文件读写和异常处理
Contents
实际开发中常常会遇到对数据进行持久化的场景,所谓持久化是指将数据从无法长久保存数据的存储介质(通常是内存)转移到可以长久保存数据的存储介质(通常是硬盘)中。实现数据持久化最直接简单的方式就是通过文件系统将数据保存到文件中。
计算机的文件系统是一种存储和组织计算机数据的方法,它使得对数据的访问和查找变得容易,文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘、光盘、闪存等物理设备的数据块概念,用户使用文件系统来保存数据时,不必关心数据实际保存在硬盘的哪个数据块上,只需要记住这个文件的路径和文件名。在写入新数据之前,用户不必关心硬盘上的哪个数据块没有被使用,硬盘上的存储空间管理(分配和释放)功能由文件系统自动完成,用户只需要记住数据被写入到了哪个文件中。
打开和关闭文件
有了文件系统,我们可以非常方便的通过文件来读写数据;在Python中要实现文件操作是非常简单的。我们可以使用Python内置的open函数来打开文件,在使用open函数时,我们可以通过函数的参数指定文件名、操作模式和字符编码等信息,接下来就可以对文件进行读写操作了。这里所说的操作模式是指要打开什么样的文件(字符文件或二进制文件)以及做什么样的操作(读、写或追加),具体如下表所示。
| 操作模式 | 具体含义 |
|---|---|
'r' |
读取 (默认) |
'w' |
写入(会先截断之前的内容) |
'x' |
写入,如果文件已经存在会产生异常 |
'a' |
追加,将内容写入到已有文件的末尾 |
'b' |
二进制模式 |
't' |
文本模式(默认) |
'+' |
更新(既可以读又可以写) |
下图展示了如何根据程序的需要来设置open函数的操作模式。
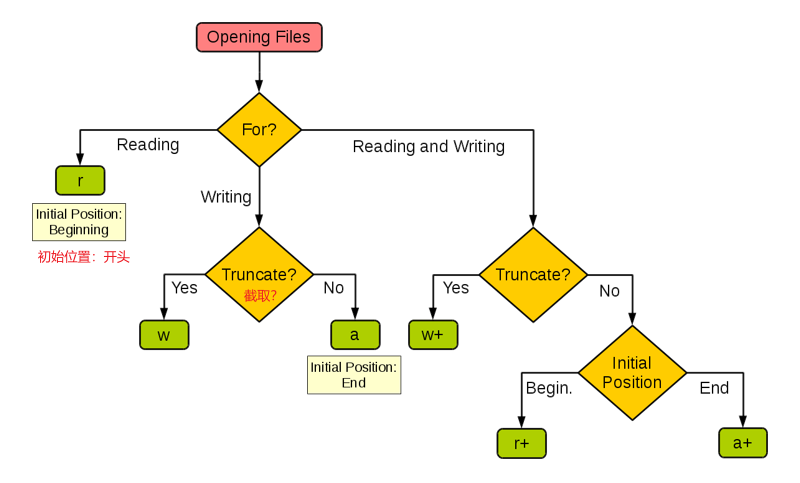
在使用open函数时,如果打开的文件是字符文件(文本文件),可以通过encoding参数来指定读写文件使用的字符编码。如果对字符编码和字符集这些概念不了解,可以看看《字符集和字符编码》一文,此处不再进行赘述。如果没有指定该参数,则使用系统默认的编码作为读写文件的编码。当前系统默认的编码可以通过下面的代码获得。
|
|
使用open函数打开文件成功后会返回一个文件对象,通过这个对象,我们就可以实现对文件的读写操作;如果打开文件失败,open函数会引发异常,稍后会对此加以说明。如果要关闭打开的文件,可以使用文件对象的close方法,这样可以在结束文件操作时释放掉这个文件。
读写文本文件
用open函数打开文本文件时,需要指定文件名并将文件的操作模式设置为'r',如果不指定,默认值也是'r';如果需要指定字符编码,可以传入encoding参数,如果不指定,默认值是None,那么在读取文件时使用的是操作系统默认的编码。需要提醒大家,如果不能保证保存文件时使用的编码方式与encoding参数指定的编码方式是一致的,那么就可能因无法解码字符而导致读取文件失败。
下面的例子演示了如何读取一个纯文本文件(一般指只有字符原生编码构成的文件,与富文本相比,纯文本不包含字符样式的控制元素,能够被最简单的文本编辑器直接读取)。
|
|
除了使用文件对象的read方法读取文件之外,还可以使用for-in循环逐行读取或者用readlines方法将文件按行读取到一个列表容器中,代码如下所示。
|
|
要将文本信息写入文件文件也非常简单,在使用open函数时指定好文件名并将文件模式设置为'w'即可。注意如果需要对文件内容进行追加式写入,应该将模式设置为'a'。如果要写入的文件不存在会自动创建文件而不是引发异常。
|
|
也可以使用下面的代码来完成相同的操作。
|
|
下面的例子演示了如何将1-9999之间的素数分别写入三个文件中(1-99之间的素数保存在a.txt中,100-999之间的素数保存在b.txt中,1000-9999之间的素数保存在c.txt中)。
|
|
异常处理机制
