语义分割实战
Contents
语义分割基础与环境搭建
语义分割
语义分割(semantic segmentation) : 就是按照“语义”给图像上目标类别中的每一点打一个标签,使得不同种类的东西在图像上被区分开来。可以理解成像素级别的分类任务,直白点,就是对每个像素点进行分类。
简而言之,我们的目标是给定一幅RGB彩色图像(高x宽x3)或一幅灰度图像(高x宽x1),输出一个分割图谱,其中包括每个像素的类别标注(高x宽x1)。具体如下图所示:
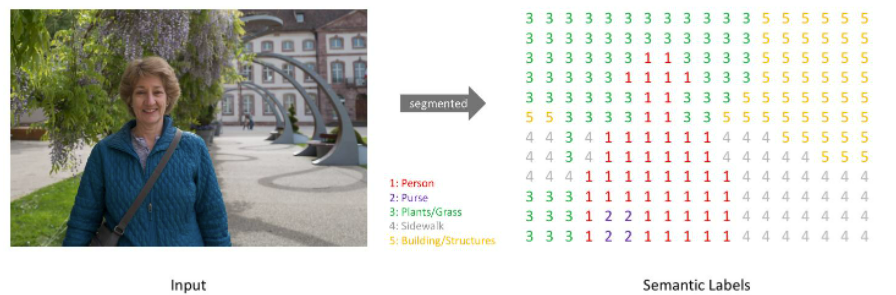
注意:为了视觉上清晰,上面的预测图是一个低分辨率的图。在实际应用中,分割标注的分辨率需要与原始图像的分辨率相同。
这里对图片分为五类:Person(人)、Purse(包)、Plants/Grass(植物/草)、Sidewalk(人行道)、Building/Structures(建筑物)。
与标准分类值(standard categorical values)的做法相似,这里也是创建一个one-hot编码的目标类别标注——本质上即为每个类别创建一个输出通道。因为上图有5个类别,所以网络输出的通道数也为5,如下图所示:
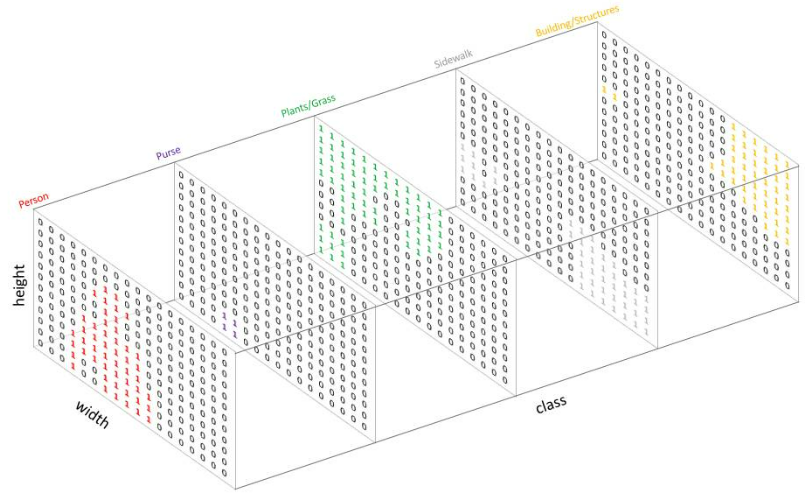
如上图所示,预测的结果可以通过对每个像素在深度上求argmax的方式被整合到一张分割图中。进而,我们可以轻松地通过重叠的方式观察到每个目标。
argmax的方式也很好理解。如上图所示,每个通道只有0或1,以Person的通道为例,红色的1表示为Person的像素,其他像素均为0。其他通道也是如此,并且不存在同一个像素点在两个以上的通道均为1的情况。因此,通过argmax就找到每个像素点的最大索引通道值。最终得到结果为:
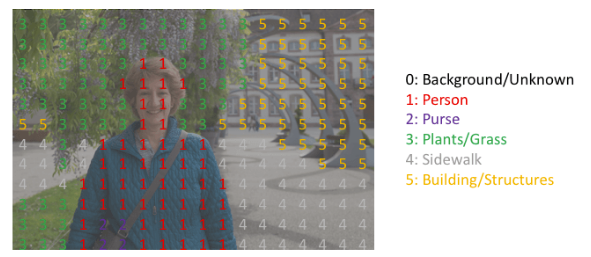
当只有一层通道被重叠至原始图像时,我们称之为mask,即只指示某一特定类别所存在的区域。
高分辨率的结果如下图所示,不同的颜色代表不同的类别:

数据集
第一个常用的数据集是Pascal VOC系列。这个系列中目前较流行的是VOC2012,Pascal Context等类似的数据集也有用到。
第二个常用的数据集是Microsoft COCO。COCO一共有80个类别,虽然有很详细的像素级别的标注,但是官方没有专门对语义分割的评测。这个数据集主要用于实例级别的分割以及图片描述。所以COCO数据集往往被当成是额外的训练数据集用于模型的训练。
第三个数据集是辅助驾驶(自动驾驶)环境的Cityscapes,使用比较常见的19个类别用于评测。
可以用于语义分割训练的数据集有很多:
- Pascal Voc 2012:比较常见的物体分类,共21个类别;
- MS COCO:由微软赞助,几乎成为了图像语义理解算法性能评价的“标准”数据集,共80个类别;
