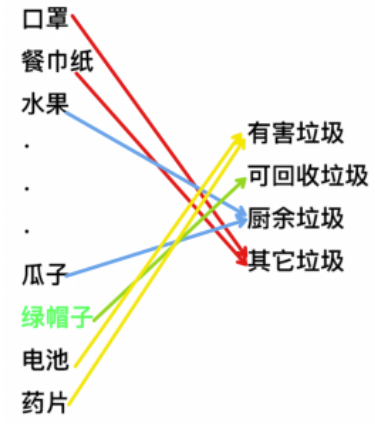
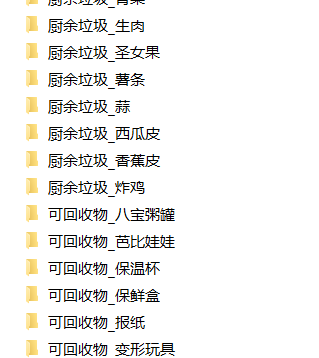
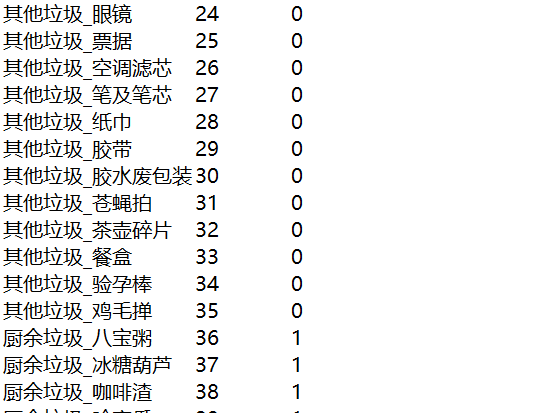
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
|
from dataset import Garbage_Loader
from torch.utils.data import DataLoader
from torchvision import models
import torch.nn as nn
import torch.optim as optim
import torch
import time
import os
import shutil
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
"""
Author : Jack Cui
Wechat : https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA
"""
from tensorboardX import SummaryWriter
def accuracy(output, target, topk=(1,)):
"""
计算topk的准确率
"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
class_to = pred[0].cpu().numpy()
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res, class_to
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
"""
根据 is_best 存模型,一般保存 valid acc 最好的模型
"""
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, 'model_best_' + filename)
def train(train_loader, model, criterion, optimizer, epoch, writer):
"""
训练代码
参数:
train_loader - 训练集的 DataLoader
model - 模型
criterion - 损失函数
optimizer - 优化器
epoch - 进行第几个 epoch
writer - 用于写 tensorboardX
"""
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
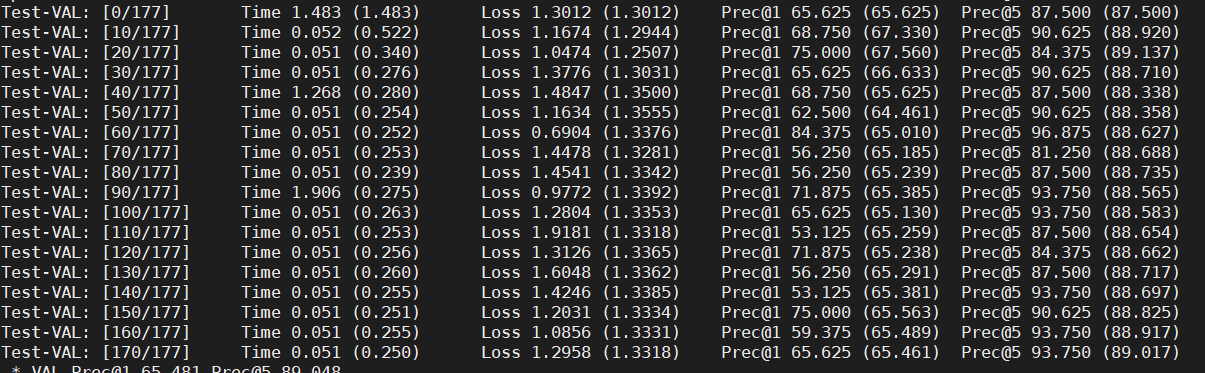
if i % 10 == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5))
writer.add_scalar('loss/train_loss', losses.val, global_step=epoch)
def validate(val_loader, model, criterion, epoch, writer, phase="VAL"):
"""
验证代码
参数:
val_loader - 验证集的 DataLoader
model - 模型
criterion - 损失函数
epoch - 进行第几个 epoch
writer - 用于写 tensorboardX
"""
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Test-{0}: [{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
phase, i, len(val_loader),
batch_time=batch_time,
loss=losses,
top1=top1, top5=top5))
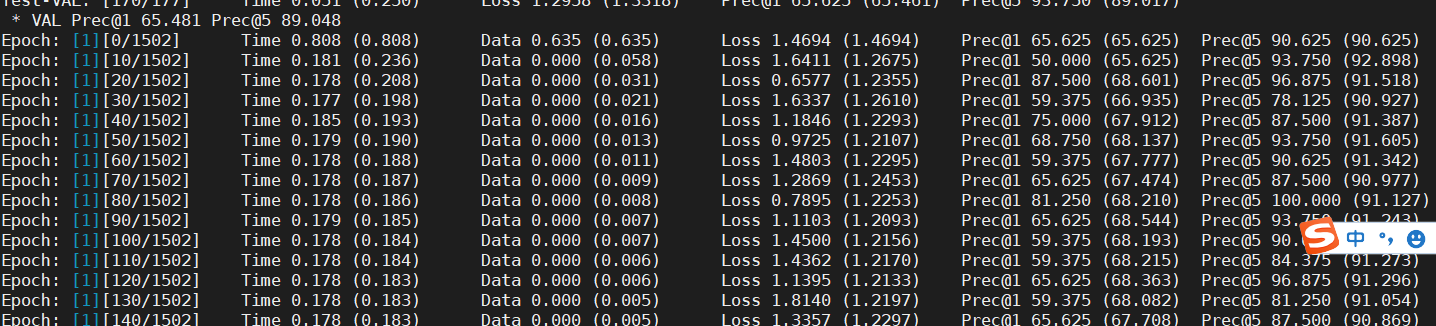
print(' * {} Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}'
.format(phase, top1=top1, top5=top5))