请注意上面的代码,如果open函数指定的文件并不存在或者无法打开,那么将引发异常状况导致程序崩溃。为了让代码具有健壮性和容错性,我们可以使用Python的异常机制对可能在运行时发生状况的代码进行适当的处理。Python中和异常相关的关键字有五个,分别是try、except、else、finally和raise,我们先看看下面的代码,再来为大家介绍这些关键字的用法。
|
|
在Python中,我们可以将运行时会出现状况的代码放在try代码块中,在try后面可以跟上一个或多个except块来捕获异常并进行相应的处理。例如,在上面的代码中,文件找不到会引发FileNotFoundError,指定了未知的编码会引发LookupError,而如果读取文件时无法按指定编码方式解码文件会引发UnicodeDecodeError,所以我们在try后面跟上了三个except分别处理这三种不同的异常状况。在except后面,我们还可以加上else代码块,这是try 中的代码没有出现异常时会执行的代码,而且else中的代码不会再进行异常捕获,也就是说如果遇到异常状况,程序会因异常而终止并报告异常信息。最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源。由于finally块的代码不论程序正常还是异常都会执行,甚至是调用了sys模块的exit函数终止Python程序,finally块中的代码仍然会被执行(因为exit函数的本质是引发了SystemExit异常),因此我们把finally代码块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。
Python中内置了大量的异常类型,除了上面代码中用到的异常类型以及之前的课程中遇到过的异常类型外,还有许多的异常类型,其继承结构如下所示。
|
|
从上面的继承结构可以看出,Python中所有的异常都是BaseException的子类型,它有四个直接的子类,分别是:SystemExit、KeyboardInterrupt、GeneratorExit和Exception。其中,SystemExit表示解释器请求退出,KeyboardInterrupt是用户中断程序执行(按下Ctrl+c),GeneratorExit表示生成器发生异常通知退出。值得一提的是Exception类,它是常规异常类型的父类型,很多的异常都是直接或间接的继承自Exception类。如果Python内置的异常类型不能满足应用程序的需要,我们可以自定义异常类型,而自定义的异常类型也应该直接或间接继承自Exception类,当然还可以根据需要重写或添加方法。
在Python中,可以使用raise关键字来引发异常(抛出异常对象),而调用者可以通过try...except...结构来捕获并处理异常。例如在函数中,当函数的执行条件不满足时,可以使用抛出异常的方式来告知调用者问题的所在,而调用者可以通过捕获处理异常来使得代码从异常中恢复,定义异常和抛出异常的代码如下所示。
|
|
调用求阶乘的函数fac,通过try...except...结构捕获输入错误的异常并打印异常对象(显示异常信息),如果输入正确就计算阶乘并结束程序。
|
|
上下文语法
对于open函数返回的文件对象,还可以使用with上下文语法在文件操作完成后自动执行文件对象的close方法,这样可以让代码变得更加简单,因为不需要再写finally代码块来执行关闭文件释放资源的操作。需要提醒大家的是,并不是所有的对象都可以放在with上下文语法中,只有符合上下文管理器协议(有__enter__和__exit__魔术方法)的对象才能使用这种语法,Python标准库中的contextlib模块也提供了对with上下文语法的支持,后面再为大家进行讲解。
|
|
读写二进制文件
读写二进制文件跟读写文本文件的操作类似,但是需要注意,在使用open函数打开文件时,如果要进行读操作,操作模式是'rb',如果要进行写操作,操作模式是'wb'。还有一点,读写文本文件时,read方法的返回值以及write方法的参数是str对象(字符串),而读写二进制文件时,read方法的返回值以及write方法的参数是bytes-like对象(字节串)。下面的代码实现了将当前路径下名为kkk.jpg的图片文件复制到hhh.jpg文件中的操作。