- Cityscapes:包含50个欧洲城市不同场景、不同背景、不同季节的街景的33类标注物体;
- Pascal-Context:对于PASCAL-VOC 2010识别竞赛的扩展,共59个类别;
- KITTI:用于移动机器人及自动驾驶研究的最受欢迎的数据集之一,共11个类别;
- NYUDv2:2.5维数据集,它包含1449张由微软Kinect设备捕获的室内的RGB-D图像;
- SUN-RGBD:由四个RGB-D传感器得来,包含10000张RGB-D图像,尺寸与PASCAL VOC一致;
- ADE20K_MIT:一个场景理解的新的数据集,这个数据集是可以免费下载的,共151个类别。
开发环境搭建
-
CUDA
-
Anaconda3
-
cuDNN和Pytorch安装
cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。
UNet语义分割网络
UNet网络结构
在语义分割领域,基于深度学习的语义分割算法开山之作是FCN(Fully Convolutional Networks for Semantic Segmentation),而UNet是遵循FCN的原理,并进行了相应的改进,使其适应小样本的简单分割问题。
研究一个深度学习算法,可以先看网络结构,看懂网络结构后,再Loss计算方法、训练方法等。本文主要针对UNet的网络结构进行讲解,其它内容会在后续章节进行说明。
原理
UNet成为了大多做医疗影像语义分割任务的baseline。
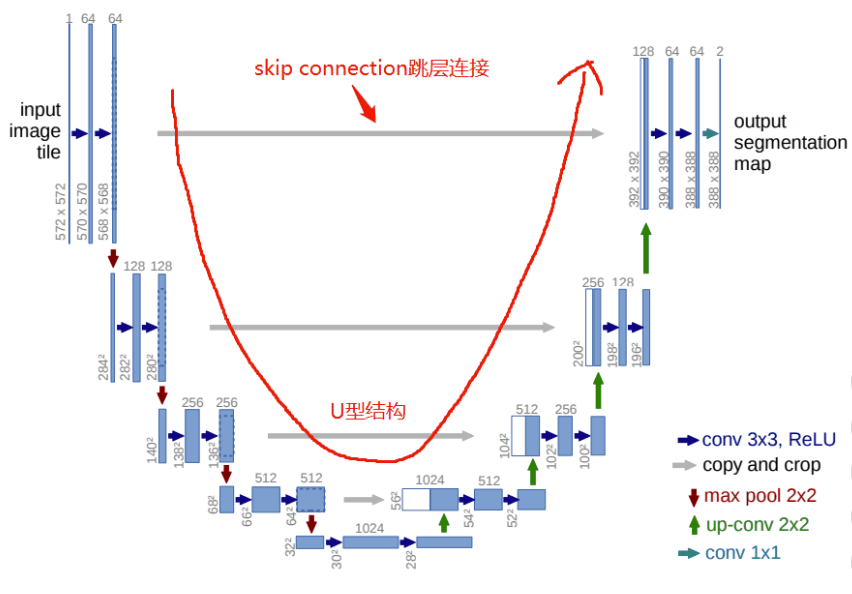
UNet网络结构,最主要的两个特点是:U型网络结构和Skip Connection跳层连接。
-
UNet是一个对称的网络结构,左侧为下采样,右侧为上采样。
-
按照功能可以将左侧的一系列下采样操作称为encoder,将右侧的一系列上采样操作称为decoder。
-
Skip Connection中间四条灰色的平行线,Skip Connection就是在上采样的过程中,融合下采样过过程中的feature map。
-
Skip Connection用到的融合的操作也很简单,就是将feature map的通道进行叠加,俗称Concat。
-
Concat操作也很好理解,举个例子:一本大小为
10cm*10cm,厚度为3cm的书A,和一本大小为10cm*10cm,厚度为4cm的书B。将书A和书B,边缘对齐地摞在一起。这样就得到了,大小为10cm*10cm厚度为7cm的一摞书,类似这种“摞在一起”的操作,就是Concat。
-
同样道理,对于feature map,一个大小为
256*256*64的feature map,即feature map的w(宽)为256,h(高)为256,c(通道数)为64。和一个大小为256*256*32的feature map进行Concat融合,就会得到一个大小为256*256*96的feature map。