writer.add_scalar('loss/valid_loss', losses.val, global_step=epoch)
return top1.avg, top5.avg
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
if __name__ == "__main__":
# -------------------------------------------- step 1/4 : 加载数据 ---------------------------
train_dir_list = 'train.txt'
valid_dir_list = 'val.txt'
batch_size = 64
epochs = 80
num_classes = 214
train_data = Garbage_Loader(train_dir_list, train_flag=True)
valid_data = Garbage_Loader(valid_dir_list, train_flag=False)
train_loader = DataLoader(dataset=train_data, num_workers=8, pin_memory=True, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, num_workers=8, pin_memory=True, batch_size=batch_size)
train_data_size = len(train_data)
print('训练集数量:%d' % train_data_size)
valid_data_size = len(valid_data)
print('验证集数量:%d' % valid_data_size)
# ------------------------------------ step 2/4 : 定义网络 ------------------------------------
model = models.resnet50(pretrained=True)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, num_classes)
model = model.cuda()
# ------------------------------------ step 3/4 : 定义损失函数和优化器等 -------------------------
lr_init = 0.0001
lr_stepsize = 20
weight_decay = 0.001
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.Adam(model.parameters(), lr=lr_init, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_stepsize, gamma=0.1)
writer = SummaryWriter('runs/resnet50')
# ------------------------------------ step 4/4 : 训练 -----------------------------------------
best_prec1 = 0
for epoch in range(epochs):
scheduler.step()
train(train_loader, model, criterion, optimizer, epoch, writer)
# 在验证集上测试效果
valid_prec1, valid_prec5 = validate(valid_loader, model, criterion, epoch, writer, phase="VAL")
is_best = valid_prec1 > best_prec1
best_prec1 = max(valid_prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'arch': 'resnet50',
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer' : optimizer.state_dict(),
}, is_best,
filename='checkpoint_resnet50.pth.tar')
writer.close()
|