|
|
如果要复制的图片文件很大,一次将文件内容直接读入内存中可能会造成非常大的内存开销,为了减少对内存的占用,可以为read方法传入size参数来指定每次读取的字节数,通过循环读取和写入的方式来完成上面的操作,代码如下所示。
|
|
读写JSON文件
通过上面的讲解,我们已经知道如何将文本数据和二进制数据保存到文件中,那么这里还有一个问题,如果希望把一个列表或者一个字典中的数据保存到文件中又该怎么做呢?答案是将数据以JSON格式进行保存。JSON是“JavaScript Object Notation”的缩写,它本来是JavaScript语言中创建对象的一种字面量语法,现在已经被广泛的应用于跨平台跨语言的数据交换,原因很简单,因为JSON也是纯文本,任何系统任何编程语言处理纯文本都是没有问题的。目前JSON基本上已经取代了XML作为异构系统间交换数据的事实标准。关于JSON的知识,更多的可以参考JSON的官方网站,从这个网站也可以了解到每种语言处理JSON数据格式可以使用的工具或三方库,下面是一个JSON的简单例子。
|
|
可能大家已经注意到了,上面的JSON跟Python中的字典其实是一样一样的,事实上JSON的数据类型和Python的数据类型是很容易找到对应关系的,如下面两张表所示。
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int / real) | int / float |
| true / false | True / False |
| null | None |
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True / False | true / false |
| None | null |
我们使用Python中的json模块就可以将字典或列表以JSON格式保存到文件中,代码如下所示。
|
|
json模块主要有四个比较重要的函数,分别是:
dump- 将Python对象按照JSON格式序列化到文件中dumps- 将Python对象处理成JSON格式的字符串load- 将文件中的JSON数据反序列化成对象loads- 将字符串的内容反序列化成Python对象
这里出现了两个概念,一个叫序列化,一个叫反序列化。“序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换为可以存储或传输的形式,这样在需要的时候能够恢复到原先的状态,而且通过序列化的数据重新获取字节时,可以利用这些字节来产生原始对象的副本(拷贝)。与这个过程相反的动作,即从一系列字节中提取数据结构的操作,就是反序列化(deserialization)”。
我们可以通过下面的代码,从上面创建的data.json文件中读取JSON格式的数据并还原成字典。
|
|
目前绝大多数网络数据服务(或称之为网络API)都是基于HTTP协议提供JSON格式的数据,关于HTTP协议的相关知识,可以看看阮一峰老师的《HTTP协议入门》,如果想了解国内的网络数据服务,可以看看聚合数据和阿凡达数据等网站,国外的可以看看{API}Search网站。下面的例子演示了如何使用requests模块(封装得足够好的第三方网络访问模块)访问网络API获取国内新闻,如何通过json模块解析JSON数据并显示新闻标题,这个例子使用了天行数据提供的国内新闻数据接口,其中的APIKey需要自己到该网站申请。
安装requests库。
|
|
获取国内新闻并显示新闻标题和链接。
|
|
注意:上面代码中的APIKey需要换成自己在天行数据网站申请的APIKey,同时还要申请开通国内新闻的接口才能获取到JSON格式的数据。这个网站上还有很多非常有意思的网络API接口,例如:垃圾分类、美女图片、周公解梦等等,大家可以仿照上面的代码来调用这些接口。