在实际使用中,Concat融合的两个feature map的大小不一定相同,例如256*256*64的feature map和240*240*32的feature map进行Concat。
- 将大
256*256*64的feature map进行裁剪,裁剪为240*240*64的feature map,比如上下左右,各舍弃8 pixel,裁剪后再进行Concat,得到240*240*96的feature map。 - 将小
240*240*32的feature map进行padding操作,padding为256*256*32的feature map,比如上下左右,各补8 pixel,padding后再进行Concat,得到256*256*96的feature map。 - UNet采用的Concat方案就是第二种,将小的feature map进行padding,padding的方式是补0,一种常规的常量填充。
代码
我们将整个UNet网络拆分为多个模块进行讲解。
- DoubleConv模块:
连续两次的卷积操作。
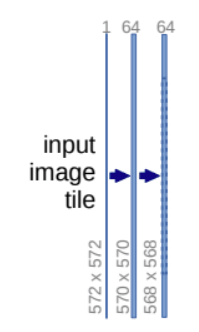
从UNet网络中可以看出,不管是下采样过程还是上采样过程,每一层都会连续进行两次卷积操作,这种操作在UNet网络中重复很多次,可以单独写一个DoubleConv模块:
|
|
如上图所示的网络,in_channels设为1,out_channels为64。输入图片大小为572*572,经过步长为1,padding为0的3*3卷积,得到570*570的feature map,再经过一次卷积得到568*568的feature map。
计算公式:O=(H−F+2×P)/S+1
H为输入feature map的大小,O为输出feature map的大小,F为卷积核的大小,P为padding的大小,S为步长。
- Down模块:
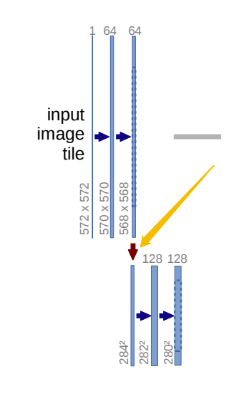
UNet网络一共有4次下采样过程,模块化代码如下:
|
|
这里的代码很简单,就是一个maxpool池化层,进行下采样,然后接一个DoubleConv模块。
- Up模块:
上采样过程用到的最多的当然就是上采样了,除了常规的上采样操作,还有进行特征的融合。
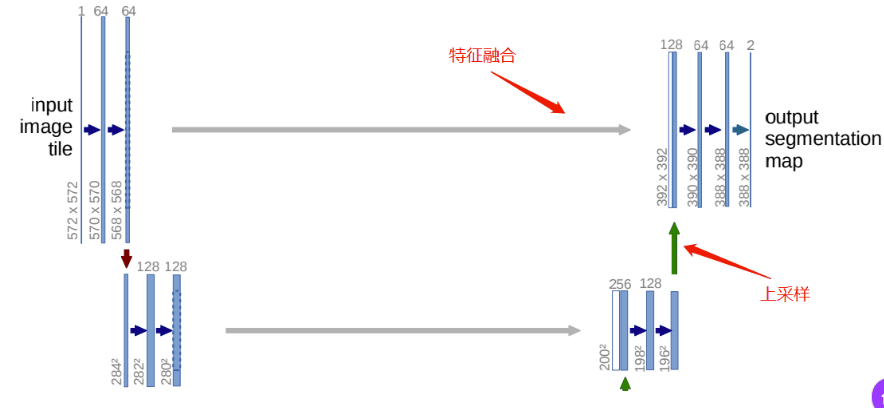
|
|
上采样,定义了两种方法:Upsample和ConvTranspose2d,也就是双线性插值和反卷积。
双线性插值:
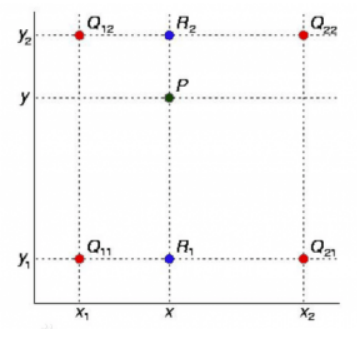
简单地讲:已知Q11、Q12、Q21、Q22四个点坐标,通过Q11和Q21求R1,再通过Q12和Q22求R2,最后通过R1和R2求P,这个过程就是双线性插值。
