,在包中只用一个空方法占位,调用的时候是调用C语言实现的方法。Python中有一些需要大量运算的内置函数是用C或者C++写的。
test.py
|
|
标准库中的模块和函数
Python标准库中提供了大量的模块和函数来简化我们的开发工作,我们之前用过的random模块就为我们提供了生成随机数和进行随机抽样的函数;而time模块则提供了和时间操作相关的函数;上面求阶乘的函数在Python标准库中的math模块中已经有了,实际开发中并不需要我们自己编写,而math模块中还包括了计算正弦、余弦、指数、对数等一系列的数学函数。随着我们进一步的学习Python编程知识,我们还会用到更多的模块和函数。
Python标准库中还有一类函数是不需要import就能够直接使用的,我们将其称之为内置函数,这些内置函数都是很有用也是最常用的,下面的表格列出了一部分的内置函数。
| 函数 | 说明 |
|---|---|
abs |
返回一个数的绝对值,例如:abs(-1.3)会返回1.3。 |
bin |
把一个整数转换成以'0b'开头的二进制字符串,例如:bin(123)会返回'0b1111011'。 |
chr |
将Unicode编码转换成对应的字符,例如:chr(8364)会返回'€'。 |
hex |
将一个整数转换成以'0x'开头的十六进制字符串,例如:hex(123)会返回'0x7b'。 |
input |
从输入中读取一行,返回读到的字符串。 |
len |
获取字符串、列表等的长度。 |
max |
返回多个参数或一个可迭代对象(后面会讲)中的最大值,例如:max(12, 95, 37)会返回95。 |
min |
返回多个参数或一个可迭代对象(后面会讲)中的最小值,例如:min(12, 95, 37)会返回12。 |
oct |
把一个整数转换成以'0o'开头的八进制字符串,例如:oct(123)会返回'0o173'。 |
open |
打开一个文件并返回文件对象(后面会讲)。 |
ord |
将字符转换成对应的Unicode编码,例如:ord('€')会返回8364。 |
pow |
求幂运算,例如:pow(2, 3)会返回8;pow(2, 0.5)会返回1.4142135623730951。 |
print |
打印输出。 |
range |
构造一个范围序列,例如:range(100)会产生0到99的整数序列。 |
round |
按照指定的精度对数值进行四舍五入,例如:round(1.23456, 4)会返回1.2346。 |
sum |
对一个序列中的项从左到右进行求和运算,例如:sum(range(1, 101))会返回5050。 |
type |
返回对象的类型,例如:type(10)会返回int;而 type('hello')会返回str。 |
变量的作用域
最后,我们来讨论一下Python中有关变量作用域的问题。
|
|
上面的代码能够顺利的执行并且打印出100、hello和True,但我们注意到了,在bar函数的内部并没有定义a和b两个变量,那么a和b是从哪里来的。我们在上面代码的if分支中定义了一个变量a,这是一个全局变量(global variable),属于全局作用域,因为它没有定义在任何一个函数中。在上面的foo函数中我们定义了变量b,这是一个定义在函数中的局部变量(local variable),属于局部作用域,在foo函数的外部并不能访问到它;但对于foo函数内部的bar函数来说,变量b属于嵌套作用域,在bar函数中我们是可以访问到它的。bar函数中的变量c属于局部作用域,在bar函数之外是无法访问的。事实上,Python查找一个变量时会按照“局部作用域”、“嵌套作用域”、“全局作用域”和“内置作用域”的顺序进行搜索,前三者我们在上面的代码中已经看到了,所谓的“内置作用域”就是Python内置的那些标识符,我们之前用过的input、print、int等都属于内置作用域。
再看看下面这段代码,我们希望通过函数调用修改全局变量a的值,但实际上下面的代码是做不到的。
|
|
在调用foo函数后,我们发现a的值仍然是100,这是因为当我们在函数foo中写a = 200的时候,是重新定义了一个名字为a的局部变量,它跟全局作用域的a并不是同一个变量,因为局部作用域中有了自己的变量a,因此foo函数不再搜索全局作用域中的a。如果我们希望在foo函数中修改全局作用域中的a,代码如下所示。
|
|
我们可以使用global关键字来指示foo函数中的变量a来自于全局作用域,如果全局作用域中没有a,那么下面一行的代码就会定义变量a并将其置于全局作用域。同理,如果我们希望函数内部的函数能够修改嵌套作用域中的变量,可以使用nonlocal关键字来指示变量来自于嵌套作用域,请大家自行试验。
在实际开发中,我们应该尽量减少对全局变量的使用,因为全局变量的作用域和影响过于广泛,可能会发生意料之外的修改和使用,除此之外全局变量比局部变量拥有更长的生命周期,可能导致对象占用的内存长时间无法被垃圾回收。事实上,减少对全局变量的使用,也是降低代码之间耦合度的一个重要举措,同时也是对迪米特法则的践行。减少全局变量的使用就意味着我们应该尽量让变量的作用域在函数的内部,但是如果我们希望将一个局部变量的生命周期延长,使其在定义它的函数调用结束后依然可以使用它的值,这时候就需要使用闭包,这个我们在后续的内容中进行讲解。
说明: 很多人经常会将“闭包”和“匿名函数”混为一谈,但实际上它们并不是一回事,如果想了解这个概念,可以看看维基百科的解释或者知乎上对这个概念的讨论。
说了那么多,其实结论很简单,从现在开始我们可以将Python代码按照下面的格式进行书写,这一点点的改进其实就是在我们理解了函数和作用域的基础上跨出的巨大的一步。
|
|
Author kong
LastMod 2021-07-08