在Python中要实现序列化和反序列化除了使用json模块之外,还可以使用pickle和shelve模块,但是这两个模块是使用特有的序列化协议来序列化数据,因此序列化后的数据只能被Python识别。关于这两个模块的相关知识可以自己看看网络上的资料。另外,如果要了解更多的关于Python异常机制的知识,可以看看segmentfault上面的文章《总结:Python中的异常处理》,这篇文章不仅介绍了Python中异常机制的使用,还总结了一系列的最佳实践,很值得一读。
读写csv文件
CSV(Comma Separated Values)全称逗号分隔值文件是一种简单、通用的文件格式,被广泛的应用于应用程序(数据库、电子表格等)数据的导入和导出以及异构系统之间的数据交换。因为CSV是纯文本文件,不管是什么操作系统和编程语言都是可以处理纯文本的,而且很多编程语言中都提供了对读写CSV文件的支持,因此CSV格式在数据处理和数据科学中被广泛应用。
CSV文件有以下特点:
- 纯文本,使用某种字符集(如ASCII、Unicode、GB2312等);
- 由一条条的记录组成(典型的是每行一条记录);
- 每条记录被分隔符(如逗号、分号、制表符等)分隔为字段(列);
- 每条记录都有同样的字段序列。
CSV文件可以使用文本编辑器或类似于Excel电子表格这类工具打开和编辑,当使用Excel这类电子表格打开CSV文件时,你甚至感觉不到CSV和Excel文件的区别。很多数据库系统都支持将数据导出到CSV文件中,当然也支持从CSV文件中读入数据保存到数据库中。csv是最通用的一种文件格式,它可以非常容易地被导入各种PC表格及数据库中。此文件,一行即为数据表的一行。生成数据表字段用半角逗号隔开。csv文件用记事本和excel都能打开,用记事本打开显示逗号,用excel打开,没有逗号了,逗号都用来分列了,还可有Editplus打开。
将数据写入CSV文件
现有五个学生三门课程的考试成绩需要保存到一个CSV文件中,要达成这个目标,可以使用Python标准库中的csv模块,该模块的writer函数会返回一个csvwriter对象,通过该对象的writerow或writerows方法就可以将数据写入到CSV文件中,具体的代码如下所示。
|
|
需要说明的是上面的writer函数,该函数除了传入要写入数据的文件对象外,还可以dialect参数,它表示CSV文件的方言,默认值是excel。除此之外,还可以通过delimiter、quotechar、quoting参数来指定分隔符(默认是逗号)、包围值的字符(默认是双引号)以及包围的方式。其中,包围值的字符主要用于当字段中有特殊符号时,通过添加包围值的字符可以避免二义性。大家可以尝试将上面第5行代码修改为下面的代码,看看生成的CSV文件到底有什么区别。
|
|
从CSV文件读取数据
如果要读取刚才创建的CSV文件,可以使用下面的代码,通过csv模块的reader函数可以创建出csvreader对象,该对象是一个迭代器,可以通过next函数或for-in循环读取到文件中的数据。
|
|
注意:上面的代码对
csvreader对象做for循环时,每次会取出一个列表对象,该列表对象包含了一行中所有的字段。
|
|
|
|
简单的总结
通过读写文件的操作,我们可以实现数据持久化。在Python中可以通过open函数来获得文件对象,可以通过文件对象的read和write方法实现文件读写操作。程序在运行时可能遭遇无法预料的异常状况,可以使用Python的异常机制来处理这些状况。Python的异常机制主要包括try、except、else、finally和raise这五个核心关键字。try后面的except语句不是必须的,finally语句也不是必须的,但是二者必须要有一个;except语句可以有一个或多个,多个except会按照书写的顺序依次匹配指定的异常,如果异常已经处理就不会再进入后续的except语句;except语句中还可以通过元组同时指定多个异常类型进行捕获;except语句后面如果不指定异常类型,则默认捕获所有异常;捕获异常后可以使用raise要再次抛出,但是不建议捕获并抛出同一个异常;不建议在不清楚逻辑的情况下捕获所有异常,这可能会掩盖程序中严重的问题。最后强调一点,不要使用异常机制来处理正常业务逻辑或控制程序流程,简单的说就是不要滥用异常机制。
Author kong
LastMod 2021-07-27