对于一个feature map而言,其实就是在像素点中间补点,补的点的值是多少,是由相邻像素点的值决定的。
反卷积,顾名思义,就是反着卷积。卷积是让featuer map越来越小,反卷积就是让feature map越来越大,示意图:
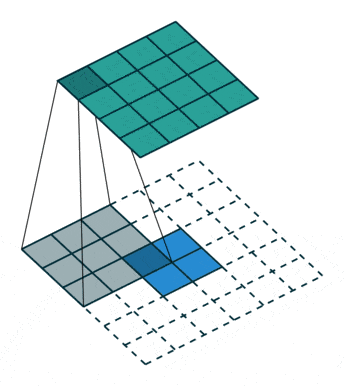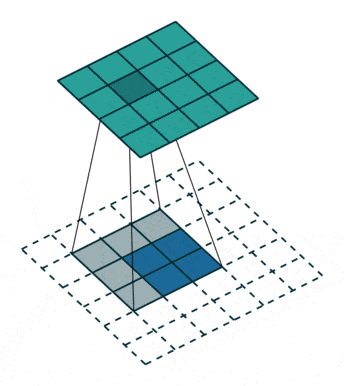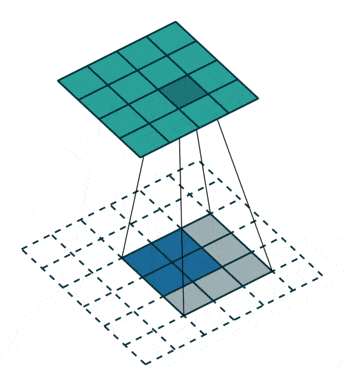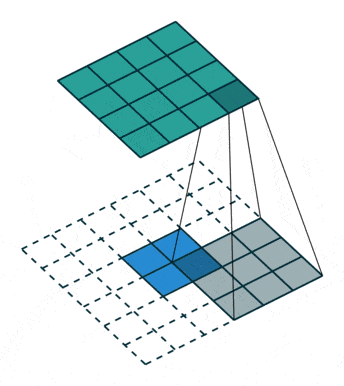
下面蓝色为原始图片,周围白色的虚线方块为padding结果,通常为0,上面绿色为卷积后的图片。
这个示意图,就是一个从2*2的feature map->4*4的feature map过程。
在forward前向传播函数中,x1接收的是上采样的数据,x2接收的是特征融合的数据。特征融合方法就是,上文提到的,先对小的feature map进行padding,再进行concat。
- OutConv模块:
用上述的DoubleConv模块、Down模块、Up模块就可以拼出UNet的主体网络结构了。UNet网络的输出需要根据分割数量,整合输出通道,结果如下图所示:
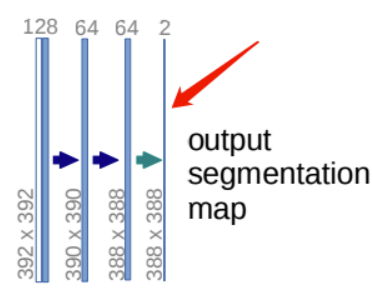
至此,UNet网络用到的模块都已经写好,我们可以将上述的模块代码都放到一个unet_parts.py文件里,然后再创建unet_model.py,根据UNet网络结构,设置每个模块的输入输出通道个数以及调用顺序,编写如下代码:
|
|
使用命令python unet_model.py,如果没有错误,你会得到如下结果:
|
|
UNet模型训练
深度学习算法,无非就是我们解决一个问题的方法。选择什么样的网络去训练,进行什么样的预处理,采用什么Loss和优化方法,都是根据具体的任务而定的。
UNet 论文中的经典任务:医学图像分割。
简单描述一个这个任务:如动图所示,给一张细胞结构图,我们要把每个细胞互相分割开来。
这个训练数据只有30张,分辨率为512x512,这些图片是果蝇的电镜图。
UNet训练
想要训练一个深度学习模型,可以简单分为三个步骤:
- 数据加载:数据怎么加载,标签怎么定义,用什么数据增强方法,都是这一步进行。
- 模型选择:模型我们已经准备好了,就是该系列上篇文章讲到的 UNet 网络。
- 算法选择:算法选择也就是我们选什么 loss ,用什么优化算法。
每个步骤说的比较笼统,我们结合今天的医学图像分割任务,展开说明。
数据加载
这一步,可以做很多事情,说白了,无非就是图片怎么加载,标签怎么定义,为了增加算法的鲁棒性或者增加数据集,可以做一些数据增强的操作。
数据分为训练集和测试集,各30张,训练集有标签,测试集没有标签。
数据加载要做哪些处理,是根据任务和数据集而决定的,对于我们的分割任务,不用做太多处理,但由于数据量很少,仅30张,我们可以使用一些数据增强方法,来扩大我们的数据集。
Pytorch 给我们提供了一个方法,方便我们加载数据,我们可以使用这个框架,去加载我们的数据。看下伪代码:
|
|
这是一个标准的模板,我们就使用这个模板,来加载数据,定义标签,以及进行数据增强。
创建一个dataset.py文件,编写代码如下:
|
|
运行结果:
|
|
__init__函数是这个类的初始化函数,根据指定的图片路径,读取所有图片数据,存放到self.imgs_path列表中。
__len__函数可以返回数据的多少,这个类实例化后,通过len()函数调用。
__getitem__函数是数据获取函数,在这个函数里你可以写数据怎么读,怎么处理,并且可以一些数据预处理、数据增强都可以在这里进行。我这里的处理很简单,只是将图片读取,并处理成单通道图片。同时,因为 label 的图片像素点是0和255,因此需要除以255,变成0和1。同时,随机进行了数据增强。
augment函数是定义的数据增强函数,怎么处理都行,我这里只是进行了简单的旋转操作。
在这个类中,你不用进行一些打乱数据集的操作,也不用管怎么按照 batchsize 读取数据。因为实例化这个类后,我们可以用 torch.utils.data.DataLoader 方法指定 batchsize 的大小,决定是否打乱数据。
Pytorch 提供给给我们的 DataLoader 很强大,我们甚至可以指定使用多少个进程加载数据,数据是否加载到 CUDA 内存中等高级用法,本文不涉及,就不再展开讲解了。
模型选择
但是我们需要对网络进行微调,完全按照论文的结构,模型输出的尺寸会稍微小于图片输入的尺寸,如果使用论文的网络结构需要在结果输出后,做一个 resize 操作。为了省去这一步,我们可以修改网络,使网络的输出尺寸正好等于图片的输入尺寸。
创建unet_parts.py文件
|
|
创建unet_model.py文件
|
|
这样调整过后,网络的输出尺寸就与图片的输入尺寸相同了。
算法选择
选择什么 Loss 很重要,Loss 选择的好坏,都会影响算法拟合数据的效果。
选择什么 Loss 也是根据任务而决定的。我们今天的任务,只需要分割出细胞边缘,也就是一个很简单的二分类任务,所以我们可以使用 BCEWithLogitsLoss。
啥是 BCEWithLogitsLoss?BCEWithLogitsLoss 是 Pytorch 提供的用来计算二分类交叉熵的函数。
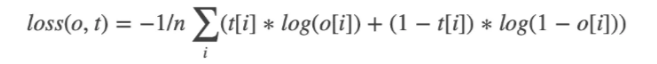
具体的公式推导,可以看我的机器学习系列教程《机器学习实战教程(六):Logistic回归基础篇之梯度上升算法》,这里就不再累述。
目标函数,也就是 Loss 确定好了,怎么去优化这个目标呢?
最简单的方法就是,我们耳熟能详的梯度下降算法,逐渐逼近局部的极值。但是这种简单的优化算法,求解速度慢。各种优化算法,本质上其实都是梯度下降,例如最常规的 SGD,就是基于梯度下降改进的随机梯度下降算法,Momentum 就是引入了动量的 SGD,以指数衰减的形式累计历史梯度。
除了这些最基本的优化算法,还有自适应参数的优化算法。这类算法最大的特点就是,每个参数有不同的学习率,在整个学习过程中自动适应这些学习率,从而达到更好的收敛效果。
本文就是选择了一种自适应的优化算法 RMSProp。RMSProp 是基于 AdaGrad 的改进。
|
|
预测
|
|

查看loss
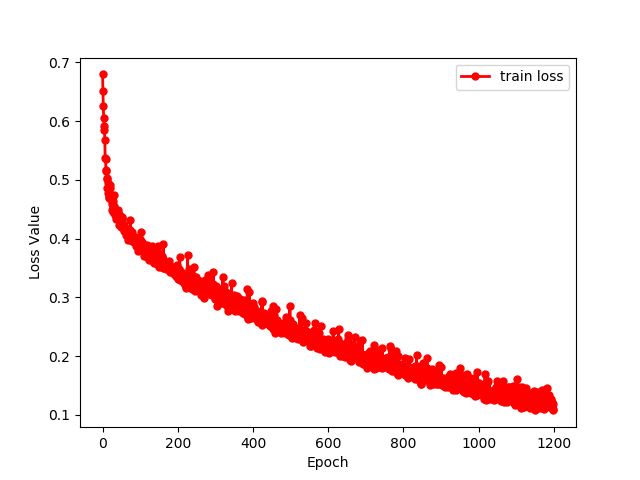
训练模型,最常看的指标就是 Loss。我们可以根据 Loss 的收敛情况,初步判断模型训练的好坏。
如果,Loss 值突然上升了,那说明训练有问题,需要检查数据和代码。
如果,Loss 值趋于稳定,那说明训练完毕了。
观察 Loss 情况,最直观的方法,就是绘制 Loss 曲线图。
sys.stdout
通过 Loss 曲线,我们可以分析模型训练的好坏,模型是否训练完成,起到一个很好的“监控”作用。
绘制 Loss 曲线图,第一步就是需要保存训练过程中的 Loss 值。
一个最简单的方法是使用,sys.stdout 标准输出重定向,简单好用。
|
|
代码很简单,创建一个 log.py 文件,自己写一个 Logger 类,并采用 sys.stdout 重定向输出。
在 Terminal 中,不仅可以使用 print 打印结果,同时也会将结果保存到 log.txt 文件中。
运行 log.py,打印 print 内容的同时,也将内容写入了 log.txt 文件中。
使用这个代码,就可以在打印 Loss 的同时,将结果保存到指定的 txt 中,比如保存上篇文章训练 UNet 的 Loss。
|
|
matplotlib
Matplotlib 是一个 Python 的绘图库,简单好用。
简单几行命令,就可以绘制曲线图、散点图、条形图、直方图、饼图等等。
在深度学习中,一般就是绘制曲线图,比如 Loss 曲线、Acc 曲线。
使用 sys.stdout 保存的 train_loss.txt,绘制 Loss 曲线。
|
|
Logging
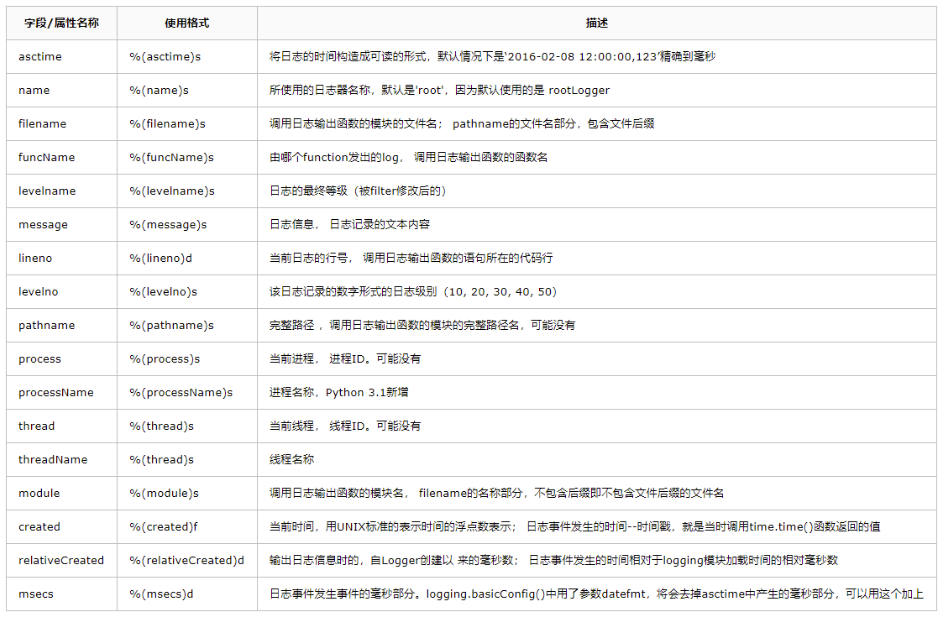
说到保存日志,那不得不提 Python 的内置标准模块 Logging,它主要用于输出运行日志,可以设置输出日志的等级、日志保存路径、日志文件回滚等,同时,我们也可以设置日志的输出格式。
|
|
只需要几行代码,进行一个简单的封装使用。使用函数 get_logger 创建一个级别为 info 的 logger,如果指定 log_file,则会对日志进行保存。

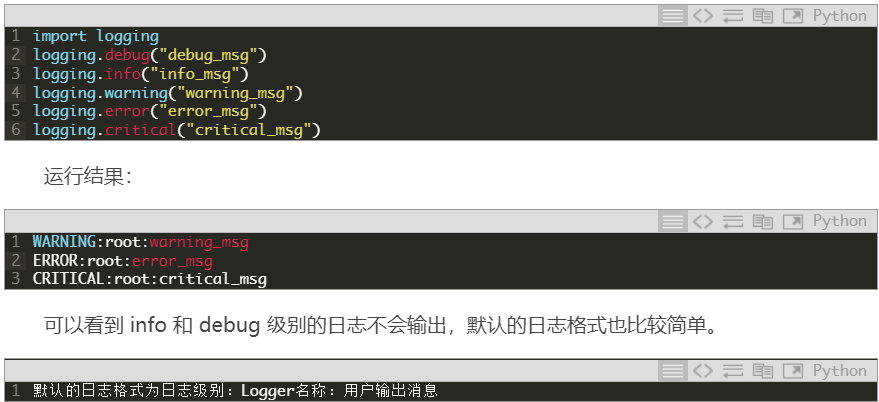
当然,我们可以通过,logging.basicConfig 的 format 参数,设置日志格式。
TensorboardX
TensorboardX ,它是专门用于深度学习“炼丹”的高级“法宝”。
在 Pytorch 中,这个可视化工具叫做 TensorBoardX,其实就是针对 Tensorboard 的一个封装,使得 PyTorch 用户也能够调用 Tensorboard。
TensorboardX 安装也非常简单,使用 pip 即可安装,需要注意的是 Pytorch 的版本需要大于 1.1.0。
|
|
|
|
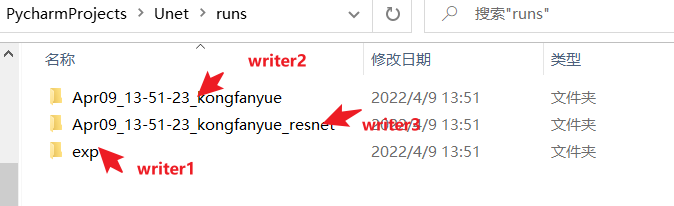
使用的时候,创建一个 SummaryWriter 对象即可,以上展示了三种初始化 SummaryWriter 的方法:
- 提供一个路径,将使用该路径来保存日志
- 无参数,默认将使用 runs/日期_用户名 路径来保存日志
- 提供一个 comment 参数,将使用 runs/日期_用户名+comment 路径来保存日志
运行结果:
有了 writer 我们就可以往日志里写入数字、图片、甚至声音等数据。
- 数字(scalar)
这个是最简单的,使用 add_scalar 方法来记录数字常量。
|
|
总共 4 个参数。
- tag (string): 数据名称,不同名称的数据使用不同曲线展示
- scalar_value (float): 数字常量值
- global_step (int, optional): 训练的 step
- walltime (float, optional): 记录发生的时间,默认为 time.time()
需要注意,这里的 scalar_value 一定是 float 类型,如果是 PyTorch scalar tensor,则需要调用 .item() 方法获取其数值。我们一般会使用 add_scalar 方法来记录训练过程的 loss、accuracy、learning rate 等数值的变化,直观地监控训练过程。
|
|
通过 add_scalar 往日志里写入数字,日志保存到 runs/scalar_example中,writer 用完要记得 close,否则无法保存数据。
在 cmd 中使用如下命令:
|
|
指定日志地址,使用端口号,在浏览器中,就可以使用如下地址,打开 Tensorboad。
|
|
不…太…行…
Author kong
LastMod 2022-04-07